 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProCoT: Stimulating Critical Thinking and Writing of Students through Engagement with Large Language Models (LLMs)
Dec 15, 2023We introduce a novel writing method called Probing Chain of Thought (ProCoT), which prevents students from cheating using a Large Language Model (LLM), such as ChatGPT, while enhancing their active learning through such models. LLMs have disrupted education and many other feilds. For fear of students cheating, many educationists have resorted to banning their use, as their outputs can be human-like and hard to detect in some cases. These LLMs are also known for hallucinations (i.e. fake facts). We conduct studies with ProCoT in two different courses with a combined total of about 66 students. The students in each course were asked to prompt an LLM of their choice with one question from a set of four and required to affirm or refute statements in the LLM output by using peer reviewed references. The results show two things: (1) ProCoT stimulates creative/critical thinking and writing of students through engagement with LLMs when we compare the LLM solely output to ProCoT output and (2) ProCoT can prevent cheating because of clear limitations in existing LLMs when we compare students ProCoT output to LLM ProCoT output. We also discover that most students prefer to give answers in fewer words than LLMs, which are typically verbose. The average word counts for students, ChatGPT (v3.5) and Phind (v8) are 208, 391 and 383, respectively.
AfriMTE and AfriCOMET: Empowering COMET to Embrace Under-resourced African Languages
Nov 16, 2023



Despite the progress we have recorded in scaling multilingual machine translation (MT) models and evaluation data to several under-resourced African languages, it is difficult to measure accurately the progress we have made on these languages because evaluation is often performed on n-gram matching metrics like BLEU that often have worse correlation with human judgments. Embedding-based metrics such as COMET correlate better; however, lack of evaluation data with human ratings for under-resourced languages, complexity of annotation guidelines like Multidimensional Quality Metrics (MQM), and limited language coverage of multilingual encoders have hampered their applicability to African languages. In this paper, we address these challenges by creating high-quality human evaluation data with a simplified MQM guideline for error-span annotation and direct assessment (DA) scoring for 13 typologically diverse African languages. Furthermore, we develop AfriCOMET, a COMET evaluation metric for African languages by leveraging DA training data from high-resource languages and African-centric multilingual encoder (AfroXLM-Roberta) to create the state-of-the-art evaluation metric for African languages MT with respect to Spearman-rank correlation with human judgments (+0.406).
Adapting Pretrained ASR Models to Low-resource Clinical Speech using Epistemic Uncertainty-based Data Selection
Jun 03, 2023While there has been significant progress in ASR, African-accented clinical ASR has been understudied due to a lack of training datasets. Building robust ASR systems in this domain requires large amounts of annotated or labeled data, for a wide variety of linguistically and morphologically rich accents, which are expensive to create. Our study aims to address this problem by reducing annotation expenses through informative uncertainty-based data selection. We show that incorporating epistemic uncertainty into our adaptation rounds outperforms several baseline results, established using state-of-the-art (SOTA) ASR models, while reducing the required amount of labeled data, and hence reducing annotation costs. Our approach also improves out-of-distribution generalization for very low-resource accents, demonstrating the viability of our approach for building generalizable ASR models in the context of accented African clinical ASR, where training datasets are predominantly scarce.
NLP-LTU at SemEval-2023 Task 10: The Impact of Data Augmentation and Semi-Supervised Learning Techniques on Text Classification Performance on an Imbalanced Dataset
Apr 25, 2023



In this paper, we propose a methodology for task 10 of SemEval23, focusing on detecting and classifying online sexism in social media posts. The task is tackling a serious issue, as detecting harmful content on social media platforms is crucial for mitigating the harm of these posts on users. Our solution for this task is based on an ensemble of fine-tuned transformer-based models (BERTweet, RoBERTa, and DeBERTa). To alleviate problems related to class imbalance, and to improve the generalization capability of our model, we also experiment with data augmentation and semi-supervised learning. In particular, for data augmentation, we use back-translation, either on all classes, or on the underrepresented classes only. We analyze the impact of these strategies on the overall performance of the pipeline through extensive experiments. while for semi-supervised learning, we found that with a substantial amount of unlabelled, in-domain data available, semi-supervised learning can enhance the performance of certain models. Our proposed method (for which the source code is available on Github attains an F1-score of 0.8613 for sub-taskA, which ranked us 10th in the competition
Masakhane-Afrisenti at SemEval-2023 Task 12: Sentiment Analysis using Afro-centric Language Models and Adapters for Low-resource African Languages
Apr 13, 2023



AfriSenti-SemEval Shared Task 12 of SemEval-2023. The task aims to perform monolingual sentiment classification (sub-task A) for 12 African languages, multilingual sentiment classification (sub-task B), and zero-shot sentiment classification (task C). For sub-task A, we conducted experiments using classical machine learning classifiers, Afro-centric language models, and language-specific models. For task B, we fine-tuned multilingual pre-trained language models that support many of the languages in the task. For task C, we used we make use of a parameter-efficient Adapter approach that leverages monolingual texts in the target language for effective zero-shot transfer. Our findings suggest that using pre-trained Afro-centric language models improves performance for low-resource African languages. We also ran experiments using adapters for zero-shot tasks, and the results suggest that we can obtain promising results by using adapters with a limited amount of resources.
Bipol: A Novel Multi-Axes Bias Evaluation Metric with Explainability for NLP
Apr 08, 2023



We introduce bipol, a new metric with explainability, for estimating social bias in text data. Harmful bias is prevalent in many online sources of data that are used for training machine learning (ML) models. In a step to address this challenge we create a novel metric that involves a two-step process: corpus-level evaluation based on model classification and sentence-level evaluation based on (sensitive) term frequency (TF). After creating new models to detect bias along multiple axes using SotA architectures, we evaluate two popular NLP datasets (COPA and SQUAD). As additional contribution, we created a large dataset (with almost 2 million labelled samples) for training models in bias detection and make it publicly available. We also make public our codes.
Adapting to the Low-Resource Double-Bind: Investigating Low-Compute Methods on Low-Resource African Languages
Mar 29, 2023

Many natural language processing (NLP) tasks make use of massively pre-trained language models, which are computationally expensive. However, access to high computational resources added to the issue of data scarcity of African languages constitutes a real barrier to research experiments on these languages. In this work, we explore the applicability of low-compute approaches such as language adapters in the context of this low-resource double-bind. We intend to answer the following question: do language adapters allow those who are doubly bound by data and compute to practically build useful models? Through fine-tuning experiments on African languages, we evaluate their effectiveness as cost-effective approaches to low-resource African NLP. Using solely free compute resources, our results show that language adapters achieve comparable performances to massive pre-trained language models which are heavy on computational resources. This opens the door to further experimentation and exploration on full-extent of language adapters capacities.
Bipol: Multi-axes Evaluation of Bias with Explainability in Benchmark Datasets
Jan 28, 2023



We evaluate five English NLP benchmark datasets (available on the superGLUE leaderboard) for bias, along multiple axes. The datasets are the following: Boolean Question (Boolq), CommitmentBank (CB), Winograd Schema Challenge (WSC), Winogender diagnostic (AXg), and Recognising Textual Entailment (RTE). Bias can be harmful and it is known to be common in data, which ML models learn from. In order to mitigate bias in data, it is crucial to be able to estimate it objectively. We use bipol, a novel multi-axes bias metric with explainability, to quantify and explain how much bias exists in these datasets. Multilingual, multi-axes bias evaluation is not very common. Hence, we also contribute a new, large labelled Swedish bias-detection dataset, with about 2 million samples; translated from the English version. In addition, we contribute new multi-axes lexica for bias detection in Swedish. We train a SotA model on the new dataset for bias detection. We make the codes, model, and new dataset publicly available.
Separating Grains from the Chaff: Using Data Filtering to Improve Multilingual Translation for Low-Resourced African Languages
Oct 20, 2022
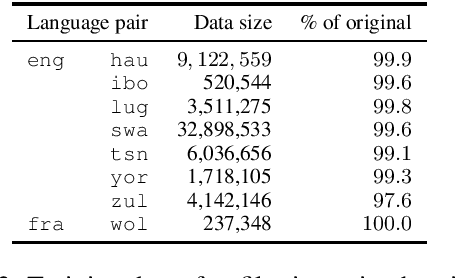
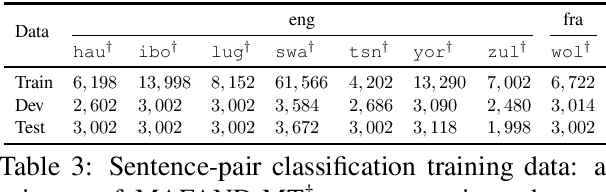
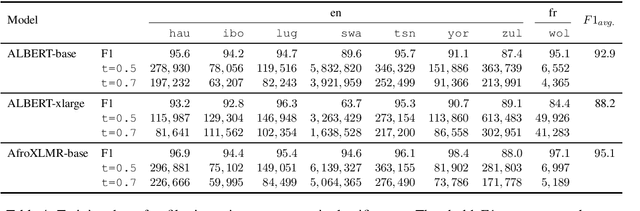
We participated in the WMT 2022 Large-Scale Machine Translation Evaluation for the African Languages Shared Task. This work describes our approach, which is based on filtering the given noisy data using a sentence-pair classifier that was built by fine-tuning a pre-trained language model. To train the classifier, we obtain positive samples (i.e. high-quality parallel sentences) from a gold-standard curated dataset and extract negative samples (i.e. low-quality parallel sentences) from automatically aligned parallel data by choosing sentences with low alignment scores. Our final machine translation model was then trained on filtered data, instead of the entire noisy dataset. We empirically validate our approach by evaluating on two common datasets and show that data filtering generally improves overall translation quality, in some cases even significantly.
T5 for Hate Speech, Augmented Data and Ensemble
Oct 11, 2022
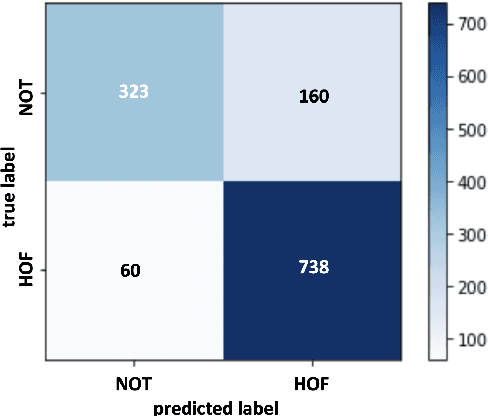
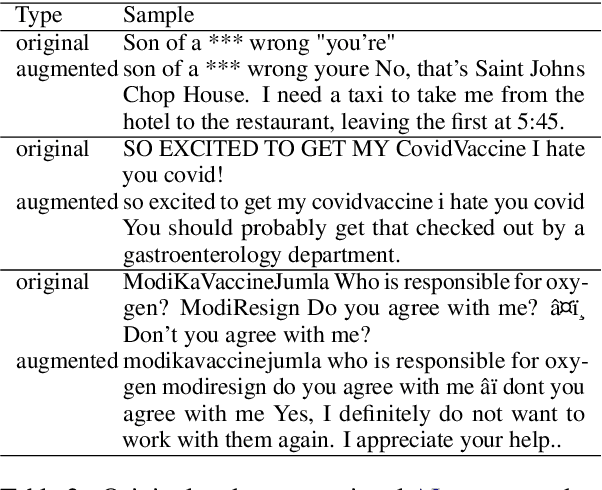
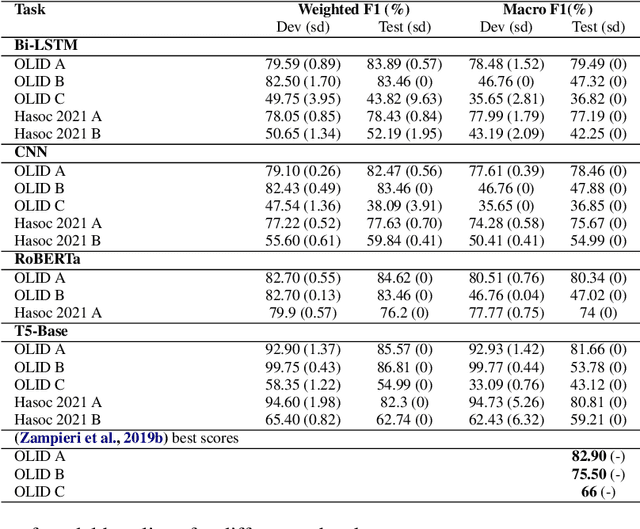
We conduct relatively extensive investigations of automatic hate speech (HS) detection using different state-of-the-art (SoTA) baselines over 11 subtasks of 6 different datasets. Our motivation is to determine which of the recent SoTA models is best for automatic hate speech detection and what advantage methods like data augmentation and ensemble may have on the best model, if any. We carry out 6 cross-task investigations. We achieve new SoTA on two subtasks - macro F1 scores of 91.73% and 53.21% for subtasks A and B of the HASOC 2020 dataset, where previous SoTA are 51.52% and 26.52%, respectively. We achieve near-SoTA on two others - macro F1 scores of 81.66% for subtask A of the OLID 2019 dataset and 82.54% for subtask A of the HASOC 2021 dataset, where SoTA are 82.9% and 83.05%, respectively. We perform error analysis and use two explainable artificial intelligence (XAI) algorithms (IG and SHAP) to reveal how two of the models (Bi-LSTM and T5) make the predictions they do by using examples. Other contributions of this work are 1) the introduction of a simple, novel mechanism for correcting out-of-class (OOC) predictions in T5, 2) a detailed description of the data augmentation methods, 3) the revelation of the poor data annotations in the HASOC 2021 dataset by using several examples and XAI (buttressing the need for better quality control), and 4) the public release of our model checkpoints and codes to foster transparency.