 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel-Level Relation to Attentive Aggregation with Neighborhood-Homogeneity Constraint for Point Cloud Analysis
May 04, 2026In 3D point cloud understanding, the core challenge lies in accurately capturing discriminative features within complex neighborhoods, which directly affects the execution precision of downstream tasks such as embodied AI and autonomous driving. Existing methods explore feature correlation discrimination but are limited to point-level spatial distribution or channel responses, enabling only coarse-grained level evaluation. For modern multi-scale point cloud networks, such coarse-grained metrics inevitably incur significant information loss in deeper layers. To address this issue, we propose a novel network equipped with a channel-level metric-based enhancement mechanism, termed the PointCRA network. Our core idea is to introduce temporal trend variation as a new evaluation dimension to avoid the information loss caused by weight dimension collapse in existing spatial and channel attention mechanisms. On this basis, we construct a multi-level calibration framework guided by neighborhood homogeneity for weight calibration, and design a dedicated loss function to enhance channel discriminability. The module effectively leverages the intrinsic feature priors of deep networks to adaptively correct the feature aggregation process, offering strong interpretability with low parameter overhead. Furthermore, our proposed method exhibits strong transferability, interpretability, and parameter efficiency. We validate the proposed method effectiveness on diverse datasets and benchmark models, and further demonstrate its rationality through extensive analytical experiments. Our PointCRA achieves 77.5% mIoU on the S3DIS dataset, 90.4% OA on the ScanObjectNN dataset, and 87.4% instance mIoU on the ShapeNetPart dataset. The code and pretrained weights are publicly available on GitHub:
Enhancing point cloud analysis via neighbor aggregation correction based on cross-stage structure correlation
Jun 18, 2025Point cloud analysis is the cornerstone of many downstream tasks, among which aggregating local structures is the basis for understanding point cloud data. While numerous works aggregate neighbor using three-dimensional relative coordinates, there are irrelevant point interference and feature hierarchy gap problems due to the limitation of local coordinates. Although some works address this limitation by refining spatial description though explicit modeling of cross-stage structure, these enhancement methods based on direct geometric structure encoding have problems of high computational overhead and noise sensitivity. To overcome these problems, we propose the Point Distribution Set Abstraction module (PDSA) that utilizes the correlation in the high-dimensional space to correct the feature distribution during aggregation, which improves the computational efficiency and robustness. PDSA distinguishes the point correlation based on a lightweight cross-stage structural descriptor, and enhances structural homogeneity by reducing the variance of the neighbor feature matrix and increasing classes separability though long-distance modeling. Additionally, we introducing a key point mechanism to optimize the computational overhead. The experimental result on semantic segmentation and classification tasks based on different baselines verify the generalization of the method we proposed, and achieve significant performance improvement with less parameter cost. The corresponding ablation and visualization results demonstrate the effectiveness and rationality of our method. The code and training weight is available at: https://github.com/AGENT9717/PointDistribution
ICDAR 2023 Competition on Structured Text Extraction from Visually-Rich Document Images
Jun 05, 2023Structured text extraction is one of the most valuable and challenging application directions in the field of Document AI. However, the scenarios of past benchmarks are limited, and the corresponding evaluation protocols usually focus on the submodules of the structured text extraction scheme. In order to eliminate these problems, we organized the ICDAR 2023 competition on Structured text extraction from Visually-Rich Document images (SVRD). We set up two tracks for SVRD including Track 1: HUST-CELL and Track 2: Baidu-FEST, where HUST-CELL aims to evaluate the end-to-end performance of Complex Entity Linking and Labeling, and Baidu-FEST focuses on evaluating the performance and generalization of Zero-shot / Few-shot Structured Text extraction from an end-to-end perspective. Compared to the current document benchmarks, our two tracks of competition benchmark enriches the scenarios greatly and contains more than 50 types of visually-rich document images (mainly from the actual enterprise applications). The competition opened on 30th December, 2022 and closed on 24th March, 2023. There are 35 participants and 91 valid submissions received for Track 1, and 15 participants and 26 valid submissions received for Track 2. In this report we will presents the motivation, competition datasets, task definition, evaluation protocol, and submission summaries. According to the performance of the submissions, we believe there is still a large gap on the expected information extraction performance for complex and zero-shot scenarios. It is hoped that this competition will attract many researchers in the field of CV and NLP, and bring some new thoughts to the field of Document AI.
A bioinspired three-stage model for camouflaged object detection
May 22, 2023Camouflaged objects are typically assimilated into their backgrounds and exhibit fuzzy boundaries. The complex environmental conditions and the high intrinsic similarity between camouflaged targets and their surroundings pose significant challenges in accurately locating and segmenting these objects in their entirety. While existing methods have demonstrated remarkable performance in various real-world scenarios, they still face limitations when confronted with difficult cases, such as small targets, thin structures, and indistinct boundaries. Drawing inspiration from human visual perception when observing images containing camouflaged objects, we propose a three-stage model that enables coarse-to-fine segmentation in a single iteration. Specifically, our model employs three decoders to sequentially process subsampled features, cropped features, and high-resolution original features. This proposed approach not only reduces computational overhead but also mitigates interference caused by background noise. Furthermore, considering the significance of multi-scale information, we have designed a multi-scale feature enhancement module that enlarges the receptive field while preserving detailed structural cues. Additionally, a boundary enhancement module has been developed to enhance performance by leveraging boundary information. Subsequently, a mask-guided fusion module is proposed to generate fine-grained results by integrating coarse prediction maps with high-resolution feature maps. Our network surpasses state-of-the-art CNN-based counterparts without unnecessary complexities. Upon acceptance of the paper, the source code will be made publicly available at https://github.com/clelouch/BTSNet.
PP-YOLOE-R: An Efficient Anchor-Free Rotated Object Detector
Nov 04, 2022



Arbitrary-oriented object detection is a fundamental task in visual scenes involving aerial images and scene text. In this report, we present PP-YOLOE-R, an efficient anchor-free rotated object detector based on PP-YOLOE. We introduce a bag of useful tricks in PP-YOLOE-R to improve detection precision with marginal extra parameters and computational cost. As a result, PP-YOLOE-R-l and PP-YOLOE-R-x achieve 78.14 and 78.28 mAP respectively on DOTA 1.0 dataset with single-scale training and testing, which outperform almost all other rotated object detectors. With multi-scale training and testing, PP-YOLOE-R-l and PP-YOLOE-R-x further improve the detection precision to 80.02 and 80.73 mAP. In this case, PP-YOLOE-R-x surpasses all anchor-free methods and demonstrates competitive performance to state-of-the-art anchor-based two-stage models. Further, PP-YOLOE-R is deployment friendly and PP-YOLOE-R-s/m/l/x can reach 69.8/55.1/48.3/37.1 FPS respectively on RTX 2080 Ti with TensorRT and FP16-precision. Source code and pre-trained models are available at https://github.com/PaddlePaddle/PaddleDetection, which is powered by https://github.com/PaddlePaddle/Paddle.
PP-StructureV2: A Stronger Document Analysis System
Oct 11, 2022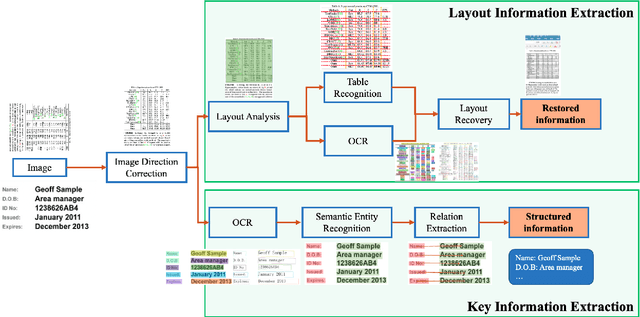



A large amount of document data exists in unstructured form such as raw images without any text information. Designing a practical document image analysis system is a meaningful but challenging task. In previous work, we proposed an intelligent document analysis system PP-Structure. In order to further upgrade the function and performance of PP-Structure, we propose PP-StructureV2 in this work, which contains two subsystems: Layout Information Extraction and Key Information Extraction. Firstly, we integrate Image Direction Correction module and Layout Restoration module to enhance the functionality of the system. Secondly, 8 practical strategies are utilized in PP-StructureV2 for better performance. For Layout Analysis model, we introduce ultra light-weight detector PP-PicoDet and knowledge distillation algorithm FGD for model lightweighting, which increased the inference speed by 11 times with comparable mAP. For Table Recognition model, we utilize PP-LCNet, CSP-PAN and SLAHead to optimize the backbone module, feature fusion module and decoding module, respectively, which improved the table structure accuracy by 6\% with comparable inference speed. For Key Information Extraction model, we introduce VI-LayoutXLM which is a visual-feature independent LayoutXLM architecture, TB-YX sorting algorithm and U-DML knowledge distillation algorithm, which brought 2.8\% and 9.1\% improvement respectively on the Hmean of Semantic Entity Recognition and Relation Extraction tasks. All the above mentioned models and code are open-sourced in the GitHub repository PaddleOCR.
PP-OCRv3: More Attempts for the Improvement of Ultra Lightweight OCR System
Jun 07, 2022

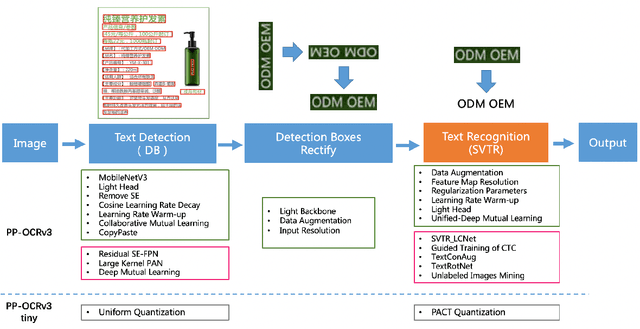
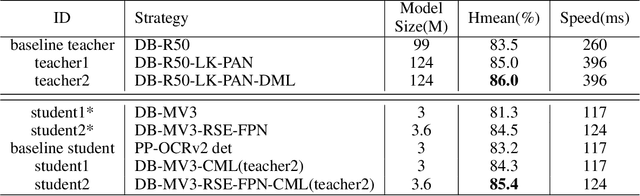
Optical character recognition (OCR) technology has been widely used in various scenes, as shown in Figure 1. Designing a practical OCR system is still a meaningful but challenging task. In previous work, considering the efficiency and accuracy, we proposed a practical ultra lightweight OCR system (PP-OCR), and an optimized version PP-OCRv2. In order to further improve the performance of PP-OCRv2, a more robust OCR system PP-OCRv3 is proposed in this paper. PP-OCRv3 upgrades the text detection model and text recognition model in 9 aspects based on PP-OCRv2. For text detector, we introduce a PAN module with large receptive field named LK-PAN, a FPN module with residual attention mechanism named RSE-FPN, and DML distillation strategy. For text recognizer, the base model is replaced from CRNN to SVTR, and we introduce lightweight text recognition network SVTR LCNet, guided training of CTC by attention, data augmentation strategy TextConAug, better pre-trained model by self-supervised TextRotNet, UDML, and UIM to accelerate the model and improve the effect. Experiments on real data show that the hmean of PP-OCRv3 is 5% higher than PP-OCRv2 under comparable inference speed. All the above mentioned models are open-sourced and the code is available in the GitHub repository PaddleOCR which is powered by PaddlePaddle.
PaddleSpeech: An Easy-to-Use All-in-One Speech Toolkit
May 20, 2022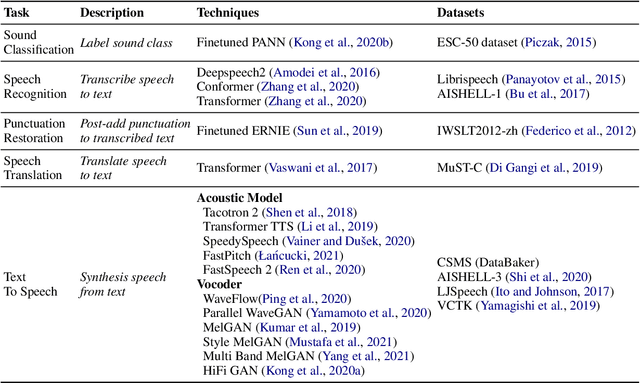
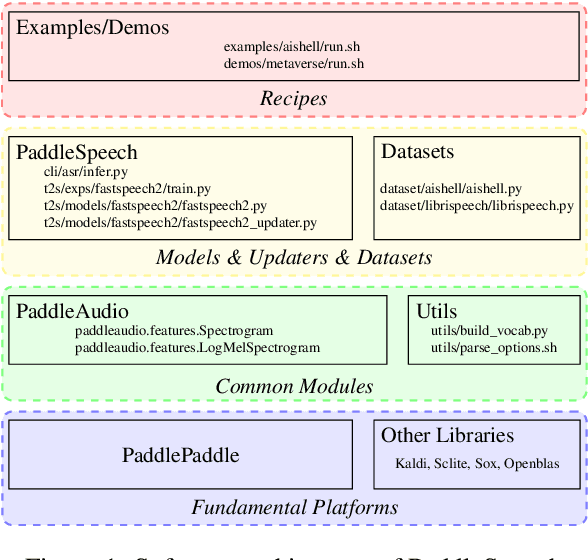
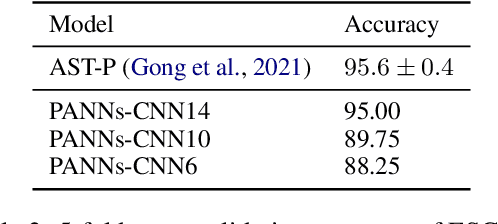
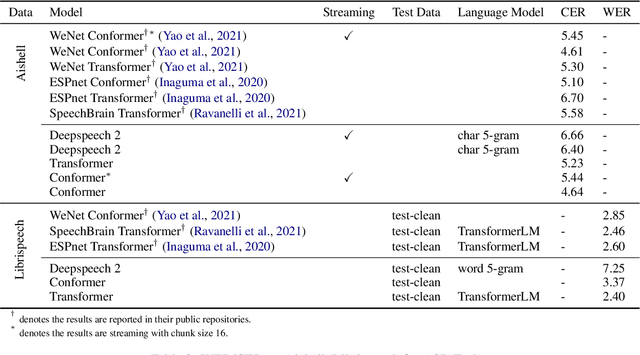
PaddleSpeech is an open-source all-in-one speech toolkit. It aims at facilitating the development and research of speech processing technologies by providing an easy-to-use command-line interface and a simple code structure. This paper describes the design philosophy and core architecture of PaddleSpeech to support several essential speech-to-text and text-to-speech tasks. PaddleSpeech achieves competitive or state-of-the-art performance on various speech datasets and implements the most popular methods. It also provides recipes and pretrained models to quickly reproduce the experimental results in this paper. PaddleSpeech is publicly avaiable at https://github.com/PaddlePaddle/PaddleSpeech.
PP-Matting: High-Accuracy Natural Image Matting
Apr 20, 2022
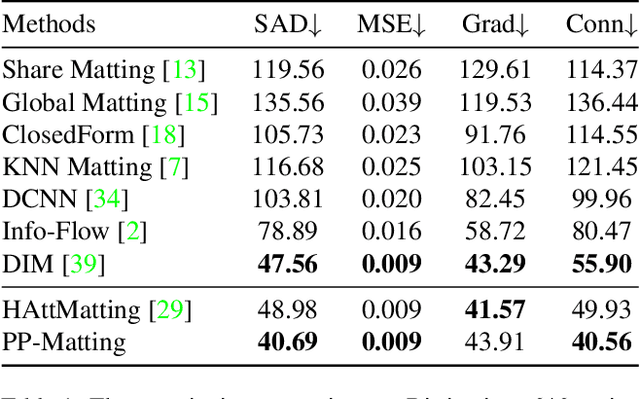
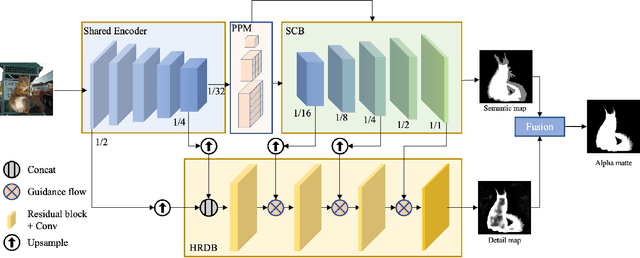
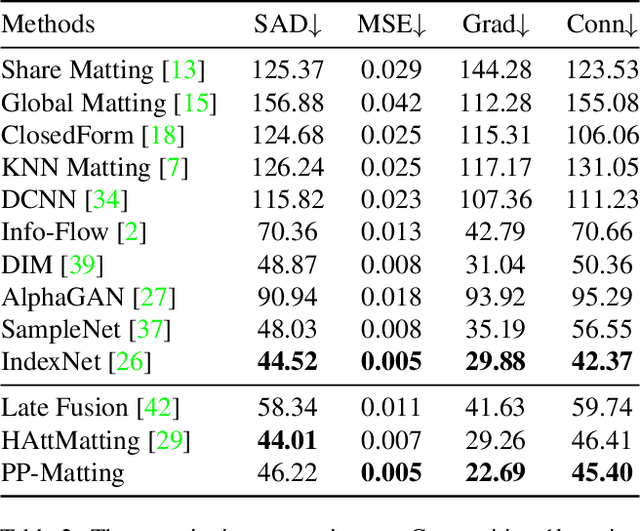
Natural image matting is a fundamental and challenging computer vision task. It has many applications in image editing and composition. Recently, deep learning-based approaches have achieved great improvements in image matting. However, most of them require a user-supplied trimap as an auxiliary input, which limits the matting applications in the real world. Although some trimap-free approaches have been proposed, the matting quality is still unsatisfactory compared to trimap-based ones. Without the trimap guidance, the matting models suffer from foreground-background ambiguity easily, and also generate blurry details in the transition area. In this work, we propose PP-Matting, a trimap-free architecture that can achieve high-accuracy natural image matting. Our method applies a high-resolution detail branch (HRDB) that extracts fine-grained details of the foreground with keeping feature resolution unchanged. Also, we propose a semantic context branch (SCB) that adopts a semantic segmentation subtask. It prevents the detail prediction from local ambiguity caused by semantic context missing. In addition, we conduct extensive experiments on two well-known benchmarks: Composition-1k and Distinctions-646. The results demonstrate the superiority of PP-Matting over previous methods. Furthermore, we provide a qualitative evaluation of our method on human matting which shows its outstanding performance in the practical application. The code and pre-trained models will be available at PaddleSeg: https://github.com/PaddlePaddle/PaddleSeg.
PP-LiteSeg: A Superior Real-Time Semantic Segmentation Model
Apr 06, 2022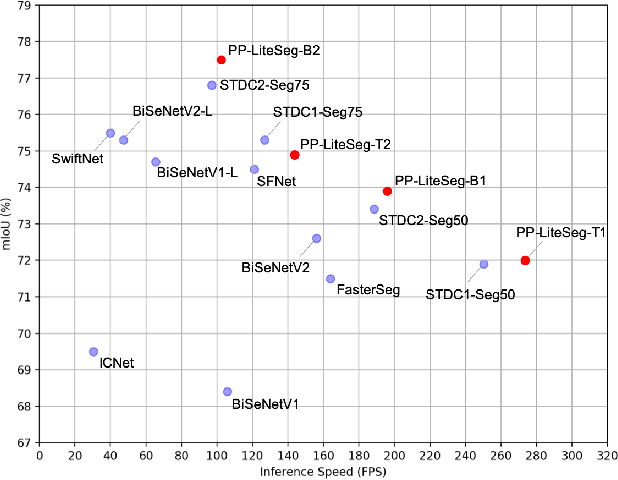

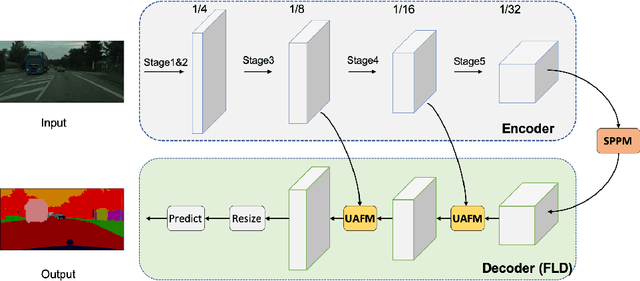
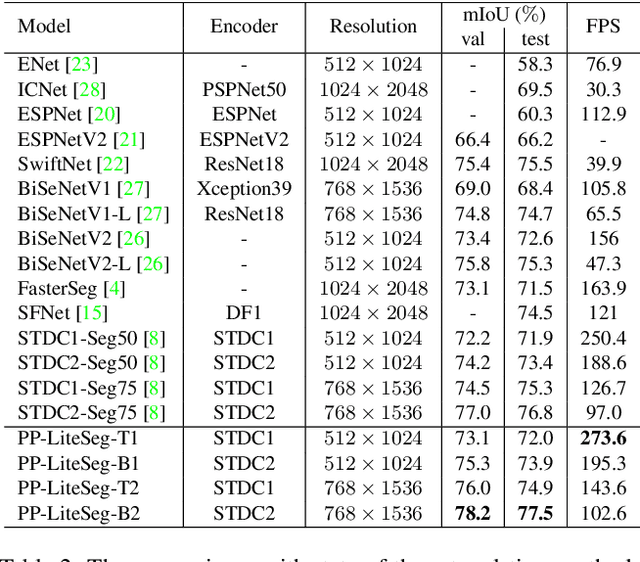
Real-world applications have high demands for semantic segmentation methods. Although semantic segmentation has made remarkable leap-forwards with deep learning, the performance of real-time methods is not satisfactory. In this work, we propose PP-LiteSeg, a novel lightweight model for the real-time semantic segmentation task. Specifically, we present a Flexible and Lightweight Decoder (FLD) to reduce computation overhead of previous decoder. To strengthen feature representations, we propose a Unified Attention Fusion Module (UAFM), which takes advantage of spatial and channel attention to produce a weight and then fuses the input features with the weight. Moreover, a Simple Pyramid Pooling Module (SPPM) is proposed to aggregate global context with low computation cost. Extensive evaluations demonstrate that PP-LiteSeg achieves a superior trade-off between accuracy and speed compared to other methods. On the Cityscapes test set, PP-LiteSeg achieves 72.0% mIoU/273.6 FPS and 77.5% mIoU/102.6 FPS on NVIDIA GTX 1080Ti. Source code and models are available at PaddleSeg: https://github.com/PaddlePaddle/PaddleSeg.