 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Gap Analysis between Latin and Arabic Scripts HTR
Jun 17, 2026Recent studies have shown that handwritten text recognition (HTR) systems perform worse on Arabic-script datasets than on Latin-script data. However, the reasons for this gap are still not well understood due to the lack of controlled comparisons. In this work, we present a comprehensive study of Arabic and Latin scripts HTR using a unified CRNN model for line-level HTR across nine datasets (including KHATT (Arabic), Muharaf (Arabic), NUST-UHWR (Urdu), PHTD (Persian), IAM (English), READ-2016 (German), and others) and di ferent training sizes (K in {100, 500, 1000, 2000, ..., Kfull}). Our results show the performance gap remains: it is large in low-resource settings, decreases with more data, but remains even at full scale, with a consistent difference of 5-7 CER points. We show that annotation quality matters, as many datasets contain labeling errors. Cleaning reduces error rates and narrows the gap, but does not eliminate it. In addition, we find that a fixed number of training samples provides less effective coverage in Arabic due to higher visual variability, requiring more data to learn similar representations. We compare recognition across datasets in terms of the number of text lines and the number of characters, showing an equivalence trade-off. We compare character frequency distributions across scripts and show that Arabic is significantly more heavy-tailed than Latin. Our error analysis reveals that around 30 percent of substitution errors in Arabic datasets (e.g., KHATT) are caused by confusion between visually similar characters, compared to about 15 percent in Latin-script datasets such as IAM.
TIDE: Asymmetric Neural Circuits for Stabilized Temporal Inhibitory-Excitatory Dynamics
May 19, 2026Recent Continuous Thought Machine architecture decouples internal computation from external inputs via neural dynamics, but relies on multi-layer perceptrons without stability guarantees. We propose to model neural dynamics using asymmetric Excitatory-Inhibitory (E-I) networks, which can be stabilized via principles from network theory and can be expressed as energy-based systems optimized through a game-theoretic loss. Building on this perspective, we introduce Temporal Inhibitory-Excitatory Dynamic Engine (TIDE), a neuro-inspired architecture that computes internal representations through neural dynamics stabilized by incorporating the Wilson-Cowan dynamics and lateral inhibition. TIDE balances biological realism by, for instance, using Hierarchical Receptive Fields and enforcing Dale's principle to ensure a realistic $80:20$ E-I balance ratio with an end-to-end trainable architecture. The aim of this paper is to introduce a new architecture that brings neuro-inspired learning to the forefront. We present proofs of convergence, stability, and complexity bounds, along with empirical ablation studies. Overall, TIDE surpasses CTM with under $50\%$ of the training time and improves $\texttt{top-1}$ accuracy by an average of $+1.65\%$ on ImageNet under various perturbations.
Understanding Cross-Language Transfer Improvements in Low-Resource HTR: The Role of Sequence Modeling
May 07, 2026Handwritten Text Recognition (HTR) for Arabic-script languages benefits from cross-language joint training under low-resource conditions, particularly when using CRNN-based models that combine convolutional encoders with sequence modeling. However, it remains unclear whether these improvements are better explained by shared visual representations or sequence-level dependencies. In this work, we conduct a controlled architectural study of line-level Arabic-script HTR, comparing CNN-only models with CTC decoding and CRNN models under identical single-script and multi-script training regimes. Experiments are performed on Arabic (KHATT), Urdu (NUST-UHWR), and Persian (PHTD) datasets under low-resource settings (K in {100, 500, 1000}). Our results show a clear divergence in transfer behavior: while CNN-only models exhibit limited or unstable improvements, CRNN models achieve better performance under multi-script training, particularly in the most data-constrained regimes. Focusing on transfer improvements (delta CER) rather than absolute performance, we find that cross-language improvements are associated with sequence-level modeling, while sharing visual representations learned by the CNN encoder, corresponding to similarities in character shapes across scripts, alone appears to be insufficient. This finding suggests that contextual modeling plays an important role in enabling effective transfer in low-resource scenarios, and that similar behavior may extend to other low-resource language settings.
Cross-Language Learning within Arabic Script for Low-Resource HTR
May 03, 2026Handwritten Text Recognition (HTR) under limited labeled data remains a challenging problem, particularly for Arabic-script languages. Although modern sequence-based recognizers perform well in high-resource settings, their accuracy degrades sharply as training data becomes scarce. Arabic-script languages share a common writing system with substantial character overlap, motivating cross-script training as a strategy to mitigate data scarcity. We performed experiments on Arabic, Urdu, and Persian scripts and achieved improvements over single-script baselines (new SotA especially for low-resource settings). A key finding of our experiments is that cross-script transfer is largely driven by script-level overlap rather than uniform accuracy improvements. Through a statistical character-level analysis we show that gains are structurally concentrated on characters shared across scripts, while language-specific characters exhibit limited or negative transfer. These findings provide insight into transfer dynamics in low-resource script families. Detailed results include: We conduct a controlled line-level study of cross-script joint training for Arabic-script HTR under low-resource regimes (number of samples K \in 100, 500, 1000 labeled lines) on Arabic (KHATT), Urdu (NUST-UHWR), and Persian (PHTD). A CRNN model is trained on the union of multiple related Arabic-script datasets and evaluated on individual target languages. On Persian (PHTD), joint training achieves a Character Error Rate (CER) of 9.99, surpassing previously reported results despite not using the full available training data. On an Urdu dataset (UNHD), joint training reduces CER from 17.20 to 14.45. Code and data splits are released to ensure reproducibility.1
CER-HV: A CER-Based Human-in-the-Loop Framework for Cleaning Datasets Applied to Arabic-Script HTR
Jan 23, 2026Handwritten text recognition (HTR) for Arabic-script languages still lags behind Latin-script HTR, despite recent advances in model architectures, datasets, and benchmarks. We show that data quality is a significant limiting factor in many published datasets and propose CER-HV (CER-based Ranking with Human Verification) as a framework to detect and clean label errors. CER-HV combines a CER-based noise detector, built on a carefully configured Convolutional Recurrent Neural Network (CRNN) with early stopping to avoid overfitting noisy samples, and a human-in-the-loop (HITL) step that verifies high-ranking samples. The framework reveals that several existing datasets contain previously underreported problems, including transcription, segmentation, orientation, and non-text content errors. These have been identified with up to 90 percent precision in the Muharaf and 80-86 percent in the PHTI datasets. We also show that our CRNN achieves state-of-the-art performance across five of the six evaluated datasets, reaching 8.45 percent Character Error Rate (CER) on KHATT (Arabic), 8.26 percent on PHTI (Pashto), 10.66 percent on Ajami, and 10.11 percent on Muharaf (Arabic), all without any data cleaning. We establish a new baseline of 11.3 percent CER on the PHTD (Persian) dataset. Applying CER-HV improves the evaluation CER by 0.3-0.6 percent on the cleaner datasets and 1.0-1.8 percent on the noisier ones. Although our experiments focus on documents written in an Arabic-script language, including Arabic, Persian, Urdu, Ajami, and Pashto, the framework is general and can be applied to other text recognition datasets.
From the Rock Floor to the Cloud: A Systematic Survey of State-of-the-Art NLP in Battery Life Cycle
Oct 31, 2025



We present a comprehensive systematic survey of the application of natural language processing (NLP) along the entire battery life cycle, instead of one stage or method, and introduce a novel technical language processing (TLP) framework for the EU's proposed digital battery passport (DBP) and other general battery predictions. We follow the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) method and employ three reputable databases or search engines, including Google Scholar, Institute of Electrical and Electronics Engineers Xplore (IEEE Xplore), and Scopus. Consequently, we assessed 274 scientific papers before the critical review of the final 66 relevant papers. We publicly provide artifacts of the review for validation and reproducibility. The findings show that new NLP tasks are emerging in the battery domain, which facilitate materials discovery and other stages of the life cycle. Notwithstanding, challenges remain, such as the lack of standard benchmarks. Our proposed TLP framework, which incorporates agentic AI and optimized prompts, will be apt for tackling some of the challenges.
Dual Orthogonal Guidance for Robust Diffusion-based Handwritten Text Generation
Aug 23, 2025Diffusion-based Handwritten Text Generation (HTG) approaches achieve impressive results on frequent, in-vocabulary words observed at training time and on regular styles. However, they are prone to memorizing training samples and often struggle with style variability and generation clarity. In particular, standard diffusion models tend to produce artifacts or distortions that negatively affect the readability of the generated text, especially when the style is hard to produce. To tackle these issues, we propose a novel sampling guidance strategy, Dual Orthogonal Guidance (DOG), that leverages an orthogonal projection of a negatively perturbed prompt onto the original positive prompt. This approach helps steer the generation away from artifacts while maintaining the intended content, and encourages more diverse, yet plausible, outputs. Unlike standard Classifier-Free Guidance (CFG), which relies on unconditional predictions and produces noise at high guidance scales, DOG introduces a more stable, disentangled direction in the latent space. To control the strength of the guidance across the denoising process, we apply a triangular schedule: weak at the start and end of denoising, when the process is most sensitive, and strongest in the middle steps. Experimental results on the state-of-the-art DiffusionPen and One-DM demonstrate that DOG improves both content clarity and style variability, even for out-of-vocabulary words and challenging writing styles.
Quo Vadis Handwritten Text Generation for Handwritten Text Recognition?
Aug 13, 2025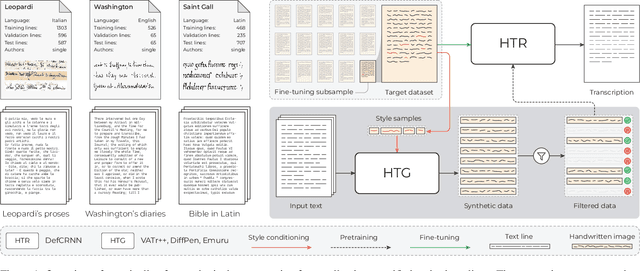


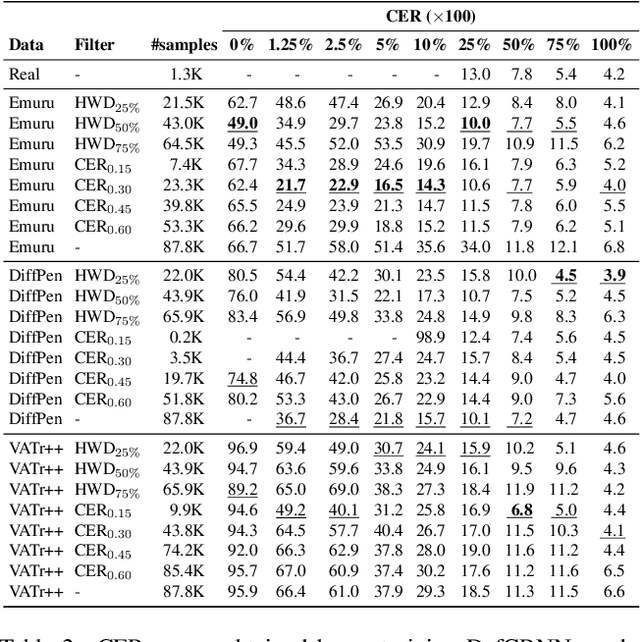
The digitization of historical manuscripts presents significant challenges for Handwritten Text Recognition (HTR) systems, particularly when dealing with small, author-specific collections that diverge from the training data distributions. Handwritten Text Generation (HTG) techniques, which generate synthetic data tailored to specific handwriting styles, offer a promising solution to address these challenges. However, the effectiveness of various HTG models in enhancing HTR performance, especially in low-resource transcription settings, has not been thoroughly evaluated. In this work, we systematically compare three state-of-the-art styled HTG models (representing the generative adversarial, diffusion, and autoregressive paradigms for HTG) to assess their impact on HTR fine-tuning. We analyze how visual and linguistic characteristics of synthetic data influence fine-tuning outcomes and provide quantitative guidelines for selecting the most effective HTG model. The results of our analysis provide insights into the current capabilities of HTG methods and highlight key areas for further improvement in their application to low-resource HTR.
Findings of MEGA: Maths Explanation with LLMs using the Socratic Method for Active Learning
Jul 16, 2025This paper presents an intervention study on the effects of the combined methods of (1) the Socratic method, (2) Chain of Thought (CoT) reasoning, (3) simplified gamification and (4) formative feedback on university students' Maths learning driven by large language models (LLMs). We call our approach Mathematics Explanations through Games by AI LLMs (MEGA). Some students struggle with Maths and as a result avoid Math-related discipline or subjects despite the importance of Maths across many fields, including signal processing. Oftentimes, students' Maths difficulties stem from suboptimal pedagogy. We compared the MEGA method to the traditional step-by-step (CoT) method to ascertain which is better by using a within-group design after randomly assigning questions for the participants, who are university students. Samples (n=60) were randomly drawn from each of the two test sets of the Grade School Math 8K (GSM8K) and Mathematics Aptitude Test of Heuristics (MATH) datasets, based on the error margin of 11%, the confidence level of 90%, and a manageable number of samples for the student evaluators. These samples were used to evaluate two capable LLMs at length (Generative Pretrained Transformer 4o (GPT4o) and Claude 3.5 Sonnet) out of the initial six that were tested for capability. The results showed that students agree in more instances that the MEGA method is experienced as better for learning for both datasets. It is even much better than the CoT (47.5% compared to 26.67%) in the more difficult MATH dataset, indicating that MEGA is better at explaining difficult Maths problems.
Agent-based Condition Monitoring Assistance with Multimodal Industrial Database Retrieval Augmented Generation
Jun 10, 2025Condition monitoring (CM) plays a crucial role in ensuring reliability and efficiency in the process industry. Although computerised maintenance systems effectively detect and classify faults, tasks like fault severity estimation, and maintenance decisions still largely depend on human expert analysis. The analysis and decision making automatically performed by current systems typically exhibit considerable uncertainty and high false alarm rates, leading to increased workload and reduced efficiency. This work integrates large language model (LLM)-based reasoning agents with CM workflows to address analyst and industry needs, namely reducing false alarms, enhancing fault severity estimation, improving decision support, and offering explainable interfaces. We propose MindRAG, a modular framework combining multimodal retrieval-augmented generation (RAG) with novel vector store structures designed specifically for CM data. The framework leverages existing annotations and maintenance work orders as surrogates for labels in a supervised learning protocol, addressing the common challenge of training predictive models on unlabelled and noisy real-world datasets. The primary contributions include: (1) an approach for structuring industry CM data into a semi-structured multimodal vector store compatible with LLM-driven workflows; (2) developing multimodal RAG techniques tailored for CM data; (3) developing practical reasoning agents capable of addressing real-world CM queries; and (4) presenting an experimental framework for integrating and evaluating such agents in realistic industrial scenarios. Preliminary results, evaluated with the help of an experienced analyst, indicate that MindRAG provide meaningful decision support for more efficient management of alarms, thereby improving the interpretability of CM systems.