 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBitSnap: Checkpoint Sparsification and Quantization in LLM Training
Nov 18, 2025As large language models (LLMs) continue to grow in size and complexity, efficient checkpoint saving\&loading has become crucial for managing storage, memory usage, and fault tolerance in LLM training. The current works do not comprehensively take into account the optimization of these several aspects. This paper proposes a novel checkpoint sparsification and quantization method that adapts dynamically to different training stages and model architectures. We present a comprehensive analysis of existing lossy and lossless compression techniques, identify current limitations, and introduce our adaptive approach that balances compression ratio, speed, and precision impact throughout the training process. Experiments on different sizes of LLMs demonstrate that our bitmask-based sparsification method achieves 16x compression ratio without compromising model accuracy. Additionally, the cluster-based quantization method achieves 2x compression ratio with little precision loss.
R2R: Efficiently Navigating Divergent Reasoning Paths with Small-Large Model Token Routing
May 27, 2025Large Language Models (LLMs) achieve impressive reasoning capabilities at the cost of substantial inference overhead, posing substantial deployment challenges. Although distilled Small Language Models (SLMs) significantly enhance efficiency, their performance suffers as they fail to follow LLMs' reasoning paths. Luckily, we reveal that only a small fraction of tokens genuinely diverge reasoning paths between LLMs and SLMs. Most generated tokens are either identical or exhibit neutral differences, such as minor variations in abbreviations or expressions. Leveraging this insight, we introduce **Roads to Rome (R2R)**, a neural token routing method that selectively utilizes LLMs only for these critical, path-divergent tokens, while leaving the majority of token generation to the SLM. We also develop an automatic data generation pipeline that identifies divergent tokens and generates token-level routing labels to train the lightweight router. We apply R2R to combine R1-1.5B and R1-32B models from the DeepSeek family, and evaluate on challenging math, coding, and QA benchmarks. With an average activated parameter size of 5.6B, R2R surpasses the average accuracy of R1-7B by 1.6x, outperforming even the R1-14B model. Compared to R1-32B, it delivers a 2.8x wall-clock speedup with comparable performance, advancing the Pareto frontier of test-time scaling efficiency. Our code is available at https://github.com/thu-nics/R2R.
PM-KVQ: Progressive Mixed-precision KV Cache Quantization for Long-CoT LLMs
May 24, 2025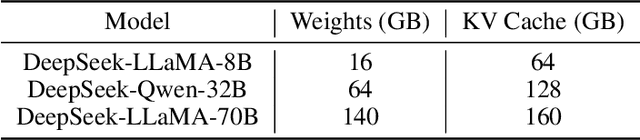
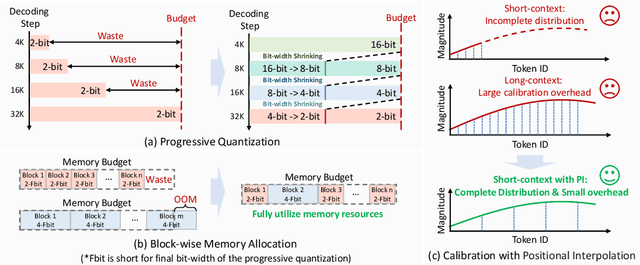


Recently, significant progress has been made in developing reasoning-capable Large Language Models (LLMs) through long Chain-of-Thought (CoT) techniques. However, this long-CoT reasoning process imposes substantial memory overhead due to the large Key-Value (KV) Cache memory overhead. Post-training KV Cache quantization has emerged as a promising compression technique and has been extensively studied in short-context scenarios. However, directly applying existing methods to long-CoT LLMs causes significant performance degradation due to the following two reasons: (1) Large cumulative error: Existing methods fail to adequately leverage available memory, and they directly quantize the KV Cache during each decoding step, leading to large cumulative quantization error. (2) Short-context calibration: Due to Rotary Positional Embedding (RoPE), the use of short-context data during calibration fails to account for the distribution of less frequent channels in the Key Cache, resulting in performance loss. We propose Progressive Mixed-Precision KV Cache Quantization (PM-KVQ) for long-CoT LLMs to address the above issues in two folds: (1) To reduce cumulative error, we design a progressive quantization strategy to gradually lower the bit-width of KV Cache in each block. Then, we propose block-wise memory allocation to assign a higher bit-width to more sensitive transformer blocks. (2) To increase the calibration length without additional overhead, we propose a new calibration strategy with positional interpolation that leverages short calibration data with positional interpolation to approximate the data distribution of long-context data. Extensive experiments on 7B-70B long-CoT LLMs show that PM-KVQ improves reasoning benchmark performance by up to 8% over SOTA baselines under the same memory budget. Our code is available at https://github.com/thu-nics/PM-KVQ.
VGDFR: Diffusion-based Video Generation with Dynamic Latent Frame Rate
Apr 16, 2025



Diffusion Transformer(DiT)-based generation models have achieved remarkable success in video generation. However, their inherent computational demands pose significant efficiency challenges. In this paper, we exploit the inherent temporal non-uniformity of real-world videos and observe that videos exhibit dynamic information density, with high-motion segments demanding greater detail preservation than static scenes. Inspired by this temporal non-uniformity, we propose VGDFR, a training-free approach for Diffusion-based Video Generation with Dynamic Latent Frame Rate. VGDFR adaptively adjusts the number of elements in latent space based on the motion frequency of the latent space content, using fewer tokens for low-frequency segments while preserving detail in high-frequency segments. Specifically, our key contributions are: (1) A dynamic frame rate scheduler for DiT video generation that adaptively assigns frame rates for video segments. (2) A novel latent-space frame merging method to align latent representations with their denoised counterparts before merging those redundant in low-resolution space. (3) A preference analysis of Rotary Positional Embeddings (RoPE) across DiT layers, informing a tailored RoPE strategy optimized for semantic and local information capture. Experiments show that VGDFR can achieve a speedup up to 3x for video generation with minimal quality degradation.
DiTFastAttnV2: Head-wise Attention Compression for Multi-Modality Diffusion Transformers
Mar 28, 2025
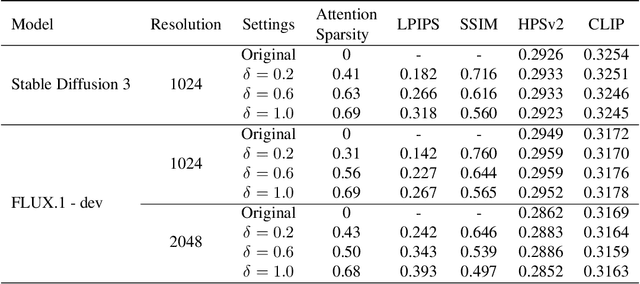
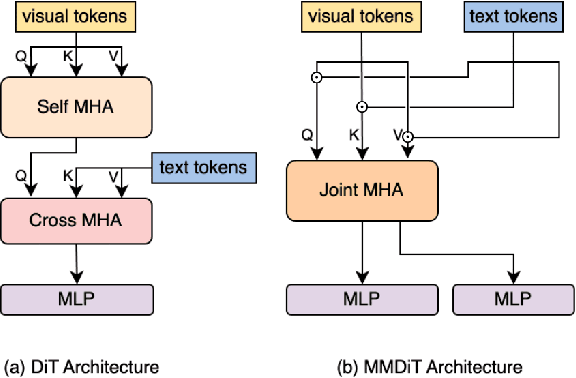
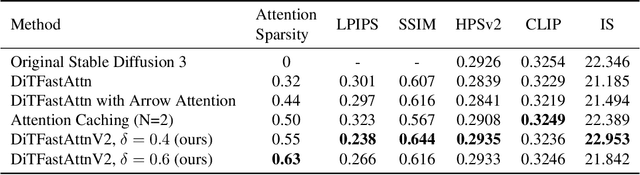
Text-to-image generation models, especially Multimodal Diffusion Transformers (MMDiT), have shown remarkable progress in generating high-quality images. However, these models often face significant computational bottlenecks, particularly in attention mechanisms, which hinder their scalability and efficiency. In this paper, we introduce DiTFastAttnV2, a post-training compression method designed to accelerate attention in MMDiT. Through an in-depth analysis of MMDiT's attention patterns, we identify key differences from prior DiT-based methods and propose head-wise arrow attention and caching mechanisms to dynamically adjust attention heads, effectively bridging this gap. We also design an Efficient Fused Kernel for further acceleration. By leveraging local metric methods and optimization techniques, our approach significantly reduces the search time for optimal compression schemes to just minutes while maintaining generation quality. Furthermore, with the customized kernel, DiTFastAttnV2 achieves a 68% reduction in attention FLOPs and 1.5x end-to-end speedup on 2K image generation without compromising visual fidelity.
AgentSociety Challenge: Designing LLM Agents for User Modeling and Recommendation on Web Platforms
Feb 26, 2025The AgentSociety Challenge is the first competition in the Web Conference that aims to explore the potential of Large Language Model (LLM) agents in modeling user behavior and enhancing recommender systems on web platforms. The Challenge consists of two tracks: the User Modeling Track and the Recommendation Track. Participants are tasked to utilize a combined dataset from Yelp, Amazon, and Goodreads, along with an interactive environment simulator, to develop innovative LLM agents. The Challenge has attracted 295 teams across the globe and received over 1,400 submissions in total over the course of 37 official competition days. The participants have achieved 21.9% and 20.3% performance improvement for Track 1 and Track 2 in the Development Phase, and 9.1% and 15.9% in the Final Phase, representing a significant accomplishment. This paper discusses the detailed designs of the Challenge, analyzes the outcomes, and highlights the most successful LLM agent designs. To support further research and development, we have open-sourced the benchmark environment at https://tsinghua-fib-lab.github.io/AgentSocietyChallenge.
Megrez-Omni Technical Report
Feb 19, 2025
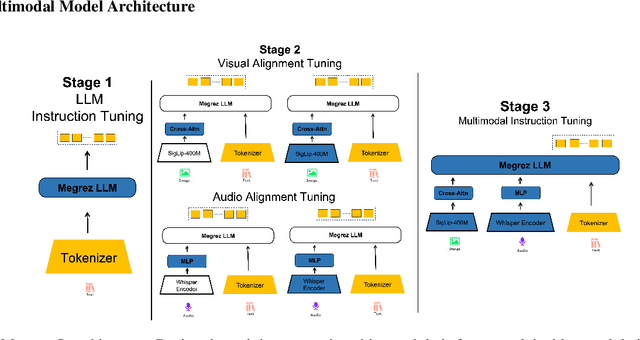


In this work, we present the Megrez models, comprising a language model (Megrez-3B-Instruct) and a multimodal model (Megrez-3B-Omni). These models are designed to deliver fast inference, compactness, and robust edge-side intelligence through a software-hardware co-design approach. Megrez-3B-Instruct offers several advantages, including high accuracy, high speed, ease of use, and a wide range of applications. Building on Megrez-3B-Instruct, Megrez-3B-Omni is an on-device multimodal understanding LLM that supports image, text, and audio analysis. It achieves state-of-the-art accuracy across all three modalities and demonstrates strong versatility and robustness, setting a new benchmark for multimodal AI models.
DLFR-VAE: Dynamic Latent Frame Rate VAE for Video Generation
Feb 17, 2025



In this paper, we propose the Dynamic Latent Frame Rate VAE (DLFR-VAE), a training-free paradigm that can make use of adaptive temporal compression in latent space. While existing video generative models apply fixed compression rates via pretrained VAE, we observe that real-world video content exhibits substantial temporal non-uniformity, with high-motion segments containing more information than static scenes. Based on this insight, DLFR-VAE dynamically adjusts the latent frame rate according to the content complexity. Specifically, DLFR-VAE comprises two core innovations: (1) A Dynamic Latent Frame Rate Scheduler that partitions videos into temporal chunks and adaptively determines optimal frame rates based on information-theoretic content complexity, and (2) A training-free adaptation mechanism that transforms pretrained VAE architectures into a dynamic VAE that can process features with variable frame rates. Our simple but effective DLFR-VAE can function as a plug-and-play module, seamlessly integrating with existing video generation models and accelerating the video generation process.
FrameFusion: Combining Similarity and Importance for Video Token Reduction on Large Visual Language Models
Dec 30, 2024
The increasing demand to process long and high-resolution videos significantly burdens Large Vision-Language Models (LVLMs) due to the enormous number of visual tokens. Existing token reduction methods primarily focus on importance-based token pruning, which overlooks the redundancy caused by frame resemblance and repetitive visual elements. In this paper, we analyze the high vision token similarities in LVLMs. We reveal that token similarity distribution condenses as layers deepen while maintaining ranking consistency. Leveraging the unique properties of similarity over importance, we introduce FrameFusion, a novel approach that combines similarity-based merging with importance-based pruning for better token reduction in LVLMs. FrameFusion identifies and merges similar tokens before pruning, opening up a new perspective for token reduction. We evaluate FrameFusion on diverse LVLMs, including Llava-Video-{7B,32B,72B}, and MiniCPM-V-8B, on video understanding, question-answering, and retrieval benchmarks. Experiments show that FrameFusion reduces vision tokens by 70$\%$, achieving 3.4-4.4x LLM speedups and 1.6-1.9x end-to-end speedups, with an average performance impact of less than 3$\%$. Our code is available at https://github.com/thu-nics/FrameFusion.
MBQ: Modality-Balanced Quantization for Large Vision-Language Models
Dec 27, 2024



Vision-Language Models (VLMs) have enabled a variety of real-world applications. The large parameter size of VLMs brings large memory and computation overhead which poses significant challenges for deployment. Post-Training Quantization (PTQ) is an effective technique to reduce the memory and computation overhead. Existing PTQ methods mainly focus on large language models (LLMs), without considering the differences across other modalities. In this paper, we discover that there is a significant difference in sensitivity between language and vision tokens in large VLMs. Therefore, treating tokens from different modalities equally, as in existing PTQ methods, may over-emphasize the insensitive modalities, leading to significant accuracy loss. To deal with the above issue, we propose a simple yet effective method, Modality-Balanced Quantization (MBQ), for large VLMs. Specifically, MBQ incorporates the different sensitivities across modalities during the calibration process to minimize the reconstruction loss for better quantization parameters. Extensive experiments show that MBQ can significantly improve task accuracy by up to 4.4% and 11.6% under W3 and W4A8 quantization for 7B to 70B VLMs, compared to SOTA baselines. Additionally, we implement a W3 GPU kernel that fuses the dequantization and GEMV operators, achieving a 1.4x speedup on LLaVA-onevision-7B on the RTX 4090. The code is available at https://github.com/thu-nics/MBQ.