 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Neural Representations for Videos with a Conditional Decoder
Mar 08, 2024



Implicit neural representations (INRs) have emerged as a promising approach for video storage and processing, showing remarkable versatility across various video tasks. However, existing methods often fail to fully leverage their representation capabilities, primarily due to inadequate alignment of intermediate features during target frame decoding. This paper introduces a universal boosting framework for current implicit video representation approaches. Specifically, we utilize a conditional decoder with a temporal-aware affine transform module, which uses the frame index as a prior condition to effectively align intermediate features with target frames. Besides, we introduce a sinusoidal NeRV-like block to generate diverse intermediate features and achieve a more balanced parameter distribution, thereby enhancing the model's capacity. With a high-frequency information-preserving reconstruction loss, our approach successfully boosts multiple baseline INRs in the reconstruction quality and convergence speed for video regression, and exhibits superior inpainting and interpolation results. Further, we integrate a consistent entropy minimization technique and develop video codecs based on these boosted INRs. Experiments on the UVG dataset confirm that our enhanced codecs significantly outperform baseline INRs and offer competitive rate-distortion performance compared to traditional and learning-based codecs.
Detecting Reddit Users with Depression Using a Hybrid Neural Network
Feb 03, 2023



Depression is a widespread mental health issue, affecting an estimated 3.8% of the global population. It is also one of the main contributors to disability worldwide. Recently it is becoming popular for individuals to use social media platforms (e.g., Reddit) to express their difficulties and health issues (e.g., depression) and seek support from other users in online communities. It opens great opportunities to automatically identify social media users with depression by parsing millions of posts for potential interventions. Deep learning methods have begun to dominate in the field of machine learning and natural language processing (NLP) because of their ease of use, efficient processing, and state-of-the-art results on many NLP tasks. In this work, we propose a hybrid deep learning model which combines a pretrained sentence BERT (SBERT) and convolutional neural network (CNN) to detect individuals with depression with their Reddit posts. The sentence BERT is used to learn the meaningful representation of semantic information in each post. CNN enables the further transformation of those embeddings and the temporal identification of behavioral patterns of users. We trained and evaluated the model performance to identify Reddit users with depression by utilizing the Self-reported Mental Health Diagnoses (SMHD) data. The hybrid deep learning model achieved an accuracy of 0.86 and an F1 score of 0.86 and outperformed the state-of-the-art documented result (F1 score of 0.79) by other machine learning models in the literature. The results show the feasibility of the hybrid model to identify individuals with depression. Although the hybrid model is validated to detect depression with Reddit posts, it can be easily tuned and applied to other text classification tasks and different clinical applications.
Advancing Learned Video Compression with In-loop Frame Prediction
Nov 18, 2022Recent years have witnessed an increasing interest in end-to-end learned video compression. Most previous works explore temporal redundancy by detecting and compressing a motion map to warp the reference frame towards the target frame. Yet, it failed to adequately take advantage of the historical priors in the sequential reference frames. In this paper, we propose an Advanced Learned Video Compression (ALVC) approach with the in-loop frame prediction module, which is able to effectively predict the target frame from the previously compressed frames, without consuming any bit-rate. The predicted frame can serve as a better reference than the previously compressed frame, and therefore it benefits the compression performance. The proposed in-loop prediction module is a part of the end-to-end video compression and is jointly optimized in the whole framework. We propose the recurrent and the bi-directional in-loop prediction modules for compressing P-frames and B-frames, respectively. The experiments show the state-of-the-art performance of our ALVC approach in learned video compression. We also outperform the default hierarchical B mode of x265 in terms of PSNR and beat the slowest mode of the SSIM-tuned x265 on MS-SSIM. The project page: https://github.com/RenYang-home/ALVC.
AIM 2022 Challenge on Super-Resolution of Compressed Image and Video: Dataset, Methods and Results
Aug 25, 2022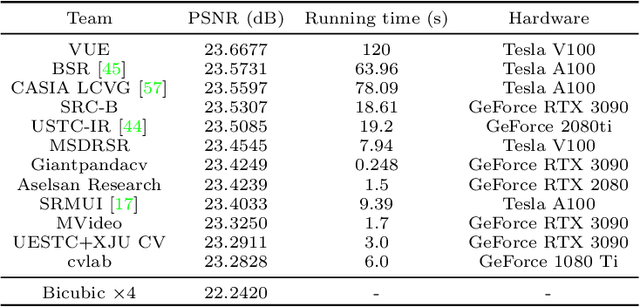
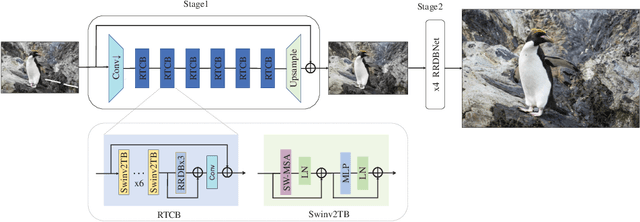

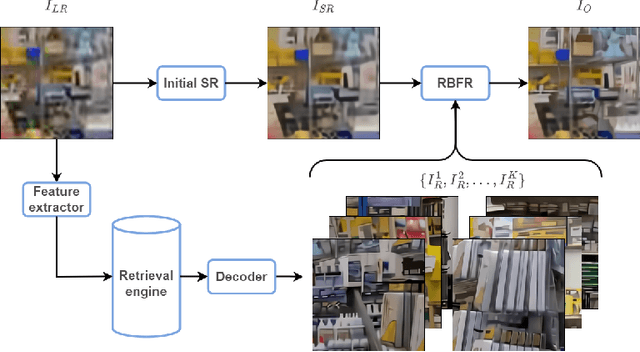
This paper reviews the Challenge on Super-Resolution of Compressed Image and Video at AIM 2022. This challenge includes two tracks. Track 1 aims at the super-resolution of compressed image, and Track~2 targets the super-resolution of compressed video. In Track 1, we use the popular dataset DIV2K as the training, validation and test sets. In Track 2, we propose the LDV 3.0 dataset, which contains 365 videos, including the LDV 2.0 dataset (335 videos) and 30 additional videos. In this challenge, there are 12 teams and 2 teams that submitted the final results to Track 1 and Track 2, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution on compressed image and video. The proposed LDV 3.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge is at https://github.com/RenYang-home/AIM22_CompressSR.
NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video: Dataset, Methods and Results
Apr 25, 2022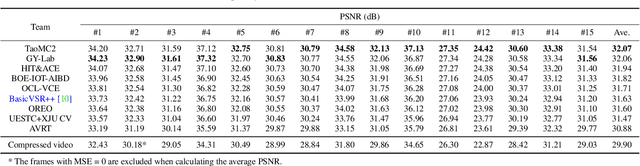
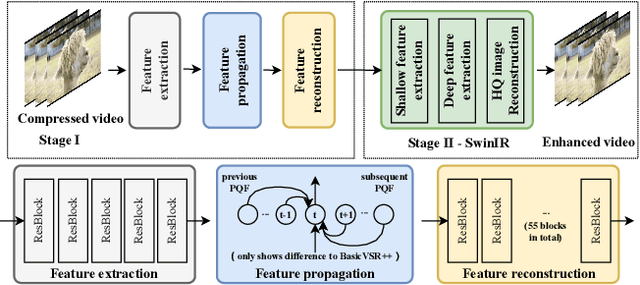
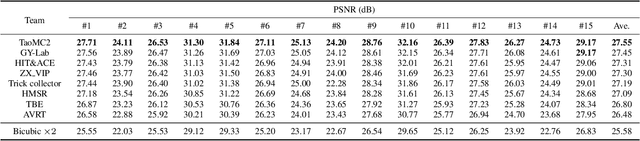

This paper reviews the NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video. In this challenge, we proposed the LDV 2.0 dataset, which includes the LDV dataset (240 videos) and 95 additional videos. This challenge includes three tracks. Track 1 aims at enhancing the videos compressed by HEVC at a fixed QP. Track 2 and Track 3 target both the super-resolution and quality enhancement of HEVC compressed video. They require x2 and x4 super-resolution, respectively. The three tracks totally attract more than 600 registrations. In the test phase, 8 teams, 8 teams and 12 teams submitted the final results to Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution and quality enhancement of compressed video. The proposed LDV 2.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge (including open-sourced codes) is at https://github.com/RenYang-home/NTIRE22_VEnh_SR.
Implicit Neural Representations for Image Compression
Dec 08, 2021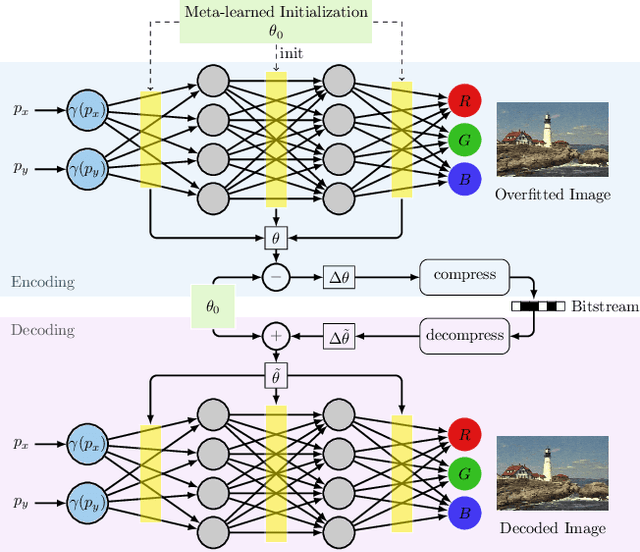
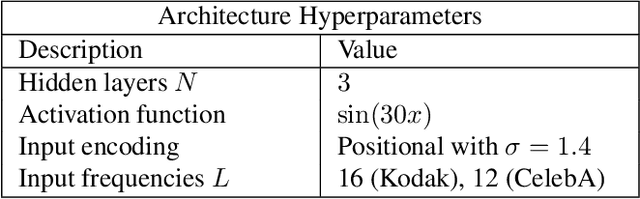

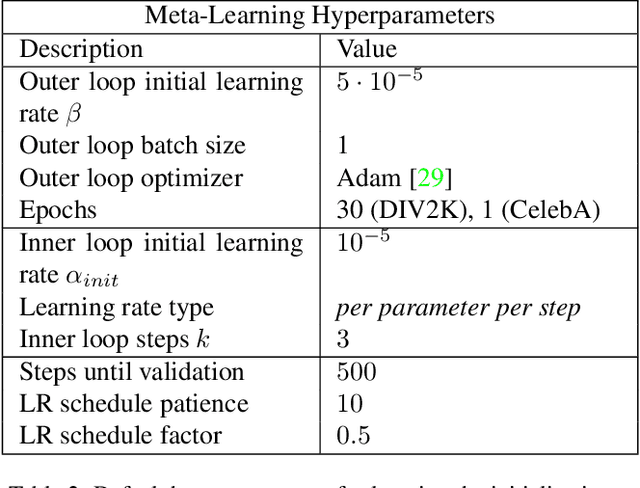
Recently Implicit Neural Representations (INRs) gained attention as a novel and effective representation for various data types. Thus far, prior work mostly focused on optimizing their reconstruction performance. This work investigates INRs from a novel perspective, i.e., as a tool for image compression. To this end, we propose the first comprehensive compression pipeline based on INRs including quantization, quantization-aware retraining and entropy coding. Encoding with INRs, i.e. overfitting to a data sample, is typically orders of magnitude slower. To mitigate this drawback, we leverage meta-learned initializations based on MAML to reach the encoding in fewer gradient updates which also generally improves rate-distortion performance of INRs. We find that our approach to source compression with INRs vastly outperforms similar prior work, is competitive with common compression algorithms designed specifically for images and closes the gap to state-of-the-art learned approaches based on Rate-Distortion Autoencoders. Moreover, we provide an extensive ablation study on the importance of individual components of our method which we hope facilitates future research on this novel approach to image compression.
Perceptual Learned Video Compression with Recurrent Conditional GAN
Sep 13, 2021

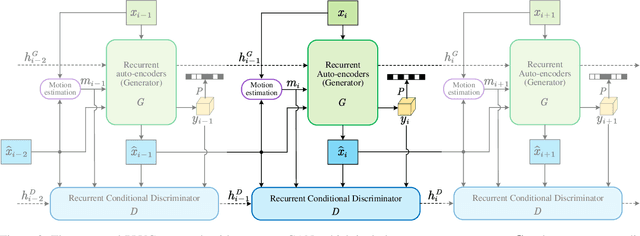
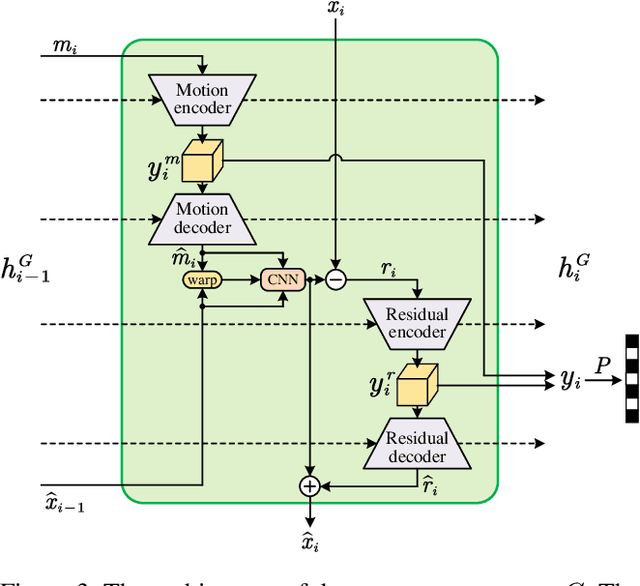
This paper proposes a Perceptual Learned Video Compression (PLVC) approach with recurrent conditional generative adversarial network. In our approach, the recurrent auto-encoder-based generator learns to fully explore the temporal correlation for compressing video. More importantly, we propose a recurrent conditional discriminator, which judges raw and compressed video conditioned on both spatial and temporal information, including the latent representation, temporal motion and hidden states in recurrent cells. This way, in the adversarial training, it pushes the generated video to be not only spatially photo-realistic but also temporally consistent with groundtruth and coherent among video frames. The experimental results show that the proposed PLVC model learns to compress video towards good perceptual quality at low bit-rate, and outperforms the previous traditional and learned approaches on several perceptual quality metrics. The user study further validates the outstanding perceptual performance of PLVC in comparison with the latest learned video compression approaches and the official HEVC test model (HM 16.20). The codes will be released at https://github.com/RenYang-home/PLVC.
R2RNet: Low-light Image Enhancement via Real-low to Real-normal Network
Jun 28, 2021

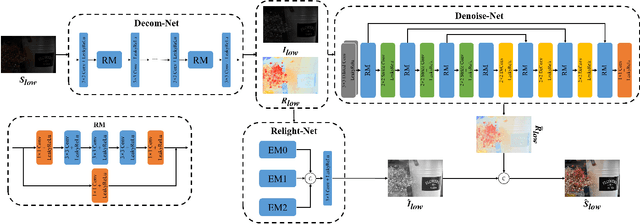

Images captured in weak illumination conditions will seriously degrade the image quality. Solving a series of degradation of low-light images can effectively improve the visual quality of the image and the performance of high-level visual tasks. In this paper, we propose a novel Real-low to Real-normal Network for low-light image enhancement, dubbed R2RNet, based on the Retinex theory, which includes three subnets: a Decom-Net, a Denoise-Net, and a Relight-Net. These three subnets are used for decomposing, denoising, and contrast enhancement, respectively. Unlike most previous methods trained on synthetic images, we collect the first Large-Scale Real-World paired low/normal-light images dataset (LSRW dataset) for training. Our method can properly improve the contrast and suppress noise simultaneously. Extensive experiments on publicly available datasets demonstrate that our method outperforms the existing state-of-the-art methods by a large margin both quantitatively and visually. And we also show that the performance of the high-level visual task (\emph{i.e.} face detection) can be effectively improved by using the enhanced results obtained by our method in low-light conditions. Our codes and the LSRW dataset are available at: https://github.com/abcdef2000/R2RNet.
NTIRE 2021 Challenge on Quality Enhancement of Compressed Video: Methods and Results
May 02, 2021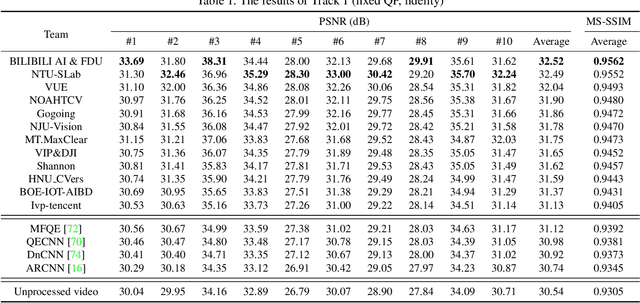
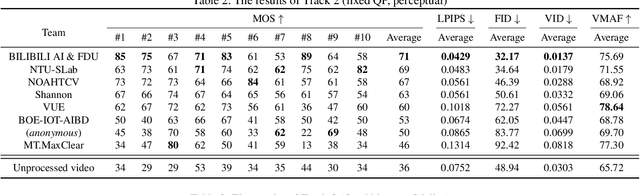
This paper reviews the first NTIRE challenge on quality enhancement of compressed video, with a focus on the proposed methods and results. In this challenge, the new Large-scale Diverse Video (LDV) dataset is employed. The challenge has three tracks. Tracks 1 and 2 aim at enhancing the videos compressed by HEVC at a fixed QP, while Track 3 is designed for enhancing the videos compressed by x265 at a fixed bit-rate. Besides, the quality enhancement of Tracks 1 and 3 targets at improving the fidelity (PSNR), and Track 2 targets at enhancing the perceptual quality. The three tracks totally attract 482 registrations. In the test phase, 12 teams, 8 teams and 11 teams submitted the final results of Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of video quality enhancement. The homepage of the challenge: https://github.com/RenYang-home/NTIRE21_VEnh
NTIRE 2021 Challenge on Quality Enhancement of Compressed Video: Dataset and Study
May 02, 2021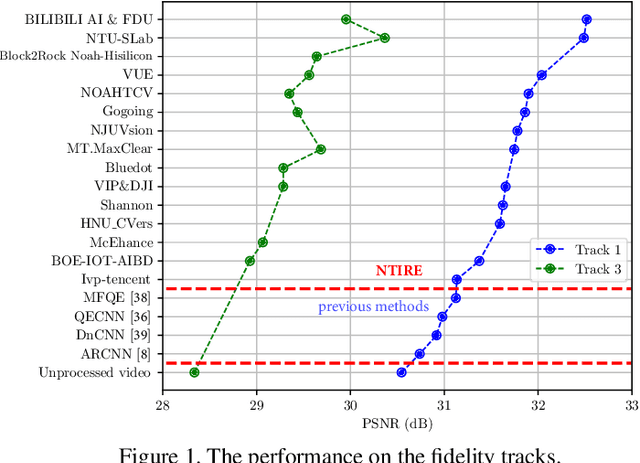
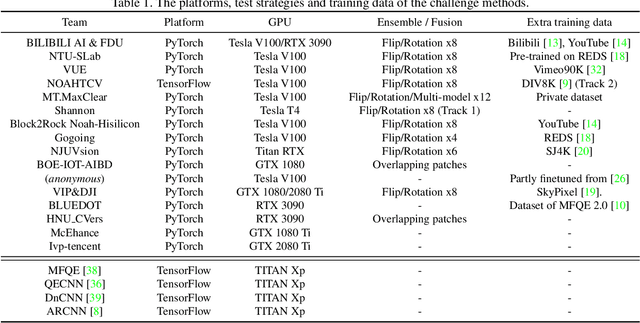
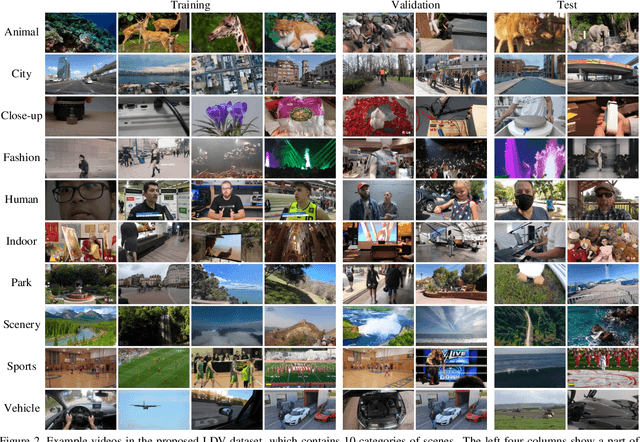
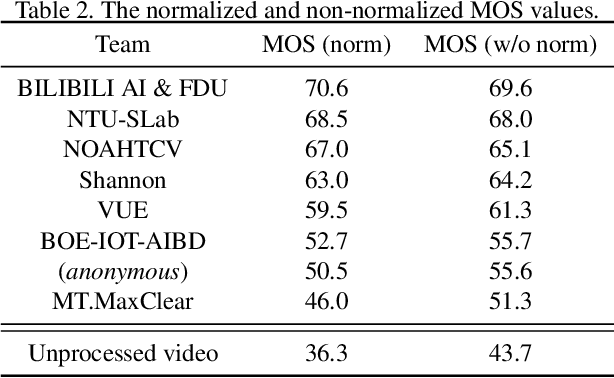
This paper introduces a novel dataset for video enhancement and studies the state-of-the-art methods of the NTIRE 2021 challenge on quality enhancement of compressed video. The challenge is the first NTIRE challenge in this direction, with three competitions, hundreds of participants and tens of proposed solutions. Our newly collected Large-scale Diverse Video (LDV) dataset is employed in the challenge. In our study, we analyze the proposed methods of the challenge and several methods in previous works on the proposed LDV dataset. We find that the NTIRE 2021 challenge advances the state-of-the-art of quality enhancement on compressed video. The proposed LDV dataset is publicly available at the homepage of the challenge: https://github.com/RenYang-home/NTIRE21_VEnh