 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Sparse to Dense: Spatio-Temporal Fusion for Multi-View 3D Human Pose Estimation with DenseWarper
May 14, 2026In multi-view 3D human pose estimation, models typically rely on images captured simultaneously from different camera views to predict a pose at a specific moment. While providing accurate spatial information, this traditional approach often overlooks the rich temporal dependencies between adjacent frames. We propose a novel 3D human pose estimation input method: the sparse interleaved input to address this. This method leverages images captured from different camera views at various time points (e.g., View 1 at time $t$ and View 2 at time $t+δ$), allowing our model to capture rich spatio-temporal information and effectively boost performance. More importantly, this approach offers two key advantages: First, it can theoretically increase the output pose frame rate by N times with N cameras, thereby breaking through single-view frame rate limitations and enhancing the temporal resolution of the production. Second, using a sparse subset of available frames, our method can reduce data redundancy and simultaneously achieve better performance. We introduce the DenseWarper model, which leverages epipolar geometry for efficient spatio-temporal heatmap exchange. We conducted extensive experiments on the Human3.6M and MPI-INF-3DHP datasets. Results demonstrate that our method, utilizing only sparse interleaved images as input, outperforms traditional dense multi-view input approaches and achieves state-of-the-art performance. The source code for this work is available at: https://github.com/lingli1724/DenseWarper-ICLR2026
Show Me the Infographic I Imagine: Intent-Aware Infographic Retrieval for Authoring Support
Apr 09, 2026While infographics have become a powerful medium for communicating data-driven stories, authoring them from scratch remains challenging, especially for novice users. Retrieving relevant exemplars from a large corpus can provide design inspiration and promote reuse, substantially lowering the barrier to infographic authoring. However, effective retrieval is difficult because users often express design intent in ambiguous natural language, while infographics embody rich and multi-faceted visual designs. As a result, keyword-based search often fails to capture design intent, and general-purpose vision-language retrieval models trained on natural images are ill-suited to the text-heavy, multi-component nature of infographics. To address these challenges, we develop an intent-aware infographic retrieval framework that better aligns user queries with infographic designs. We first conduct a formative study of how people describe infographics and derive an intent taxonomy spanning content and visual design facets. This taxonomy is then leveraged to enrich and refine free-form user queries, guiding the retrieval process with intent-specific cues. Building on the retrieved exemplars, users can adapt the designs to their own data with high-level edit intents, supported by an interactive agent that performs low-level adaptation. Both quantitative evaluations and user studies are conducted to demonstrate that our method improves retrieval quality over baseline methods while better supporting intent satisfaction and efficient infographic authoring.
NTIRE 2021 Challenge on Quality Enhancement of Compressed Video: Methods and Results
May 02, 2021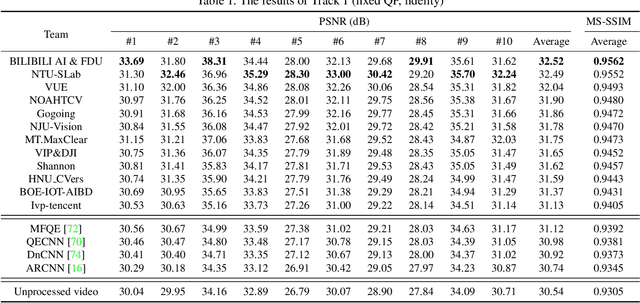
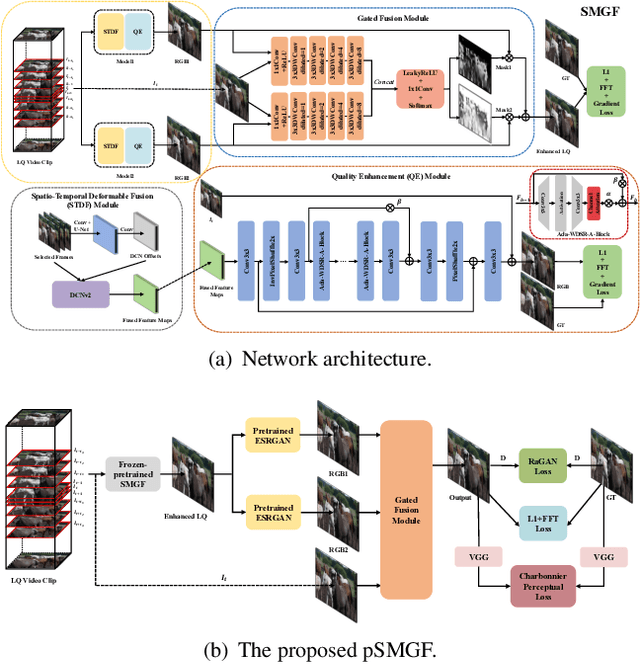
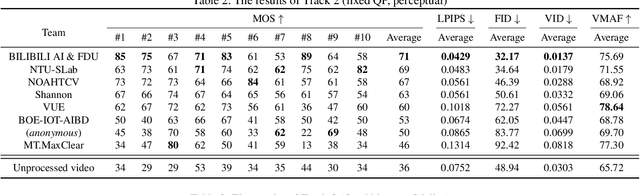
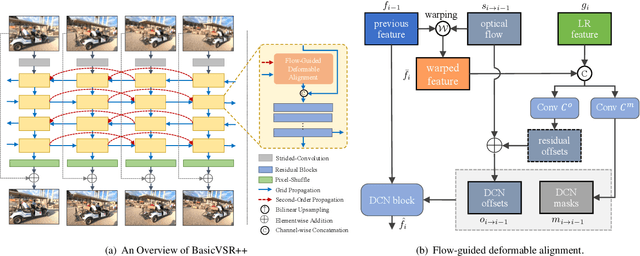
This paper reviews the first NTIRE challenge on quality enhancement of compressed video, with a focus on the proposed methods and results. In this challenge, the new Large-scale Diverse Video (LDV) dataset is employed. The challenge has three tracks. Tracks 1 and 2 aim at enhancing the videos compressed by HEVC at a fixed QP, while Track 3 is designed for enhancing the videos compressed by x265 at a fixed bit-rate. Besides, the quality enhancement of Tracks 1 and 3 targets at improving the fidelity (PSNR), and Track 2 targets at enhancing the perceptual quality. The three tracks totally attract 482 registrations. In the test phase, 12 teams, 8 teams and 11 teams submitted the final results of Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of video quality enhancement. The homepage of the challenge: https://github.com/RenYang-home/NTIRE21_VEnh