 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBibleTTS: a large, high-fidelity, multilingual, and uniquely African speech corpus
Jul 07, 2022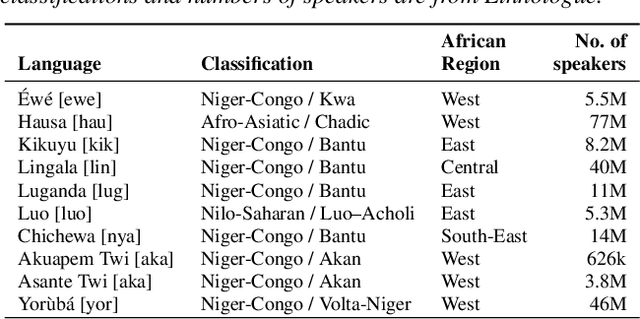
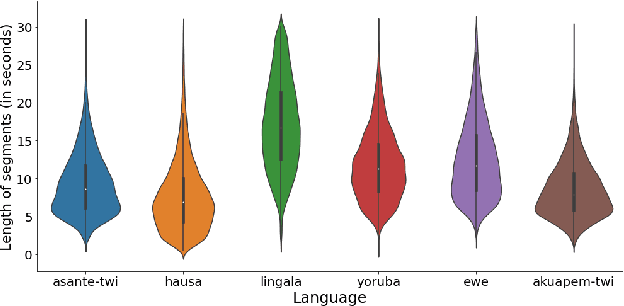
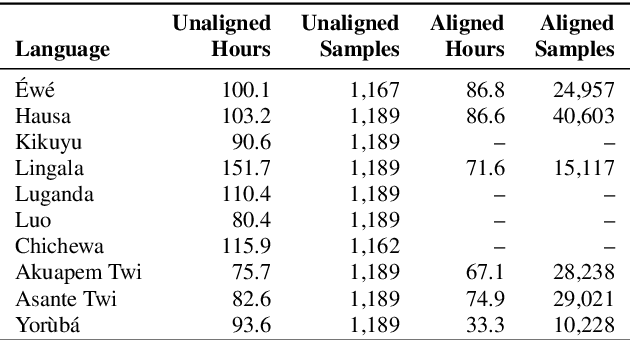
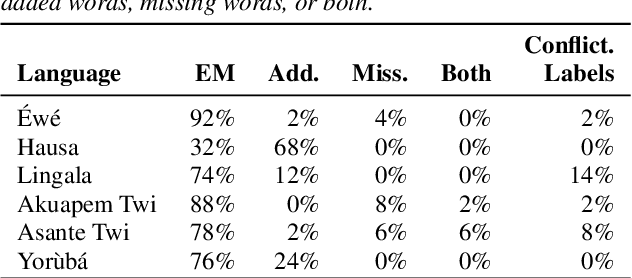
BibleTTS is a large, high-quality, open speech dataset for ten languages spoken in Sub-Saharan Africa. The corpus contains up to 86 hours of aligned, studio quality 48kHz single speaker recordings per language, enabling the development of high-quality text-to-speech models. The ten languages represented are: Akuapem Twi, Asante Twi, Chichewa, Ewe, Hausa, Kikuyu, Lingala, Luganda, Luo, and Yoruba. This corpus is a derivative work of Bible recordings made and released by the Open.Bible project from Biblica. We have aligned, cleaned, and filtered the original recordings, and additionally hand-checked a subset of the alignments for each language. We present results for text-to-speech models with Coqui TTS. The data is released under a commercial-friendly CC-BY-SA license.
Ìtàkúròso: Exploiting Cross-Lingual Transferability for Natural Language Generation of Dialogues in Low-Resource, African Languages
Apr 17, 2022
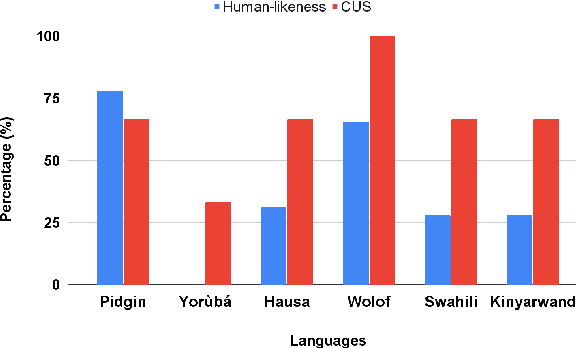
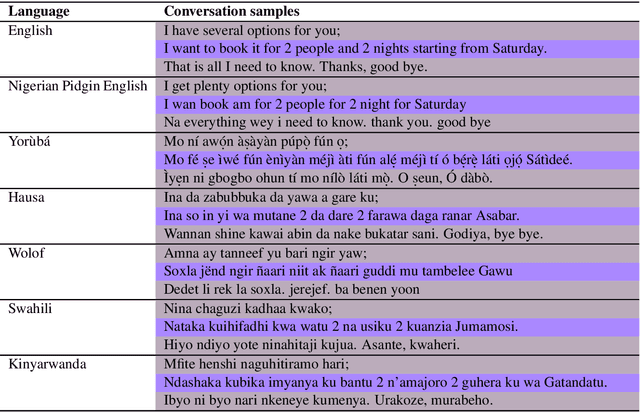
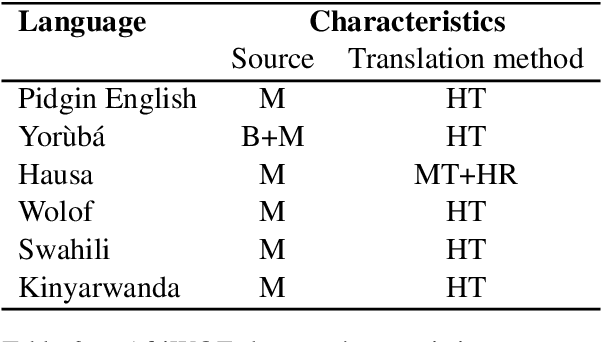
We investigate the possibility of cross-lingual transfer from a state-of-the-art (SoTA) deep monolingual model (DialoGPT) to 6 African languages and compare with 2 baselines (BlenderBot 90M, another SoTA, and a simple Seq2Seq). The languages are Swahili, Wolof, Hausa, Nigerian Pidgin English, Kinyarwanda & Yor\`ub\'a. Generation of dialogues is known to be a challenging task for many reasons. It becomes more challenging for African languages which are low-resource in terms of data. Therefore, we translate a small portion of the English multi-domain MultiWOZ dataset for each target language. Besides intrinsic evaluation (i.e. perplexity), we conduct human evaluation of single-turn conversations by using majority votes and measure inter-annotator agreement (IAA). The results show that the hypothesis that deep monolingual models learn some abstractions that generalise across languages holds. We observe human-like conversations in 5 out of the 6 languages. It, however, applies to different degrees in different languages, which is expected. The language with the most transferable properties is the Nigerian Pidgin English, with a human-likeness score of 78.1%, of which 34.4% are unanimous. The main contributions of this paper include the representation (through the provision of high-quality dialogue data) of under-represented African languages and demonstrating the cross-lingual transferability hypothesis for dialogue systems. We also provide the datasets and host the model checkpoints/demos on the HuggingFace hub for public access.
MasakhaNER: Named Entity Recognition for African Languages
Mar 22, 2021

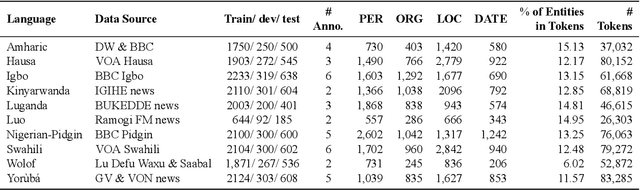
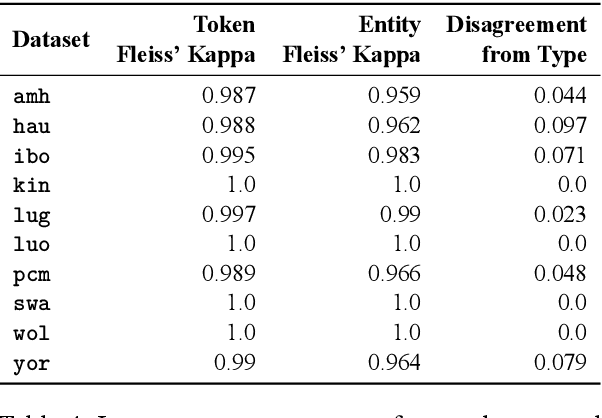
We take a step towards addressing the under-representation of the African continent in NLP research by creating the first large publicly available high-quality dataset for named entity recognition (NER) in ten African languages, bringing together a variety of stakeholders. We detail characteristics of the languages to help researchers understand the challenges that these languages pose for NER. We analyze our datasets and conduct an extensive empirical evaluation of state-of-the-art methods across both supervised and transfer learning settings. We release the data, code, and models in order to inspire future research on African NLP.