 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning an Efficient Multimodal Depth Completion Model
Aug 23, 2022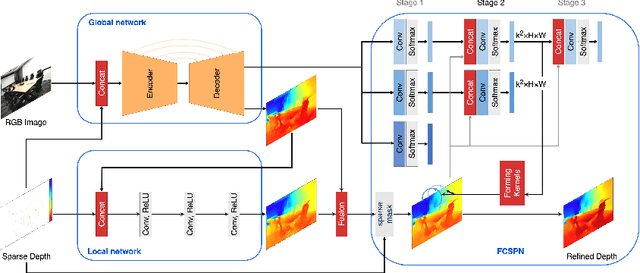
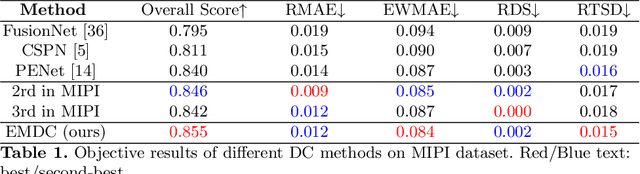
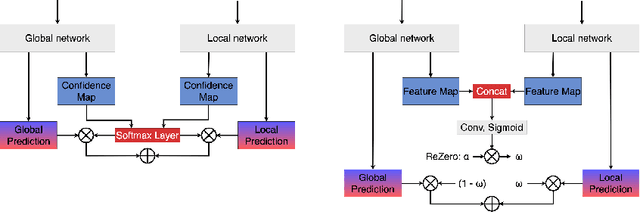
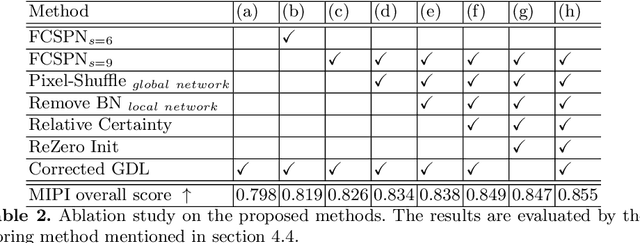
With the wide application of sparse ToF sensors in mobile devices, RGB image-guided sparse depth completion has attracted extensive attention recently, but still faces some problems. First, the fusion of multimodal information requires more network modules to process different modalities. But the application scenarios of sparse ToF measurements usually demand lightweight structure and low computational cost. Second, fusing sparse and noisy depth data with dense pixel-wise RGB data may introduce artifacts. In this paper, a light but efficient depth completion network is proposed, which consists of a two-branch global and local depth prediction module and a funnel convolutional spatial propagation network. The two-branch structure extracts and fuses cross-modal features with lightweight backbones. The improved spatial propagation module can refine the completed depth map gradually. Furthermore, corrected gradient loss is presented for the depth completion problem. Experimental results demonstrate the proposed method can outperform some state-of-the-art methods with a lightweight architecture. The proposed method also wins the championship in the MIPI2022 RGB+TOF depth completion challenge.
NTIRE 2021 Challenge on Quality Enhancement of Compressed Video: Methods and Results
May 02, 2021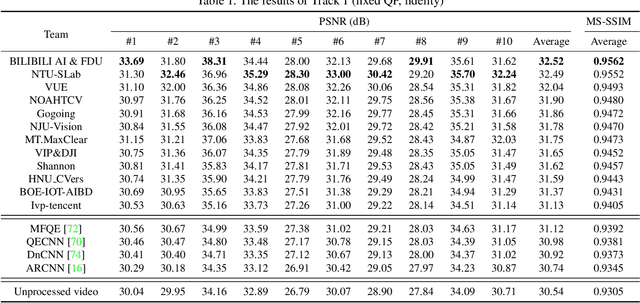
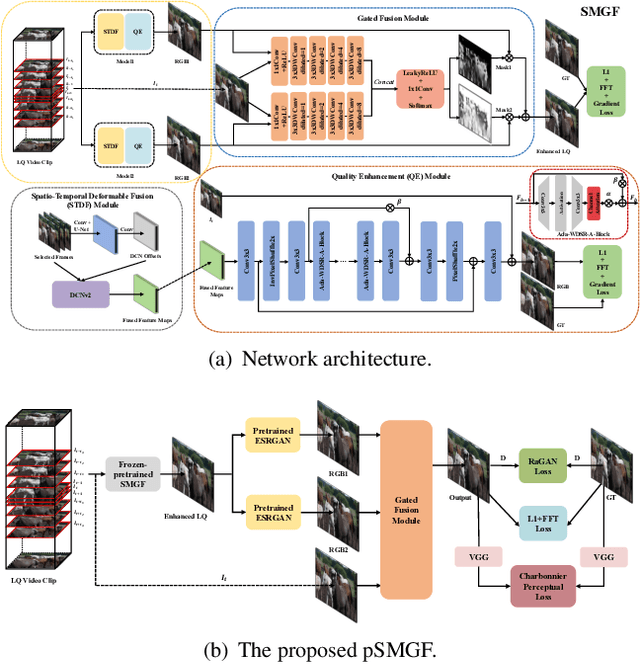
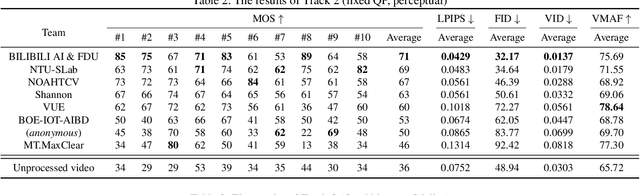
This paper reviews the first NTIRE challenge on quality enhancement of compressed video, with a focus on the proposed methods and results. In this challenge, the new Large-scale Diverse Video (LDV) dataset is employed. The challenge has three tracks. Tracks 1 and 2 aim at enhancing the videos compressed by HEVC at a fixed QP, while Track 3 is designed for enhancing the videos compressed by x265 at a fixed bit-rate. Besides, the quality enhancement of Tracks 1 and 3 targets at improving the fidelity (PSNR), and Track 2 targets at enhancing the perceptual quality. The three tracks totally attract 482 registrations. In the test phase, 12 teams, 8 teams and 11 teams submitted the final results of Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of video quality enhancement. The homepage of the challenge: https://github.com/RenYang-home/NTIRE21_VEnh
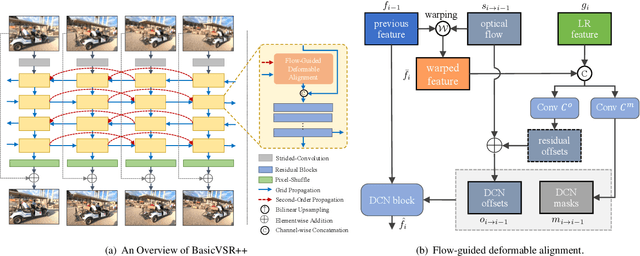
Super-Resolving Compressed Video in Coding Chain
Mar 26, 2021
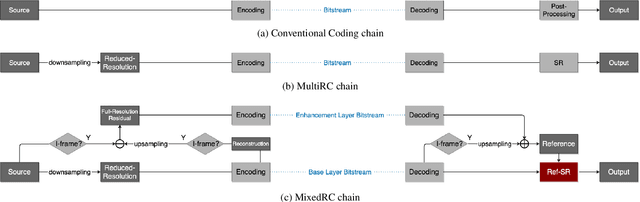

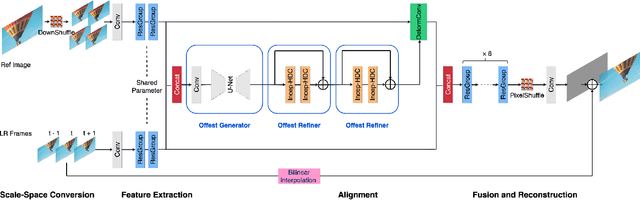
Scaling and lossy coding are widely used in video transmission and storage. Previous methods for enhancing the resolution of such videos often ignore the inherent interference between resolution loss and compression artifacts, which compromises perceptual video quality. To address this problem, we present a mixed-resolution coding framework, which cooperates with a reference-based DCNN. In this novel coding chain, the reference-based DCNN learns the direct mapping from low-resolution (LR) compressed video to their high-resolution (HR) clean version at the decoder side. We further improve reconstruction quality by devising an efficient deformable alignment module with receptive field block to handle various motion distances and introducing a disentangled loss that helps networks distinguish the artifact patterns from texture. Extensive experiments demonstrate the effectiveness of proposed innovations by comparing with state-of-the-art single image, video and reference-based restoration methods.