 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSENTINEL: Failure-Driven Reinforcement Learning for Training Tool-Using Language Model Agents
Jun 11, 2026Language model agents are increasingly effective in solving realistic tasks through multi-turn tool use. However, training reliable tool-using agents remains challenging in practice. While reinforcement learning provides an on-policy paradigm for improving agents from their own environment interactions, its effectiveness depends heavily on the training task distribution. When tasks are fixed before training, the task distribution can become increasingly mismatched with the policy's evolving capabilities, causing many rollouts to be spent on uninformative tasks. We propose SENTINEL, a failure-driven reinforcement learning framework that turns the Solver's rollout failures into targeted training tasks. SENTINEL follows a Controller--Proposer--Solver loop: the Controller analyzes failed trajectories and summarizes recurring error patterns, the Proposer generates executable tasks that stress these weaknesses, and the Solver is trained on the targeted tasks. On Tau2-Bench Retail with Qwen3-4B-Thinking-2507, SENTINEL improves Pass\^{}1 from 66.4 to 74.9 and outperforms RL on general synthetic tasks across Pass\^{}k metrics. These results demonstrate that model failures provide an effective and scalable source of targeted training signal for improving tool-using language model agents.
Adaptive Auto-Harness: Sustained Self-Improvement for Agentic System Deployment on Open-Ended Task Streams
Jun 01, 2026Auto-harness systems such as A-Evolve, GEPA, and Meta-Harness improve LLM agents by optimizing prompts, skills, tools, memories, and supporting infrastructure from execution feedback, but they are typically evaluated on fixed offline benchmarks. Real deployments instead present open-ended task streams: histories grow without a fixed endpoint, heterogeneous tasks require different harnesses, and problem distributions shift over time. These challenges make a single repeatedly and densely updated harness brittle, causing performance degradation as accuracy peaks early and then declines. This motivates sustained harness construction with task-wise adaptation. We introduce Adaptive Auto-Harness, a framework and system for such streams. The framework decomposes the gap to an oracle harness into evolution loss and adaptation loss. The system addresses these losses with a stateful multi-agent evolver, a harness tree with solve-time routing, and human-steering hooks for cases where history lacks the needed signal. Across prediction-market, security-competition, and event-forecasting streams, Adaptive Auto-Harness outperforms five existing auto-harness baselines and ablations attribute gains to better construction, routing, or targeted human steering. Code is available in https://github.com/A-EVO-Lab/AdaptiveHarness .
Harness Updating Is Not Harness Benefit: Disentangling Evolution Capabilities in Self-Evolving LLM Agents
May 28, 2026LLM agents are increasingly deployed as systems built around editable external harnesses, including prompts, skills, memories and tools, that shape task execution without changing model parameters. Harness self-evolution adapts such agents by updating these harnesses from execution evidence. Yet it remains unclear whether a model's base capability in task-solving predicts its capabilities in harness self-evolution: which models produce useful harness updates, and which actually benefit from them? We analyze two harness self-evolution capabilities: (i) harness-updating, the capability to produce useful persistent harness updates from execution evidence; (ii) harness-benefit, the capability to benefit from updated harnesses during task solving. Our analysis reveals two findings. First, harness-updating is flat in base capability: models from different capability tiers produce harness updates that lead to surprisingly similar gains; even Qwen3.5-9B's updates yield gains comparable to those of Claude Opus~4.6. Second, harness-benefit is non-monotonic in base capability: weak-tier models benefit little from updated harnesses, mid-tier models benefit most, and strong-tier models benefit less than mid-tier. We trace low gains at the weak tier to two failure modes: weak-tier models may fail to activate relevant harness artifacts, or activate them but fail to follow them faithfully. These findings suggest investing capability budget in the task-solving agent rather than the evolver, and targeting harness invocation and long-horizon instruction following in agent training. Our source code is publicly available at https://github.com/A-EVO-Lab/a-evolve/tree/release/harness-evolution.
Trajectory2Task: Training Robust Tool-Calling Agents with Synthesized Yet Verifiable Data for Complex User Intents
Jan 28, 2026Tool-calling agents are increasingly deployed in real-world customer-facing workflows. Yet most studies on tool-calling agents focus on idealized settings with general, fixed, and well-specified tasks. In real-world applications, user requests are often (1) ambiguous, (2) changing over time, or (3) infeasible due to policy constraints, and training and evaluation data that cover these diverse, complex interaction patterns remain under-represented. To bridge the gap, we present Trajectory2Task, a verifiable data generation pipeline for studying tool use at scale under three realistic user scenarios: ambiguous intent, changing intent, and infeasible intents. The pipeline first conducts multi-turn exploration to produce valid tool-call trajectories. It then converts these trajectories into user-facing tasks with controlled intent adaptations. This process yields verifiable task that support closed-loop evaluation and training. We benchmark seven state-of-the-art LLMs on the generated complex user scenario tasks and observe frequent failures. Finally, using successful trajectories obtained from task rollouts, we fine-tune lightweight LLMs and find consistent improvements across all three conditions, along with better generalization to unseen tool-use domains, indicating stronger general tool-calling ability.
ODKE+: Ontology-Guided Open-Domain Knowledge Extraction with LLMs
Sep 04, 2025



Knowledge graphs (KGs) are foundational to many AI applications, but maintaining their freshness and completeness remains costly. We present ODKE+, a production-grade system that automatically extracts and ingests millions of open-domain facts from web sources with high precision. ODKE+ combines modular components into a scalable pipeline: (1) the Extraction Initiator detects missing or stale facts, (2) the Evidence Retriever collects supporting documents, (3) hybrid Knowledge Extractors apply both pattern-based rules and ontology-guided prompting for large language models (LLMs), (4) a lightweight Grounder validates extracted facts using a second LLM, and (5) the Corroborator ranks and normalizes candidate facts for ingestion. ODKE+ dynamically generates ontology snippets tailored to each entity type to align extractions with schema constraints, enabling scalable, type-consistent fact extraction across 195 predicates. The system supports batch and streaming modes, processing over 9 million Wikipedia pages and ingesting 19 million high-confidence facts with 98.8% precision. ODKE+ significantly improves coverage over traditional methods, achieving up to 48% overlap with third-party KGs and reducing update lag by 50 days on average. Our deployment demonstrates that LLM-based extraction, grounded in ontological structure and verification workflows, can deliver trustworthiness, production-scale knowledge ingestion with broad real-world applicability. A recording of the system demonstration is included with the submission and is also available at https://youtu.be/UcnE3_GsTWs.
ConvKGYarn: Spinning Configurable and Scalable Conversational Knowledge Graph QA datasets with Large Language Models
Aug 12, 2024



The rapid advancement of Large Language Models (LLMs) and conversational assistants necessitates dynamic, scalable, and configurable conversational datasets for training and evaluation. These datasets must accommodate diverse user interaction modes, including text and voice, each presenting unique modeling challenges. Knowledge Graphs (KGs), with their structured and evolving nature, offer an ideal foundation for current and precise knowledge. Although human-curated KG-based conversational datasets exist, they struggle to keep pace with the rapidly changing user information needs. We present ConvKGYarn, a scalable method for generating up-to-date and configurable conversational KGQA datasets. Qualitative psychometric analyses confirm our method can generate high-quality datasets rivaling a popular conversational KGQA dataset while offering it at scale and covering a wide range of human-interaction configurations. We showcase its utility by testing LLMs on diverse conversations - exploring model behavior on conversational KGQA sets with different configurations grounded in the same KG fact set. Our results highlight the ability of ConvKGYarn to improve KGQA foundations and evaluate parametric knowledge of LLMs, thus offering a robust solution to the constantly evolving landscape of conversational assistants.
APE: Active Learning-based Tooling for Finding Informative Few-shot Examples for LLM-based Entity Matching
Jul 29, 2024
Prompt engineering is an iterative procedure often requiring extensive manual effort to formulate suitable instructions for effectively directing large language models (LLMs) in specific tasks. Incorporating few-shot examples is a vital and effective approach to providing LLMs with precise instructions, leading to improved LLM performance. Nonetheless, identifying the most informative demonstrations for LLMs is labor-intensive, frequently entailing sifting through an extensive search space. In this demonstration, we showcase a human-in-the-loop tool called APE (Active Prompt Engineering) designed for refining prompts through active learning. Drawing inspiration from active learning, APE iteratively selects the most ambiguous examples for human feedback, which will be transformed into few-shot examples within the prompt. The demo recording can be found with the submission or be viewed at https://youtu.be/OwQ6MQx53-Y.
FLEEK: Factual Error Detection and Correction with Evidence Retrieved from External Knowledge
Oct 26, 2023



Detecting factual errors in textual information, whether generated by large language models (LLM) or curated by humans, is crucial for making informed decisions. LLMs' inability to attribute their claims to external knowledge and their tendency to hallucinate makes it difficult to rely on their responses. Humans, too, are prone to factual errors in their writing. Since manual detection and correction of factual errors is labor-intensive, developing an automatic approach can greatly reduce human effort. We present FLEEK, a prototype tool that automatically extracts factual claims from text, gathers evidence from external knowledge sources, evaluates the factuality of each claim, and suggests revisions for identified errors using the collected evidence. Initial empirical evaluation on fact error detection (77-85\% F1) shows the potential of FLEEK. A video demo of FLEEK can be found at https://youtu.be/NapJFUlkPdQ.
Few-Shot Character Understanding in Movies as an Assessment to Meta-Learning of Theory-of-Mind
Nov 09, 2022When reading a story, humans can rapidly understand new fictional characters with a few observations, mainly by drawing analogy to fictional and real people they met before in their lives. This reflects the few-shot and meta-learning essence of humans' inference of characters' mental states, i.e., humans' theory-of-mind (ToM), which is largely ignored in existing research. We fill this gap with a novel NLP benchmark, TOM-IN-AMC, the first assessment of models' ability of meta-learning of ToM in a realistic narrative understanding scenario. Our benchmark consists of $\sim$1,000 parsed movie scripts for this purpose, each corresponding to a few-shot character understanding task; and requires models to mimic humans' ability of fast digesting characters with a few starting scenes in a new movie. Our human study verified that humans can solve our problem by inferring characters' mental states based on their previously seen movies; while the state-of-the-art metric-learning and meta-learning approaches adapted to our task lags 30% behind.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022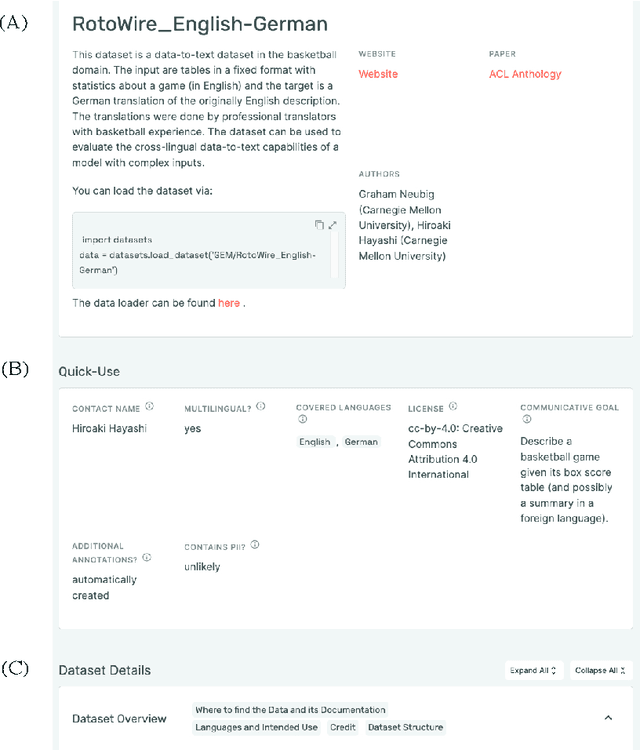

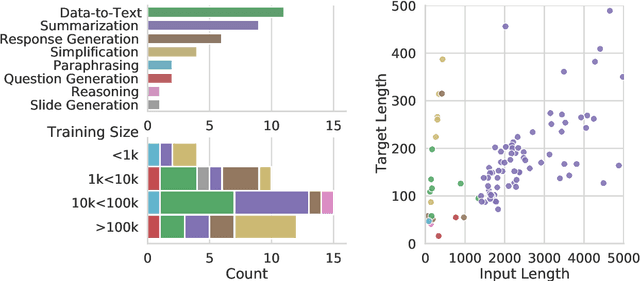

Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.