 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSRS-Stories: Vocabulary-constrained multilingual story generation for language learning
Dec 20, 2025



In this paper, we use large language models to generate personalized stories for language learners, using only the vocabulary they know. The generated texts are specifically written to teach the user new vocabulary by simply reading stories where it appears in context, while at the same time seamlessly reviewing recently learned vocabulary. The generated stories are enjoyable to read and the vocabulary reviewing/learning is optimized by a Spaced Repetition System. The experiments are conducted in three languages: English, Chinese and Polish, evaluating three story generation methods and three strategies for enforcing lexical constraints. The results show that the generated stories are more grammatical, coherent, and provide better examples of word usage than texts generated by the standard constrained beam search approach
Leveraging Large Language Models for Building Interpretable Rule-Based Data-to-Text Systems
Feb 28, 2025



We introduce a simple approach that uses a large language model (LLM) to automatically implement a fully interpretable rule-based data-to-text system in pure Python. Experimental evaluation on the WebNLG dataset showed that such a constructed system produces text of better quality (according to the BLEU and BLEURT metrics) than the same LLM prompted to directly produce outputs, and produces fewer hallucinations than a BART language model fine-tuned on the same data. Furthermore, at runtime, the approach generates text in a fraction of the processing time required by neural approaches, using only a single CPU
Evaluating Text Style Transfer Evaluation: Are There Any Reliable Metrics?
Feb 07, 2025Text Style Transfer (TST) is the task of transforming a text to reflect a particular style while preserving its original content. Evaluating TST outputs is a multidimensional challenge, requiring the assessment of style transfer accuracy, content preservation, and naturalness. Using human evaluation is ideal but costly, same as in other natural language processing (NLP) tasks, however, automatic metrics for TST have not received as much attention as metrics for, e.g., machine translation or summarization. In this paper, we examine both set of existing and novel metrics from broader NLP tasks for TST evaluation, focusing on two popular subtasks-sentiment transfer and detoxification-in a multilingual context comprising English, Hindi, and Bengali. By conducting meta-evaluation through correlation with human judgments, we demonstrate the effectiveness of these metrics when used individually and in ensembles. Additionally, we investigate the potential of Large Language Models (LLMs) as tools for TST evaluation. Our findings highlight that certain advanced NLP metrics and experimental-hybrid-techniques, provide better insights than existing TST metrics for delivering more accurate, consistent, and reproducible TST evaluations.
Do Large Language Models with Reasoning and Acting Meet the Needs of Task-Oriented Dialogue?
Dec 02, 2024



Large language models (LLMs) gained immense popularity due to their impressive capabilities in unstructured conversations. However, they underperform compared to previous approaches in task-oriented dialogue (TOD), wherein reasoning and accessing external information are crucial. Empowering LLMs with advanced prompting strategies such as reasoning and acting (ReAct) has shown promise in solving complex tasks traditionally requiring reinforcement learning. In this work, we apply the ReAct strategy to guide LLMs performing TOD. We evaluate ReAct-based LLMs (ReAct-LLMs) both in simulation and with real users. While ReAct-LLMs seem to underperform state-of-the-art approaches in simulation, human evaluation indicates higher user satisfaction rate compared to handcrafted systems despite having a lower success rate.
Faithful and Plausible Natural Language Explanations for Image Classification: A Pipeline Approach
Jul 30, 2024



Existing explanation methods for image classification struggle to provide faithful and plausible explanations. This paper addresses this issue by proposing a post-hoc natural language explanation method that can be applied to any CNN-based classifier without altering its training process or affecting predictive performance. By analysing influential neurons and the corresponding activation maps, the method generates a faithful description of the classifier's decision process in the form of a structured meaning representation, which is then converted into text by a language model. Through this pipeline approach, the generated explanations are grounded in the neural network architecture, providing accurate insight into the classification process while remaining accessible to non-experts. Experimental results show that the NLEs constructed by our method are significantly more plausible and faithful. In particular, user interventions in the neural network structure (masking of neurons) are three times more effective than the baselines.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022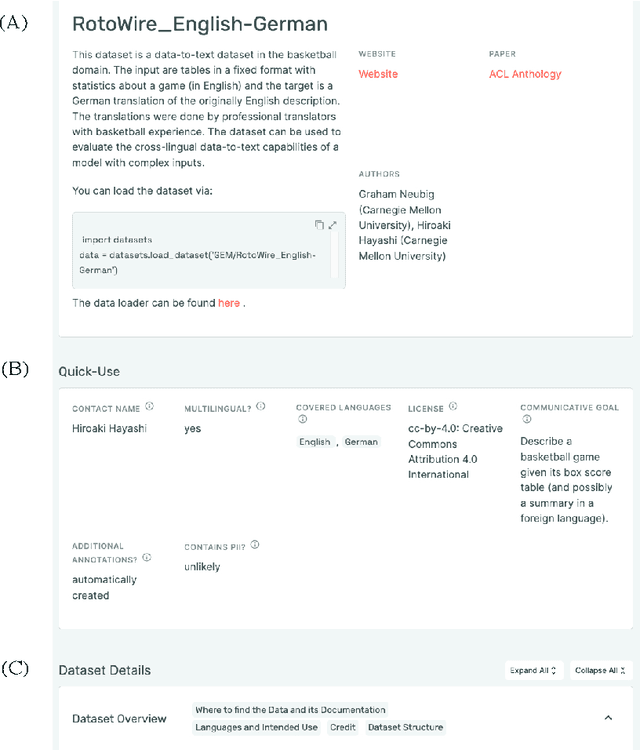


Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
Improving Context Modelling in Multimodal Dialogue Generation
Oct 20, 2018
In this work, we investigate the task of textual response generation in a multimodal task-oriented dialogue system. Our work is based on the recently released Multimodal Dialogue (MMD) dataset (Saha et al., 2017) in the fashion domain. We introduce a multimodal extension to the Hierarchical Recurrent Encoder-Decoder (HRED) model and show that this extension outperforms strong baselines in terms of text-based similarity metrics. We also showcase the shortcomings of current vision and language models by performing an error analysis on our system's output.
A Knowledge-Grounded Multimodal Search-Based Conversational Agent
Oct 20, 2018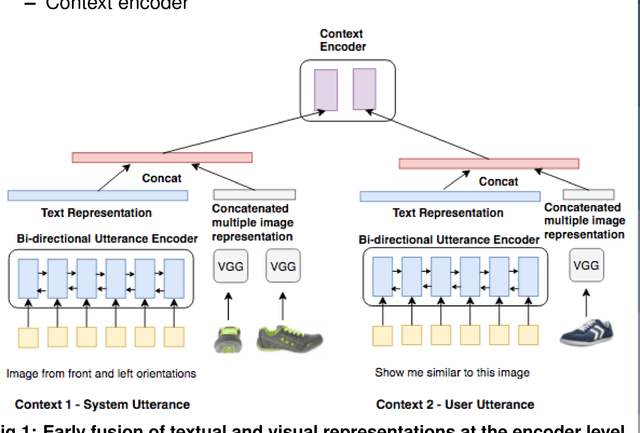
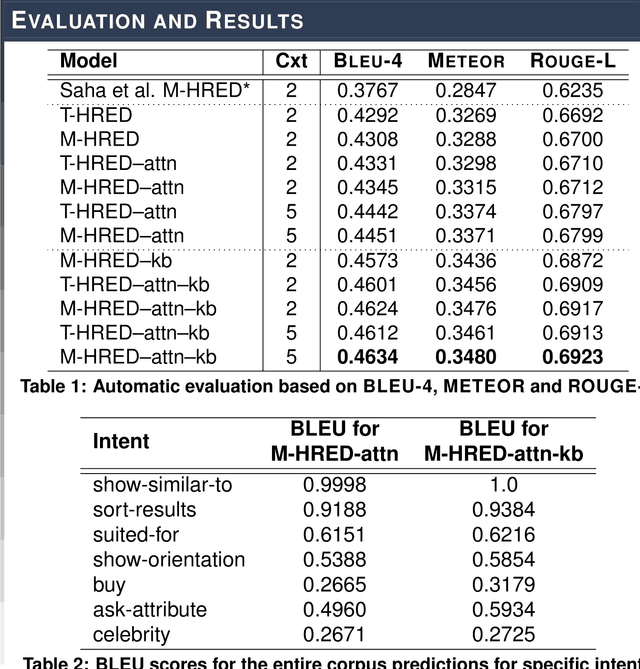
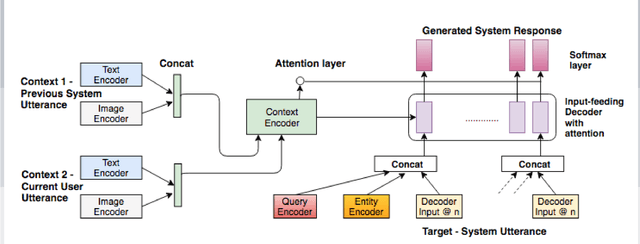
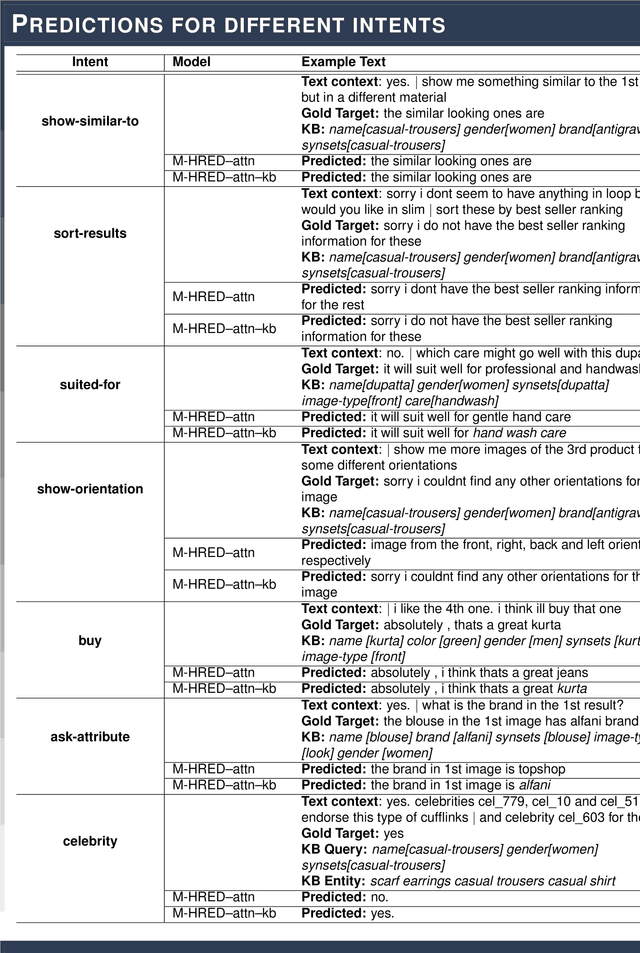
Multimodal search-based dialogue is a challenging new task: It extends visually grounded question answering systems into multi-turn conversations with access to an external database. We address this new challenge by learning a neural response generation system from the recently released Multimodal Dialogue (MMD) dataset (Saha et al., 2017). We introduce a knowledge-grounded multimodal conversational model where an encoded knowledge base (KB) representation is appended to the decoder input. Our model substantially outperforms strong baselines in terms of text-based similarity measures (over 9 BLEU points, 3 of which are solely due to the use of additional information from the KB.