 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2021 Challenge on Quality Enhancement of Compressed Video: Methods and Results
May 02, 2021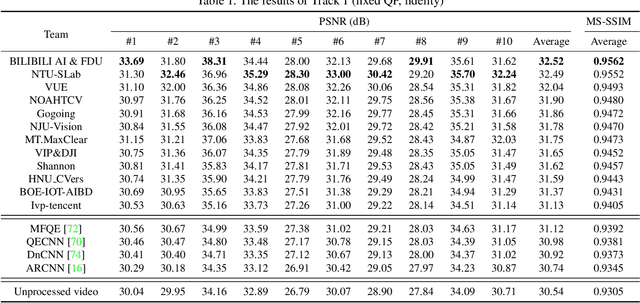
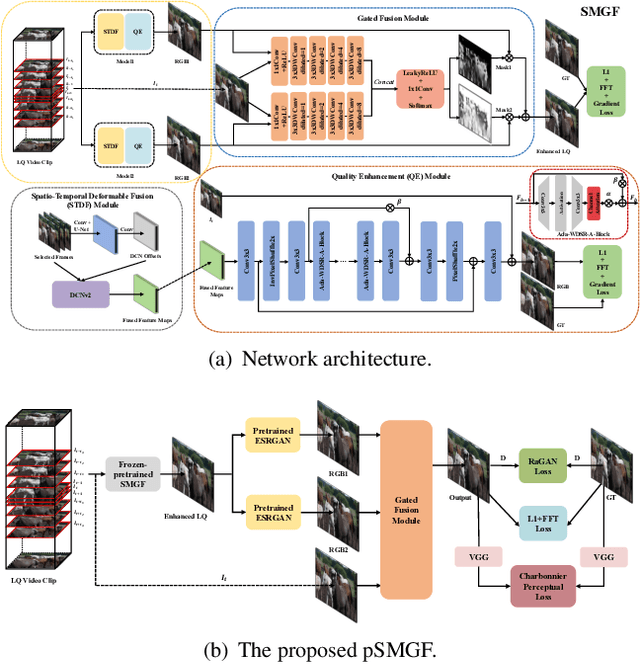
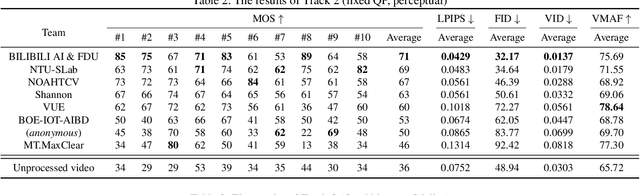
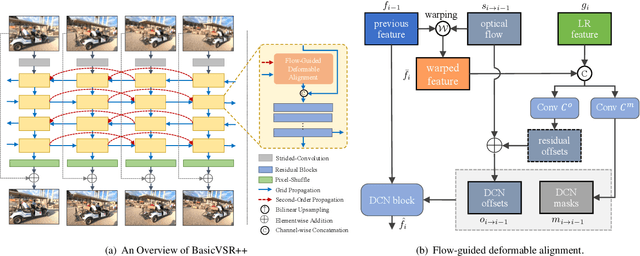
This paper reviews the first NTIRE challenge on quality enhancement of compressed video, with a focus on the proposed methods and results. In this challenge, the new Large-scale Diverse Video (LDV) dataset is employed. The challenge has three tracks. Tracks 1 and 2 aim at enhancing the videos compressed by HEVC at a fixed QP, while Track 3 is designed for enhancing the videos compressed by x265 at a fixed bit-rate. Besides, the quality enhancement of Tracks 1 and 3 targets at improving the fidelity (PSNR), and Track 2 targets at enhancing the perceptual quality. The three tracks totally attract 482 registrations. In the test phase, 12 teams, 8 teams and 11 teams submitted the final results of Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of video quality enhancement. The homepage of the challenge: https://github.com/RenYang-home/NTIRE21_VEnh
PAFNet: An Efficient Anchor-Free Object Detector Guidance
Apr 28, 2021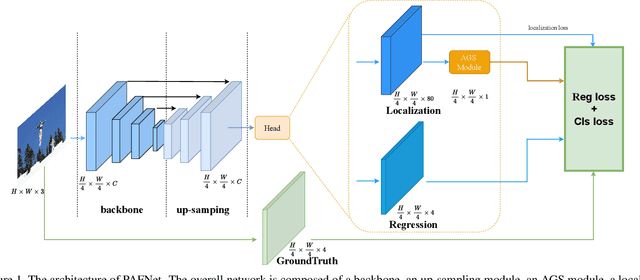
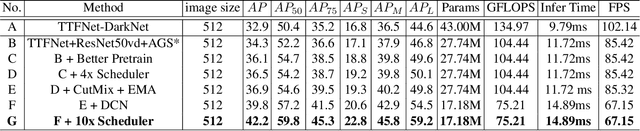
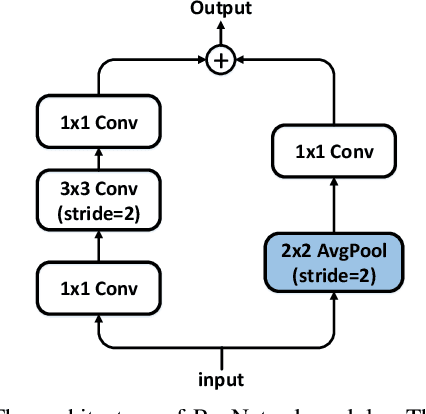

Object detection is a basic but challenging task in computer vision, which plays a key role in a variety of industrial applications. However, object detectors based on deep learning usually require greater storage requirements and longer inference time, which hinders its practicality seriously. Therefore, a trade-off between effectiveness and efficiency is necessary in practical scenarios. Considering that without constraint of pre-defined anchors, anchor-free detectors can achieve acceptable accuracy and inference speed simultaneously. In this paper, we start from an anchor-free detector called TTFNet, modify the structure of TTFNet and introduce multiple existing tricks to realize effective server and mobile solutions respectively. Since all experiments in this paper are conducted based on PaddlePaddle, we call the model as PAFNet(Paddle Anchor Free Network). For server side, PAFNet can achieve a better balance between effectiveness (42.2% mAP) and efficiency (67.15 FPS) on a single V100 GPU. For moblie side, PAFNet-lite can achieve a better accuracy of (23.9% mAP) and 26.00 ms on Kirin 990 ARM CPU, outperforming the existing state-of-the-art anchor-free detectors by significant margins. Source code is at https://github.com/PaddlePaddle/PaddleDetection.
PP-YOLOv2: A Practical Object Detector
Apr 21, 2021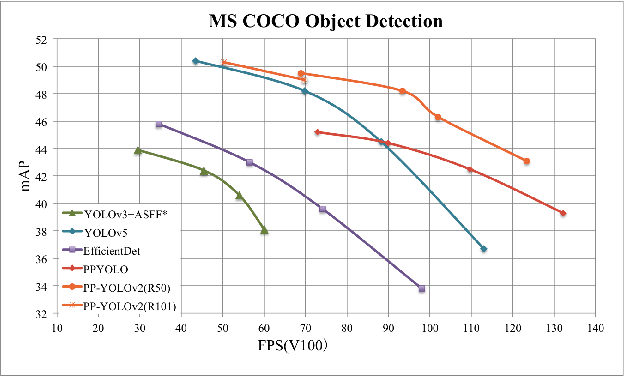

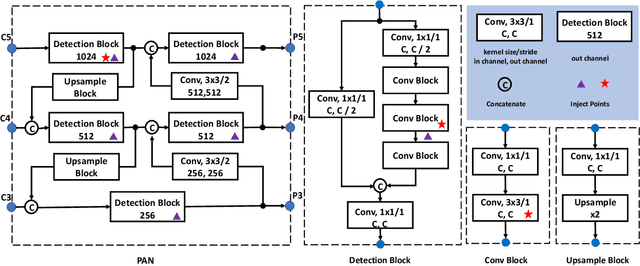
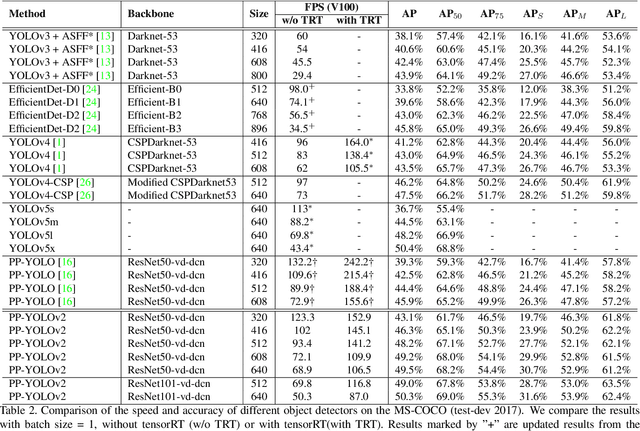
Being effective and efficient is essential to an object detector for practical use. To meet these two concerns, we comprehensively evaluate a collection of existing refinements to improve the performance of PP-YOLO while almost keep the infer time unchanged. This paper will analyze a collection of refinements and empirically evaluate their impact on the final model performance through incremental ablation study. Things we tried that didn't work will also be discussed. By combining multiple effective refinements, we boost PP-YOLO's performance from 45.9% mAP to 49.5% mAP on COCO2017 test-dev. Since a significant margin of performance has been made, we present PP-YOLOv2. In terms of speed, PP-YOLOv2 runs in 68.9FPS at 640x640 input size. Paddle inference engine with TensorRT, FP16-precision, and batch size = 1 further improves PP-YOLOv2's infer speed, which achieves 106.5 FPS. Such a performance surpasses existing object detectors with roughly the same amount of parameters (i.e., YOLOv4-CSP, YOLOv5l). Besides, PP-YOLOv2 with ResNet101 achieves 50.3% mAP on COCO2017 test-dev. Source code is at https://github.com/PaddlePaddle/PaddleDetection.
PP-OCR: A Practical Ultra Lightweight OCR System
Oct 15, 2020

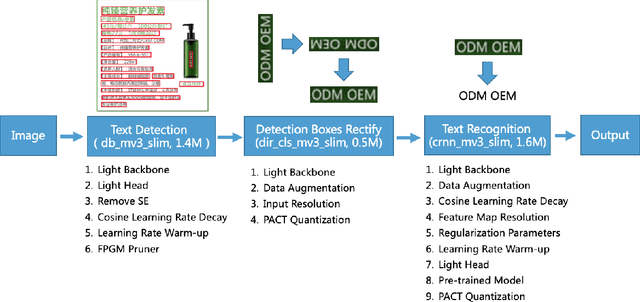
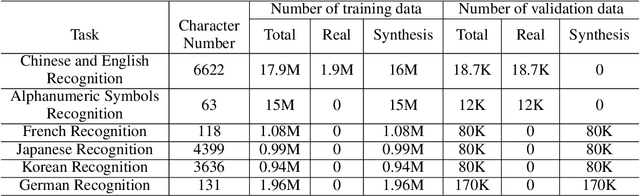
The Optical Character Recognition (OCR) systems have been widely used in various of application scenarios, such as office automation (OA) systems, factory automations, online educations, map productions etc. However, OCR is still a challenging task due to the various of text appearances and the demand of computational efficiency. In this paper, we propose a practical ultra lightweight OCR system, i.e., PP-OCR. The overall model size of the PP-OCR is only 3.5M for recognizing 6622 Chinese characters and 2.8M for recognizing 63 alphanumeric symbols, respectively. We introduce a bag of strategies to either enhance the model ability or reduce the model size. The corresponding ablation experiments with the real data are also provided. Meanwhile, several pre-trained models for the Chinese and English recognition are released, including a text detector (97K images are used), a direction classifier (600K images are used) as well as a text recognizer (17.9M images are used). Besides, the proposed PP-OCR are also verified in several other language recognition tasks, including French, Korean, Japanese and German. All of the above mentioned models are open-sourced and the codes are available in the GitHub repository, i.e., https://github.com/PaddlePaddle/PaddleOCR.
PP-YOLO: An Effective and Efficient Implementation of Object Detector
Aug 03, 2020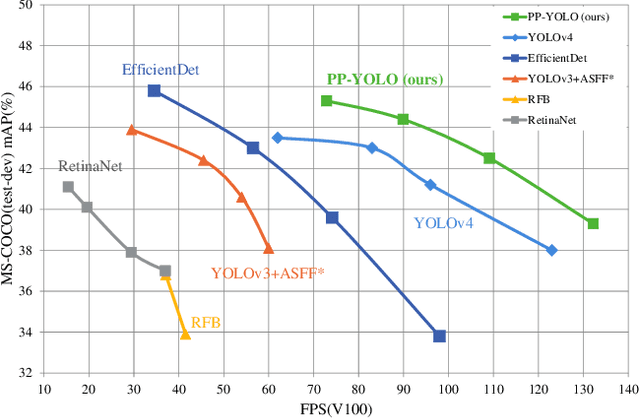
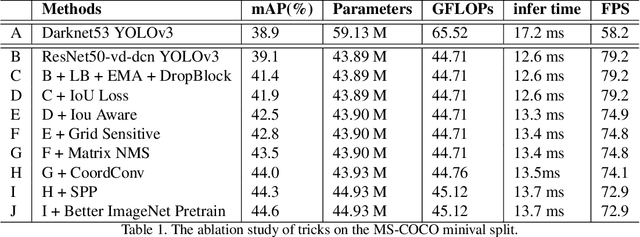
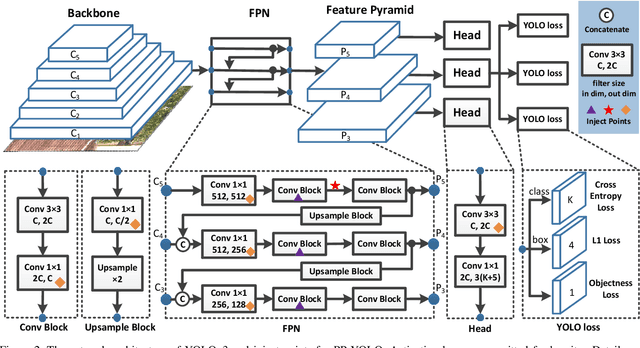
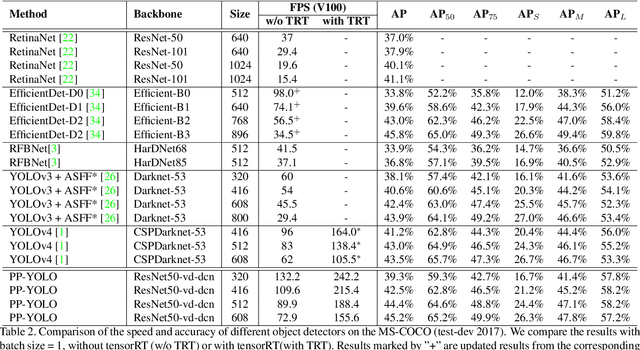
Object detection is one of the most important areas in computer vision, which plays a key role in various practical scenarios. Due to limitation of hardware, it is often necessary to sacrifice accuracy to ensure the infer speed of the detector in practice. Therefore, the balance between effectiveness and efficiency of object detector must be considered. The goal of this paper is to implement an object detector with relatively balanced effectiveness and efficiency that can be directly applied in actual application scenarios, rather than propose a novel detection model. Considering that YOLOv3 has been widely used in practice, we develop a new object detector based on YOLOv3. We mainly try to combine various existing tricks that almost not increase the number of model parameters and FLOPs, to achieve the goal of improving the accuracy of detector as much as possible while ensuring that the speed is almost unchanged. Since all experiments in this paper are conducted based on PaddlePaddle, we call it PP-YOLO. By combining multiple tricks, PP-YOLO can achieve a better balance between effectiveness (45.2% mAP) and efficiency (72.9 FPS), surpassing the existing state-of-the-art detectors such as EfficientDet and YOLOv4.Source code is at https://github.com/PaddlePaddle/PaddleDetection.
Deep Image: Scaling up Image Recognition
Jul 06, 2015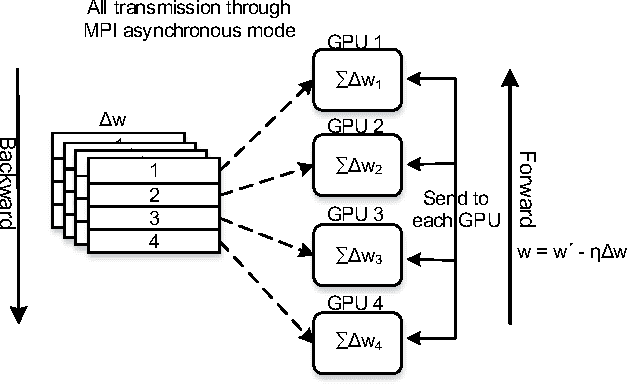
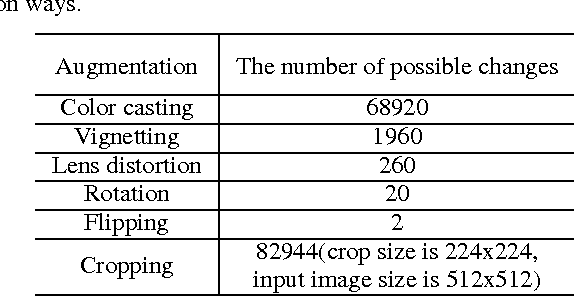
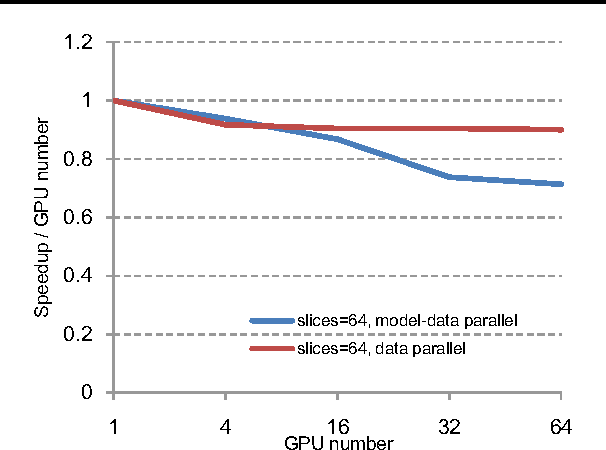
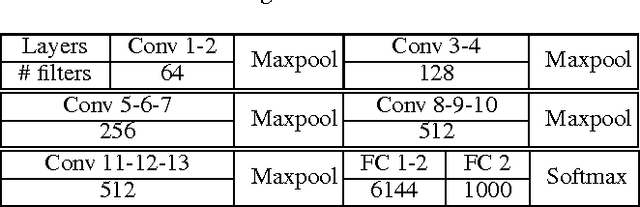
We present a state-of-the-art image recognition system, Deep Image, developed using end-to-end deep learning. The key components are a custom-built supercomputer dedicated to deep learning, a highly optimized parallel algorithm using new strategies for data partitioning and communication, larger deep neural network models, novel data augmentation approaches, and usage of multi-scale high-resolution images. Our method achieves excellent results on multiple challenging computer vision benchmarks.