 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Image Generation by Synthesizing Exposure Brackets
Apr 22, 2026The life of a photo begins with photons striking the sensor, whose signals are passed through a sophisticated image signal processing (ISP) pipeline to produce a display-referred image. However, such images are no longer faithful to the incident light, being compressed in dynamic range and stylized by subjective preferences. In contrast, RAW images record direct sensor signals before non-linear tone mapping. After camera response curve correction and demosaicing, they can be converted into linear images, which are scene-referred representations that directly reflect true irradiance and are invariant to sensor-specific factors. Since image sensors have better dynamic range and bit depth, linear images contain richer information than display-referred ones, leaving users more room for editing during post-processing. Despite this advantage, current generative models mainly synthesize display-referred images, which inherently limits downstream editing. In this paper, we address the task of text-to-linear-image generation: synthesizing a high-quality, scene-referred linear image that preserves full dynamic range, conditioned on a text prompt, for professional post-processing. Generating linear images is challenging, as pre-trained VAEs in latent diffusion models struggle to simultaneously preserve extreme highlights and shadows due to the higher dynamic range and bit depth. To this end, we represent a linear image as a sequence of exposure brackets, each capturing a specific portion of the dynamic range, and propose a DiT-based flow-matching architecture for text-conditioned exposure bracket generation. We further demonstrate downstream applications including text-guided linear image editing and structure-conditioned generation via ControlNet.
4RC: 4D Reconstruction via Conditional Querying Anytime and Anywhere
Feb 10, 2026We present 4RC, a unified feed-forward framework for 4D reconstruction from monocular videos. Unlike existing approaches that typically decouple motion from geometry or produce limited 4D attributes such as sparse trajectories or two-view scene flow, 4RC learns a holistic 4D representation that jointly captures dense scene geometry and motion dynamics. At its core, 4RC introduces a novel encode-once, query-anywhere and anytime paradigm: a transformer backbone encodes the entire video into a compact spatio-temporal latent space, from which a conditional decoder can efficiently query 3D geometry and motion for any query frame at any target timestamp. To facilitate learning, we represent per-view 4D attributes in a minimally factorized form by decomposing them into base geometry and time-dependent relative motion. Extensive experiments demonstrate that 4RC outperforms prior and concurrent methods across a wide range of 4D reconstruction tasks.
PnP-U3D: Plug-and-Play 3D Framework Bridging Autoregression and Diffusion for Unified Understanding and Generation
Feb 03, 2026The rapid progress of large multimodal models has inspired efforts toward unified frameworks that couple understanding and generation. While such paradigms have shown remarkable success in 2D, extending them to 3D remains largely underexplored. Existing attempts to unify 3D tasks under a single autoregressive (AR) paradigm lead to significant performance degradation due to forced signal quantization and prohibitive training cost. Our key insight is that the essential challenge lies not in enforcing a unified autoregressive paradigm, but in enabling effective information interaction between generation and understanding while minimally compromising their inherent capabilities and leveraging pretrained models to reduce training cost. Guided by this perspective, we present the first unified framework for 3D understanding and generation that combines autoregression with diffusion. Specifically, we adopt an autoregressive next-token prediction paradigm for 3D understanding, and a continuous diffusion paradigm for 3D generation. A lightweight transformer bridges the feature space of large language models and the conditional space of 3D diffusion models, enabling effective cross-modal information exchange while preserving the priors learned by standalone models. Extensive experiments demonstrate that our framework achieves state-of-the-art performance across diverse 3D understanding and generation benchmarks, while also excelling in 3D editing tasks. These results highlight the potential of unified AR+diffusion models as a promising direction for building more general-purpose 3D intelligence.
Zoom-IQA: Image Quality Assessment with Reliable Region-Aware Reasoning
Jan 06, 2026Image Quality Assessment (IQA) is a long-standing problem in computer vision. Previous methods typically focus on predicting numerical scores without explanation or provide low-level descriptions lacking precise scores. Recent reasoning-based vision language models (VLMs) have shown strong potential for IQA, enabling joint generation of quality descriptions and scores. However, we notice that existing VLM-based IQA methods tend to exhibit unreliable reasoning due to their limited capability of integrating visual and textual cues. In this work, we introduce Zoom-IQA, a VLM-based IQA model to explicitly emulate key cognitive behaviors: uncertainty awareness, region reasoning, and iterative refinement. Specifically, we present a two-stage training pipeline: 1) supervised fine-tuning (SFT) on our Grounded-Rationale-IQA (GR-IQA) dataset to teach the model to ground its assessments in key regions; and 2) reinforcement learning (RL) for dynamic policy exploration, primarily stabilized by our KL-Coverage regularizer to prevent reasoning and scoring diversity collapse, and supported by a Progressive Re-sampling Strategy to mitigate annotation bias. Extensive experiments show that Zoom-IQA achieves improved robustness, explainability, and generalization. The application to downstream tasks, such as image restoration, further demonstrates the effectiveness of Zoom-IQA.
MatAnyone 2: Scaling Video Matting via a Learned Quality Evaluator
Dec 12, 2025



Video matting remains limited by the scale and realism of existing datasets. While leveraging segmentation data can enhance semantic stability, the lack of effective boundary supervision often leads to segmentation-like mattes lacking fine details. To this end, we introduce a learned Matting Quality Evaluator (MQE) that assesses semantic and boundary quality of alpha mattes without ground truth. It produces a pixel-wise evaluation map that identifies reliable and erroneous regions, enabling fine-grained quality assessment. The MQE scales up video matting in two ways: (1) as an online matting-quality feedback during training to suppress erroneous regions, providing comprehensive supervision, and (2) as an offline selection module for data curation, improving annotation quality by combining the strengths of leading video and image matting models. This process allows us to build a large-scale real-world video matting dataset, VMReal, containing 28K clips and 2.4M frames. To handle large appearance variations in long videos, we introduce a reference-frame training strategy that incorporates long-range frames beyond the local window for effective training. Our MatAnyone 2 achieves state-of-the-art performance on both synthetic and real-world benchmarks, surpassing prior methods across all metrics.
STream3R: Scalable Sequential 3D Reconstruction with Causal Transformer
Aug 14, 2025We present STream3R, a novel approach to 3D reconstruction that reformulates pointmap prediction as a decoder-only Transformer problem. Existing state-of-the-art methods for multi-view reconstruction either depend on expensive global optimization or rely on simplistic memory mechanisms that scale poorly with sequence length. In contrast, STream3R introduces an streaming framework that processes image sequences efficiently using causal attention, inspired by advances in modern language modeling. By learning geometric priors from large-scale 3D datasets, STream3R generalizes well to diverse and challenging scenarios, including dynamic scenes where traditional methods often fail. Extensive experiments show that our method consistently outperforms prior work across both static and dynamic scene benchmarks. Moreover, STream3R is inherently compatible with LLM-style training infrastructure, enabling efficient large-scale pretraining and fine-tuning for various downstream 3D tasks. Our results underscore the potential of causal Transformer models for online 3D perception, paving the way for real-time 3D understanding in streaming environments. More details can be found in our project page: https://nirvanalan.github.io/projects/stream3r.
SeedVR2: One-Step Video Restoration via Diffusion Adversarial Post-Training
Jun 05, 2025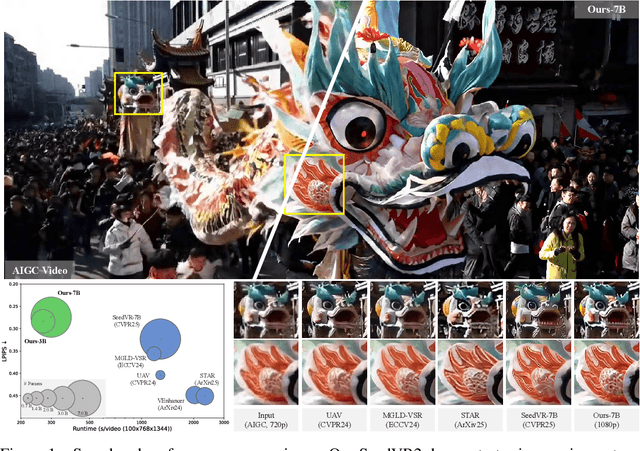
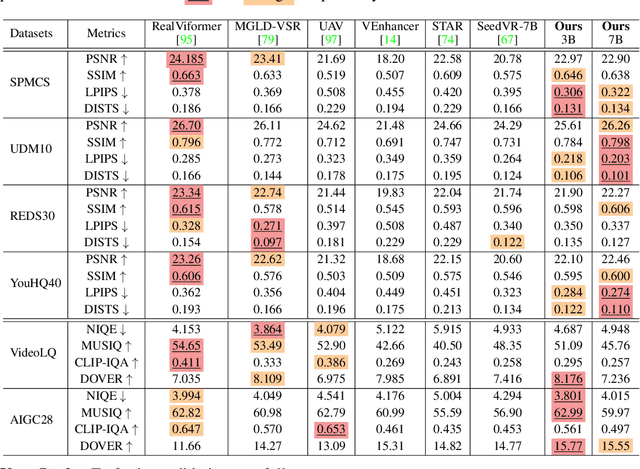
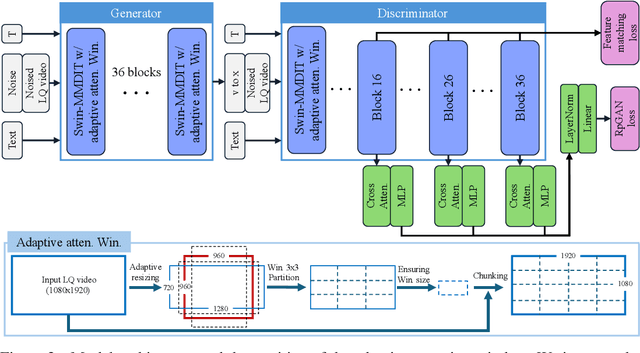
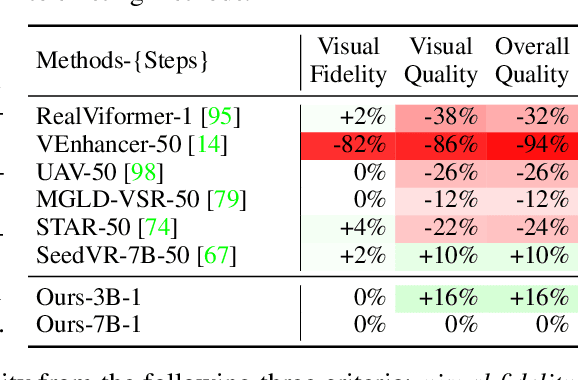
Recent advances in diffusion-based video restoration (VR) demonstrate significant improvement in visual quality, yet yield a prohibitive computational cost during inference. While several distillation-based approaches have exhibited the potential of one-step image restoration, extending existing approaches to VR remains challenging and underexplored, particularly when dealing with high-resolution video in real-world settings. In this work, we propose a one-step diffusion-based VR model, termed as SeedVR2, which performs adversarial VR training against real data. To handle the challenging high-resolution VR within a single step, we introduce several enhancements to both model architecture and training procedures. Specifically, an adaptive window attention mechanism is proposed, where the window size is dynamically adjusted to fit the output resolutions, avoiding window inconsistency observed under high-resolution VR using window attention with a predefined window size. To stabilize and improve the adversarial post-training towards VR, we further verify the effectiveness of a series of losses, including a proposed feature matching loss without significantly sacrificing training efficiency. Extensive experiments show that SeedVR2 can achieve comparable or even better performance compared with existing VR approaches in a single step.
ObjectClear: Complete Object Removal via Object-Effect Attention
May 28, 2025Object removal requires eliminating not only the target object but also its effects, such as shadows and reflections. However, diffusion-based inpainting methods often produce artifacts, hallucinate content, alter background, and struggle to remove object effects accurately. To address this challenge, we introduce a new dataset for OBject-Effect Removal, named OBER, which provides paired images with and without object effects, along with precise masks for both objects and their associated visual artifacts. The dataset comprises high-quality captured and simulated data, covering diverse object categories and complex multi-object scenes. Building on OBER, we propose a novel framework, ObjectClear, which incorporates an object-effect attention mechanism to guide the model toward the foreground removal regions by learning attention masks, effectively decoupling foreground removal from background reconstruction. Furthermore, the predicted attention map enables an attention-guided fusion strategy during inference, greatly preserving background details. Extensive experiments demonstrate that ObjectClear outperforms existing methods, achieving improved object-effect removal quality and background fidelity, especially in complex scenarios.
Bokeh Diffusion: Defocus Blur Control in Text-to-Image Diffusion Models
Mar 13, 2025Recent advances in large-scale text-to-image models have revolutionized creative fields by generating visually captivating outputs from textual prompts; however, while traditional photography offers precise control over camera settings to shape visual aesthetics -- such as depth-of-field -- current diffusion models typically rely on prompt engineering to mimic such effects. This approach often results in crude approximations and inadvertently altering the scene content. In this work, we propose Bokeh Diffusion, a scene-consistent bokeh control framework that explicitly conditions a diffusion model on a physical defocus blur parameter. By grounding depth-of-field adjustments, our method preserves the underlying scene structure as the level of blur is varied. To overcome the scarcity of paired real-world images captured under different camera settings, we introduce a hybrid training pipeline that aligns in-the-wild images with synthetic blur augmentations. Extensive experiments demonstrate that our approach not only achieves flexible, lens-like blur control but also supports applications such as real image editing via inversion.
MatAnyone: Stable Video Matting with Consistent Memory Propagation
Jan 24, 2025



Auxiliary-free human video matting methods, which rely solely on input frames, often struggle with complex or ambiguous backgrounds. To address this, we propose MatAnyone, a robust framework tailored for target-assigned video matting. Specifically, building on a memory-based paradigm, we introduce a consistent memory propagation module via region-adaptive memory fusion, which adaptively integrates memory from the previous frame. This ensures semantic stability in core regions while preserving fine-grained details along object boundaries. For robust training, we present a larger, high-quality, and diverse dataset for video matting. Additionally, we incorporate a novel training strategy that efficiently leverages large-scale segmentation data, boosting matting stability. With this new network design, dataset, and training strategy, MatAnyone delivers robust and accurate video matting results in diverse real-world scenarios, outperforming existing methods.