 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video: Dataset, Methods and Results
Apr 25, 2022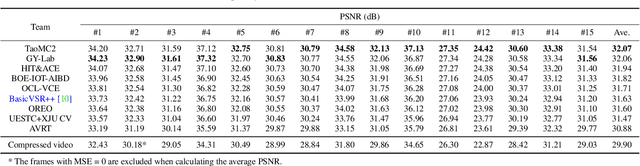
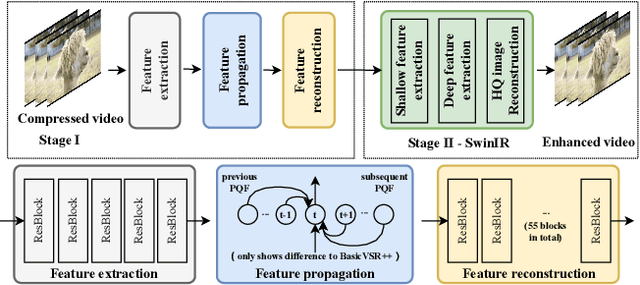
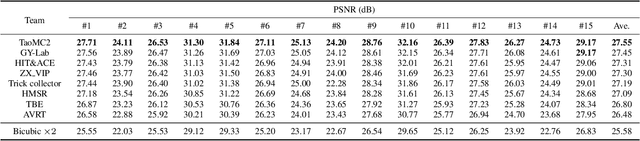

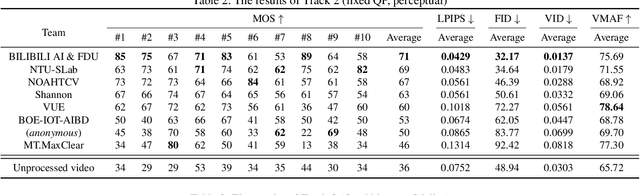
This paper reviews the NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video. In this challenge, we proposed the LDV 2.0 dataset, which includes the LDV dataset (240 videos) and 95 additional videos. This challenge includes three tracks. Track 1 aims at enhancing the videos compressed by HEVC at a fixed QP. Track 2 and Track 3 target both the super-resolution and quality enhancement of HEVC compressed video. They require x2 and x4 super-resolution, respectively. The three tracks totally attract more than 600 registrations. In the test phase, 8 teams, 8 teams and 12 teams submitted the final results to Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution and quality enhancement of compressed video. The proposed LDV 2.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge (including open-sourced codes) is at https://github.com/RenYang-home/NTIRE22_VEnh_SR.
edge-SR: Super-Resolution For The Masses
Aug 23, 2021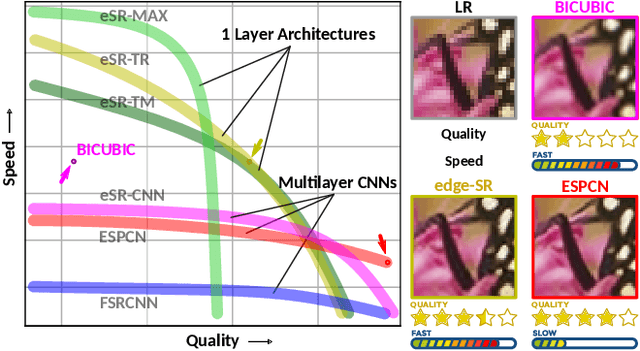

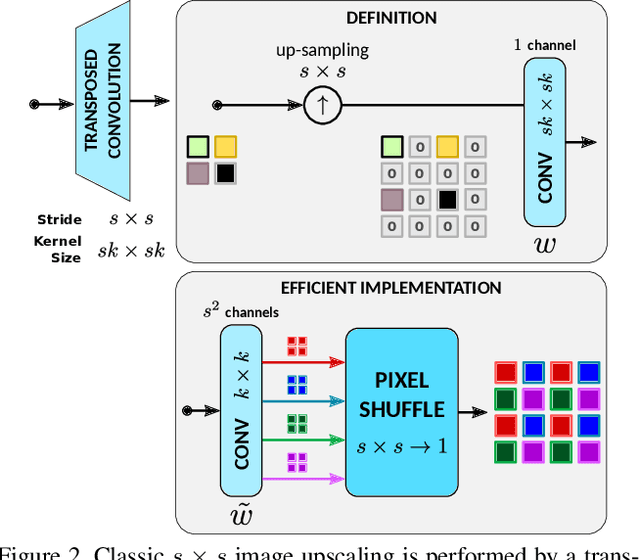
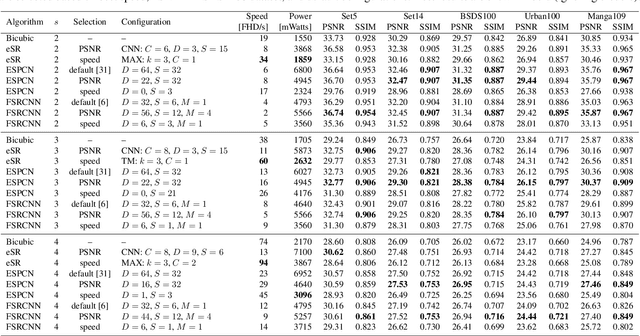
Classic image scaling (e.g. bicubic) can be seen as one convolutional layer and a single upscaling filter. Its implementation is ubiquitous in all display devices and image processing software. In the last decade deep learning systems have been introduced for the task of image super-resolution (SR), using several convolutional layers and numerous filters. These methods have taken over the benchmarks of image quality for upscaling tasks. Would it be possible to replace classic upscalers with deep learning architectures on edge devices such as display panels, tablets, laptop computers, etc.? On one hand, the current trend in Edge-AI chips shows a promising future in this direction, with rapid development of hardware that can run deep-learning tasks efficiently. On the other hand, in image SR only few architectures have pushed the limit to extreme small sizes that can actually run on edge devices at real-time. We explore possible solutions to this problem with the aim to fill the gap between classic upscalers and small deep learning configurations. As a transition from classic to deep-learning upscaling we propose edge-SR (eSR), a set of one-layer architectures that use interpretable mechanisms to upscale images. Certainly, a one-layer architecture cannot reach the quality of deep learning systems. Nevertheless, we find that for high speed requirements, eSR becomes better at trading-off image quality and runtime performance. Filling the gap between classic and deep-learning architectures for image upscaling is critical for massive adoption of this technology. It is equally important to have an interpretable system that can reveal the inner strategies to solve this problem and guide us to future improvements and better understanding of larger networks.
NTIRE 2021 Challenge on Quality Enhancement of Compressed Video: Methods and Results
May 02, 2021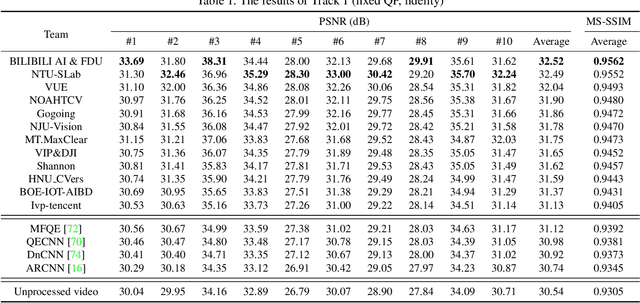
This paper reviews the first NTIRE challenge on quality enhancement of compressed video, with a focus on the proposed methods and results. In this challenge, the new Large-scale Diverse Video (LDV) dataset is employed. The challenge has three tracks. Tracks 1 and 2 aim at enhancing the videos compressed by HEVC at a fixed QP, while Track 3 is designed for enhancing the videos compressed by x265 at a fixed bit-rate. Besides, the quality enhancement of Tracks 1 and 3 targets at improving the fidelity (PSNR), and Track 2 targets at enhancing the perceptual quality. The three tracks totally attract 482 registrations. In the test phase, 12 teams, 8 teams and 11 teams submitted the final results of Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of video quality enhancement. The homepage of the challenge: https://github.com/RenYang-home/NTIRE21_VEnh
Back-Projection Pipeline
Jan 25, 2021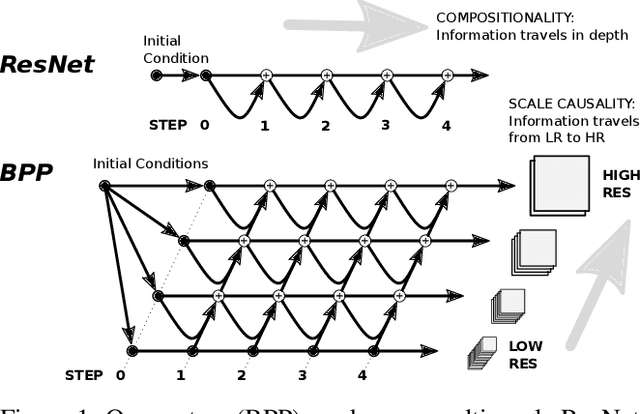
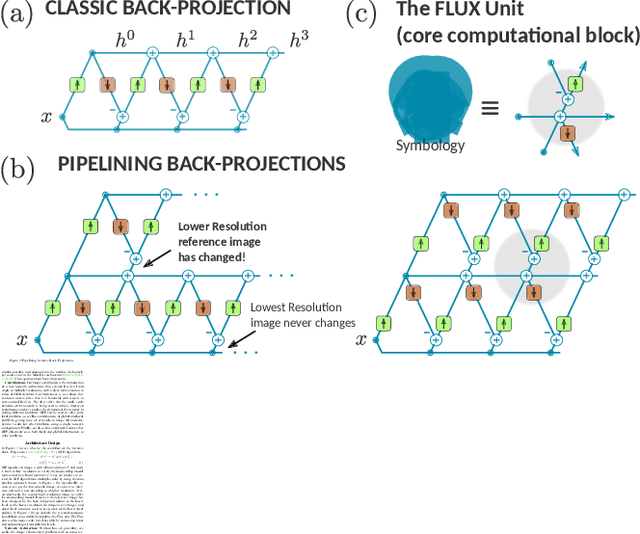
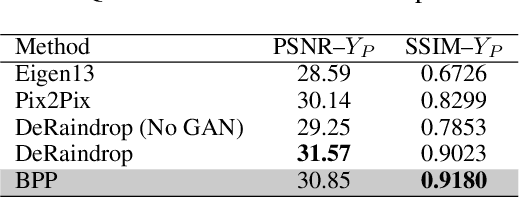
We propose a simple extension of residual networks that works simultaneously in multiple resolutions. Our network design is inspired by the iterative back-projection algorithm but seeks the more difficult task of learning how to enhance images. Compared to similar approaches, we propose a novel solution to make back-projections run in multiple resolutions by using a data pipeline workflow. Features are updated at multiple scales in each layer of the network. The update dynamic through these layers includes interactions between different resolutions in a way that is causal in scale, and it is represented by a system of ODEs, as opposed to a single ODE in the case of ResNets. The system can be used as a generic multi-resolution approach to enhance images. We test it on several challenging tasks with special focus on super-resolution and raindrop removal. Our results are competitive with state-of-the-arts and show a strong ability of our system to learn both global and local image features.
Multi-Grid Back-Projection Networks
Jan 01, 2021


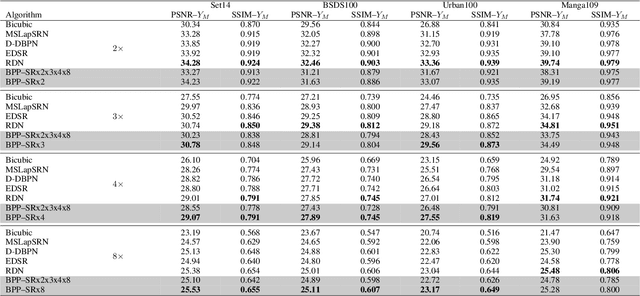
Multi-Grid Back-Projection (MGBP) is a fully-convolutional network architecture that can learn to restore images and videos with upscaling artifacts. Using the same strategy of multi-grid partial differential equation (PDE) solvers this multiscale architecture scales computational complexity efficiently with increasing output resolutions. The basic processing block is inspired in the iterative back-projection (IBP) algorithm and constitutes a type of cross-scale residual block with feedback from low resolution references. The architecture performs in par with state-of-the-arts alternatives for regression targets that aim to recover an exact copy of a high resolution image or video from which only a downscale image is known. A perceptual quality target aims to create more realistic outputs by introducing artificial changes that can be different from a high resolution original content as long as they are consistent with the low resolution input. For this target we propose a strategy using noise inputs in different resolution scales to control the amount of artificial details generated in the output. The noise input controls the amount of innovation that the network uses to create artificial realistic details. The effectiveness of this strategy is shown in benchmarks and it is explained as a particular strategy to traverse the perception-distortion plane.
AIM 2020 Challenge on Video Extreme Super-Resolution: Methods and Results
Sep 14, 2020This paper reviews the video extreme super-resolution challenge associated with the AIM 2020 workshop at ECCV 2020. Common scaling factors for learned video super-resolution (VSR) do not go beyond factor 4. Missing information can be restored well in this region, especially in HR videos, where the high-frequency content mostly consists of texture details. The task in this challenge is to upscale videos with an extreme factor of 16, which results in more serious degradations that also affect the structural integrity of the videos. A single pixel in the low-resolution (LR) domain corresponds to 256 pixels in the high-resolution (HR) domain. Due to this massive information loss, it is hard to accurately restore the missing information. Track 1 is set up to gauge the state-of-the-art for such a demanding task, where fidelity to the ground truth is measured by PSNR and SSIM. Perceptually higher quality can be achieved in trade-off for fidelity by generating plausible high-frequency content. Track 2 therefore aims at generating visually pleasing results, which are ranked according to human perception, evaluated by a user study. In contrast to single image super-resolution (SISR), VSR can benefit from additional information in the temporal domain. However, this also imposes an additional requirement, as the generated frames need to be consistent along time.
NTIRE 2020 Challenge on Real Image Denoising: Dataset, Methods and Results
May 08, 2020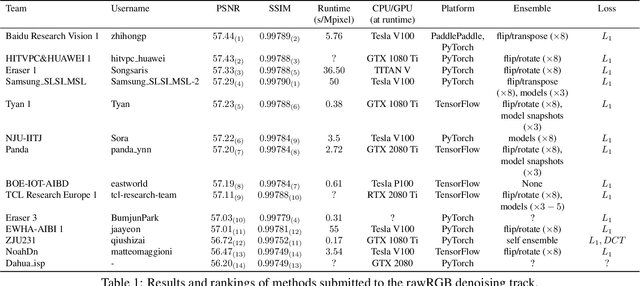
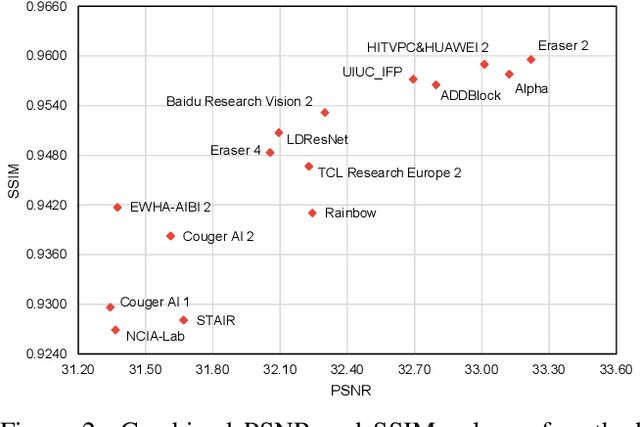
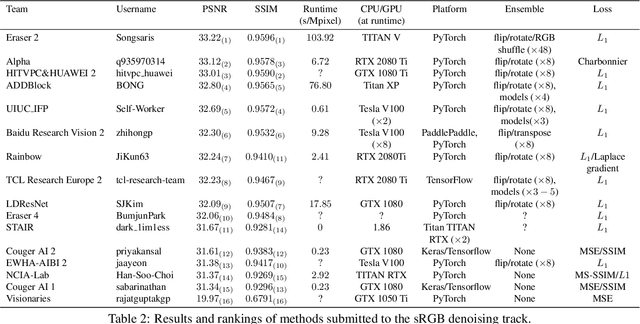
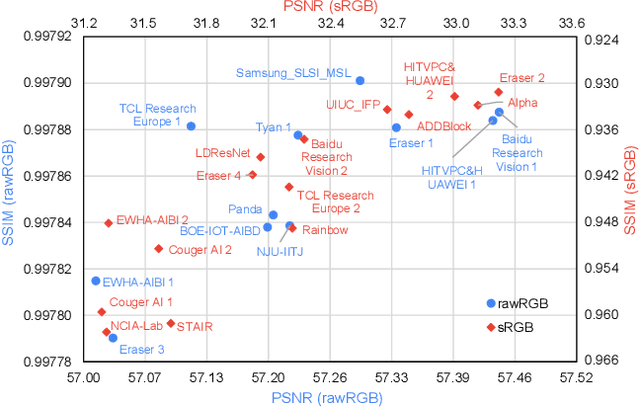
This paper reviews the NTIRE 2020 challenge on real image denoising with focus on the newly introduced dataset, the proposed methods and their results. The challenge is a new version of the previous NTIRE 2019 challenge on real image denoising that was based on the SIDD benchmark. This challenge is based on a newly collected validation and testing image datasets, and hence, named SIDD+. This challenge has two tracks for quantitatively evaluating image denoising performance in (1) the Bayer-pattern rawRGB and (2) the standard RGB (sRGB) color spaces. Each track ~250 registered participants. A total of 22 teams, proposing 24 methods, competed in the final phase of the challenge. The proposed methods by the participating teams represent the current state-of-the-art performance in image denoising targeting real noisy images. The newly collected SIDD+ datasets are publicly available at: https://bit.ly/siddplus_data.
NTIRE 2020 Challenge on Real-World Image Super-Resolution: Methods and Results
May 05, 2020
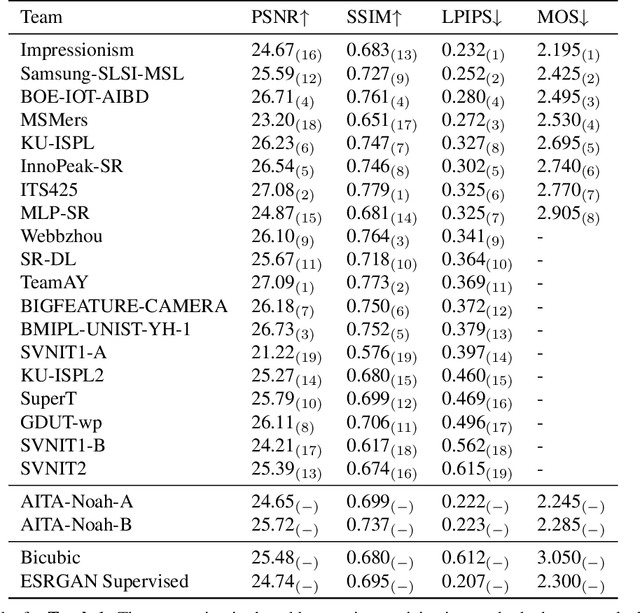
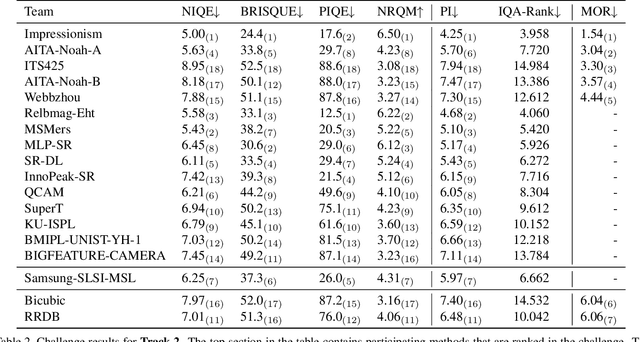

This paper reviews the NTIRE 2020 challenge on real world super-resolution. It focuses on the participating methods and final results. The challenge addresses the real world setting, where paired true high and low-resolution images are unavailable. For training, only one set of source input images is therefore provided along with a set of unpaired high-quality target images. In Track 1: Image Processing artifacts, the aim is to super-resolve images with synthetically generated image processing artifacts. This allows for quantitative benchmarking of the approaches \wrt a ground-truth image. In Track 2: Smartphone Images, real low-quality smart phone images have to be super-resolved. In both tracks, the ultimate goal is to achieve the best perceptual quality, evaluated using a human study. This is the second challenge on the subject, following AIM 2019, targeting to advance the state-of-the-art in super-resolution. To measure the performance we use the benchmark protocol from AIM 2019. In total 22 teams competed in the final testing phase, demonstrating new and innovative solutions to the problem.
MGBPv2: Scaling Up Multi-Grid Back-Projection Networks
Sep 27, 2019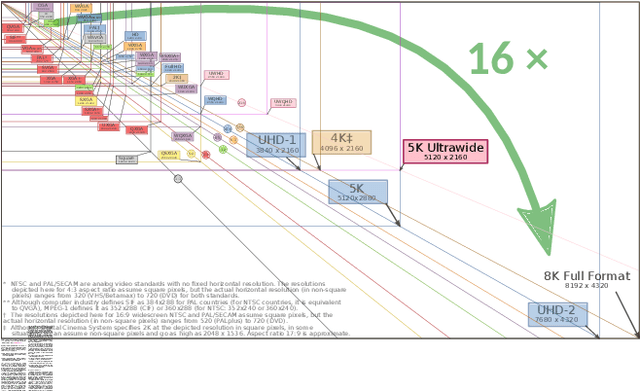
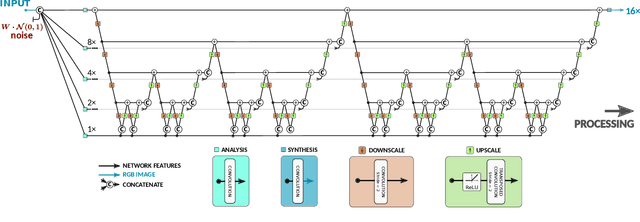
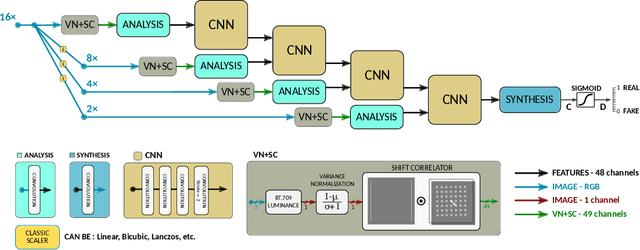

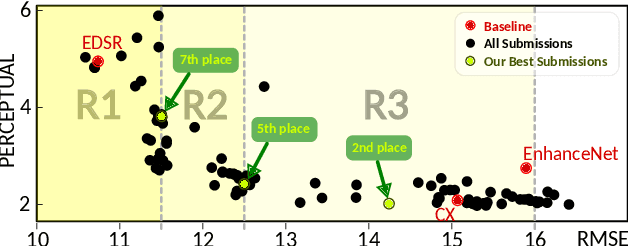
Here, we describe our solution for the AIM-2019 Extreme Super-Resolution Challenge, where we won the 1st place in terms of perceptual quality (MOS) similar to the ground truth and achieved the 5th place in terms of high-fidelity (PSNR). To tackle this challenge, we introduce the second generation of MultiGrid BackProjection networks (MGBPv2) whose major modifications make the system scalable and more general than its predecessor. It combines the scalability of the multigrid algorithm and the performance of iterative backprojections. In its original form, MGBP is limited to a small number of parameters due to a strongly recursive structure. In MGBPv2, we make full use of the multigrid recursion from the beginning of the network; we allow different parameters in every module of the network; we simplify the main modules; and finally, we allow adjustments of the number of network features based on the scale of operation. For inference tasks, we introduce an overlapping patch approach to further allow processing of very large images (e.g. 8K). Our training strategies make use of a multiscale loss, combining distortion and/or perception losses on the output as well as downscaled output images. The final system can balance between high quality and high performance.
A Tour of Convolutional Networks Guided by Linear Interpreters
Aug 14, 2019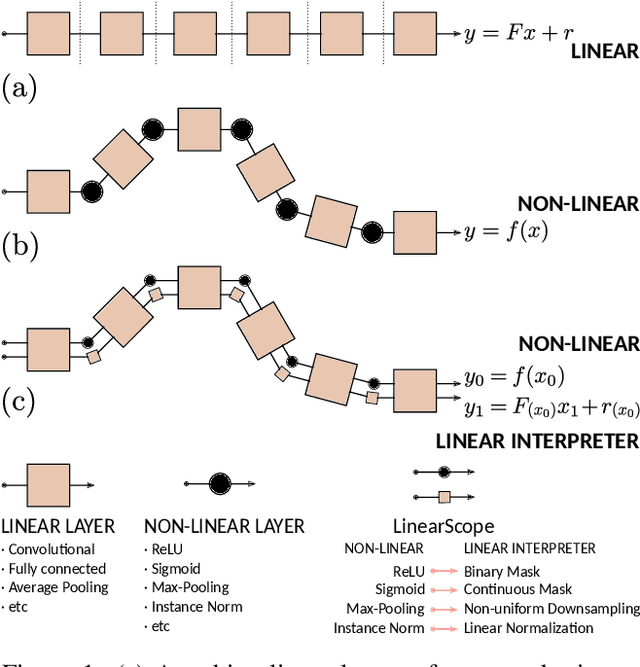



Convolutional networks are large linear systems divided into layers and connected by non-linear units. These units are the "articulations" that allow the network to adapt to the input. To understand how a network manages to solve a problem we must look at the articulated decisions in entirety. If we could capture the actions of non-linear units for a particular input, we would be able to replay the whole system back and forth as if it was always linear. It would also reveal the actions of non-linearities because the resulting linear system, a Linear Interpreter, depends on the input image. We introduce a hooking layer, called a LinearScope, which allows us to run the network and the linear interpreter in parallel. Its implementation is simple, flexible and efficient. From here we can make many curious inquiries: how do these linear systems look like? When the rows and columns of the transformation matrix are images, how do they look like? What type of basis do these linear transformations rely on? The answers depend on the problems presented, through which we take a tour to some popular architectures used for classification, super-resolution (SR) and image-to-image translation (I2I). For classification we observe that popular networks use a pixel-wise vote per class strategy and heavily rely on bias parameters. For SR and I2I we find that CNNs use wavelet-type basis similar to the human visual system. For I2I we reveal copy-move and template-creation strategies to generate outputs.