 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Abstraction from Grounded Experience for Plan-Guided Policy Refinement
Nov 08, 2025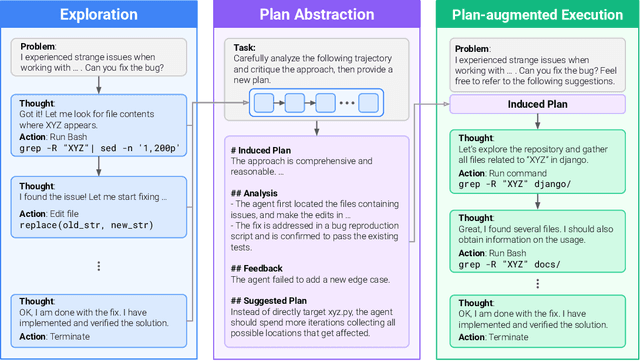

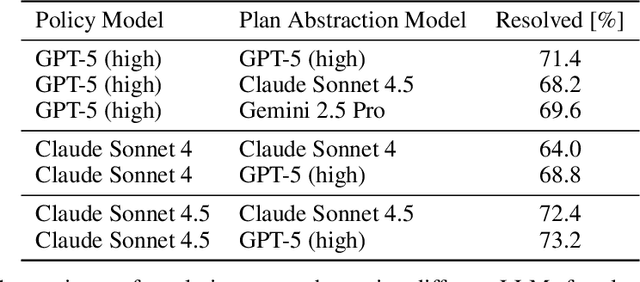
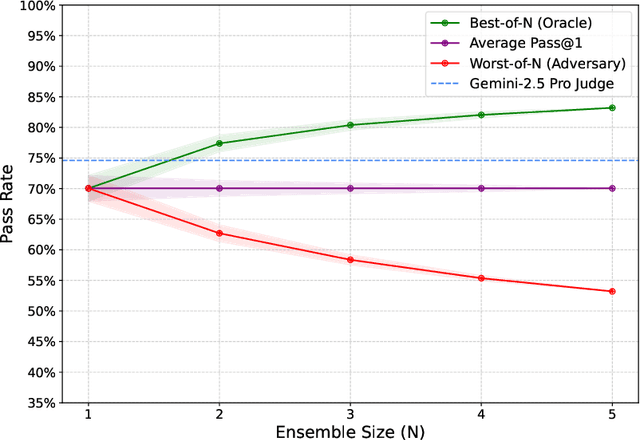
Large language model (LLM) based agents are increasingly used to tackle software engineering tasks that require multi-step reasoning and code modification, demonstrating promising yet limited performance. However, most existing LLM agents typically operate within static execution frameworks, lacking a principled mechanism to learn and self-improve from their own experience and past rollouts. As a result, their performance remains bounded by the initial framework design and the underlying LLM's capabilities. We propose Self-Abstraction from Grounded Experience (SAGE), a framework that enables agents to learn from their own task executions and refine their behavior through self-abstraction. After an initial rollout, the agent induces a concise plan abstraction from its grounded experience, distilling key steps, dependencies, and constraints. This learned abstraction is then fed back as contextual guidance, refining the agent's policy and supporting more structured, informed subsequent executions. Empirically, SAGE delivers consistent performance gains across diverse LLM backbones and agent architectures. Notably, it yields a 7.2% relative performance improvement over the strong Mini-SWE-Agent baseline when paired with the GPT-5 (high) backbone. SAGE further achieves strong overall performance on SWE-Bench Verified benchmark, reaching 73.2% and 74% Pass@1 resolve rates with the Mini-SWE-Agent and OpenHands CodeAct agent framework, respectively.
LLMs Get Lost In Multi-Turn Conversation
May 09, 2025Large Language Models (LLMs) are conversational interfaces. As such, LLMs have the potential to assist their users not only when they can fully specify the task at hand, but also to help them define, explore, and refine what they need through multi-turn conversational exchange. Although analysis of LLM conversation logs has confirmed that underspecification occurs frequently in user instructions, LLM evaluation has predominantly focused on the single-turn, fully-specified instruction setting. In this work, we perform large-scale simulation experiments to compare LLM performance in single- and multi-turn settings. Our experiments confirm that all the top open- and closed-weight LLMs we test exhibit significantly lower performance in multi-turn conversations than single-turn, with an average drop of 39% across six generation tasks. Analysis of 200,000+ simulated conversations decomposes the performance degradation into two components: a minor loss in aptitude and a significant increase in unreliability. We find that LLMs often make assumptions in early turns and prematurely attempt to generate final solutions, on which they overly rely. In simpler terms, we discover that *when LLMs take a wrong turn in a conversation, they get lost and do not recover*.
CLOVER: A Test Case Generation Benchmark with Coverage, Long-Context, and Verification
Feb 12, 2025Software testing is a critical aspect of software development, yet generating test cases remains a routine task for engineers. This paper presents a benchmark, CLOVER, to evaluate models' capabilities in generating and completing test cases under specific conditions. Spanning from simple assertion completions to writing test cases that cover specific code blocks across multiple files, these tasks are based on 12 python repositories, analyzing 845 problems with context lengths ranging from 4k to 128k tokens. Utilizing code testing frameworks, we propose a method to construct retrieval contexts using coverage information. While models exhibit comparable performance with short contexts, notable differences emerge with 16k contexts. Notably, models like GPT-4o and Claude 3.5 can effectively leverage relevant snippets; however, all models score below 35\% on the complex Task III, even with the oracle context provided, underscoring the benchmark's significance and the potential for model improvement. The benchmark is containerized for code execution across tasks, and we will release the code, data, and construction methodologies.
XGen-7B Technical Report
Sep 07, 2023Large Language Models (LLMs) have become ubiquitous across various domains, transforming the way we interact with information and conduct research. However, most high-performing LLMs remain confined behind proprietary walls, hindering scientific progress. Most open-source LLMs, on the other hand, are limited in their ability to support longer sequence lengths, which is a key requirement for many tasks that require inference over an input context. To address this, we have trained XGen, a series of 7B parameter models on up to 8K sequence length for up to 1.5T tokens. We have also finetuned the XGen models on public-domain instructional data, creating their instruction-tuned counterparts (XGen-Inst). We open-source our models for both research advancements and commercial applications. Our evaluation on standard benchmarks shows that XGen models achieve comparable or better results when compared with state-of-the-art open-source LLMs. Our targeted evaluation on long sequence modeling tasks shows the benefits of our 8K-sequence models over 2K-sequence open-source LLMs.
CodeGen2: Lessons for Training LLMs on Programming and Natural Languages
May 03, 2023



Large language models (LLMs) have demonstrated remarkable abilities in representation learning for program synthesis and understanding tasks. The quality of the learned representations appears to be dictated by the neural scaling laws as a function of the number of model parameters and observations, while imposing upper bounds on the model performance by the amount of available data and compute, which is costly. In this study, we attempt to render the training of LLMs for program synthesis more efficient by unifying four key components: (1) model architectures, (2) learning methods, (3) infill sampling, and, (4) data distributions. Specifically, for the model architecture, we attempt to unify encoder and decoder-based models into a single prefix-LM. For learning methods, (i) causal language modeling, (ii) span corruption, (iii) infilling are unified into a simple learning algorithm. For infill sampling, we explore the claim of a "free lunch" hypothesis. For data distributions, the effect of a mixture distribution of programming and natural languages on model performance is explored. We conduct a comprehensive series of empirical experiments on 1B LLMs, for which failures and successes of this exploration are distilled into four lessons. We will provide a final recipe for training and release CodeGen2 models in size 1B, 3.7B, 7B, and, 16B parameters, along with the training framework as open-source: https://github.com/salesforce/CodeGen2.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022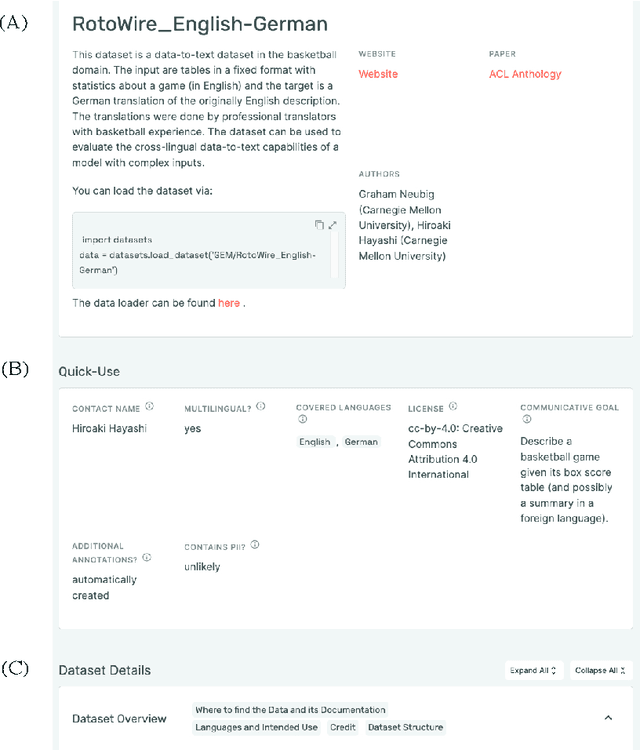

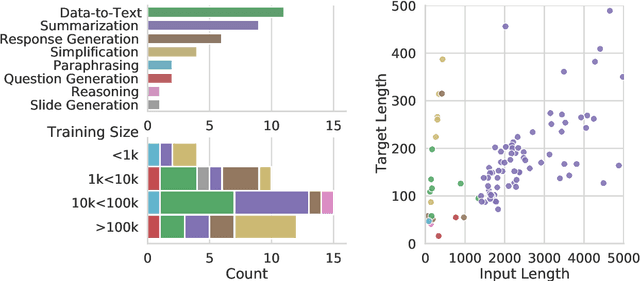

Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.
A Conversational Paradigm for Program Synthesis
Mar 30, 2022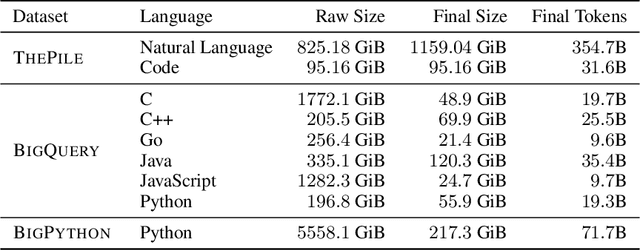
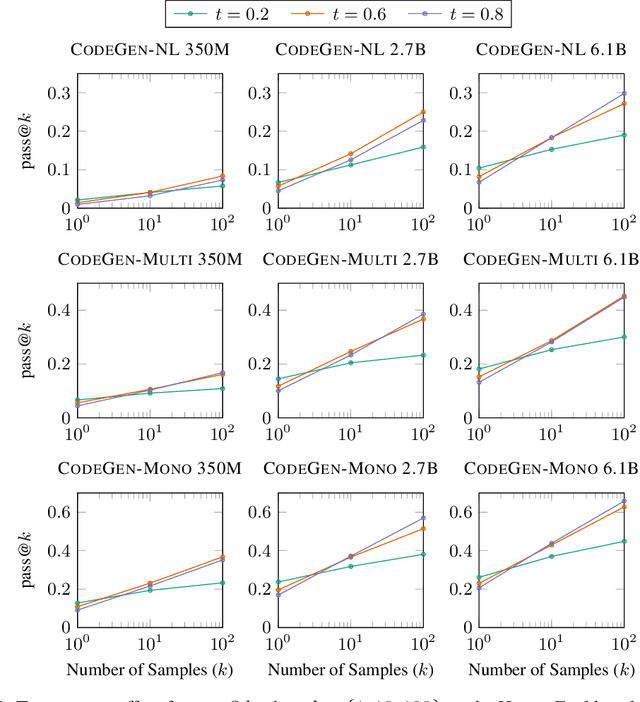
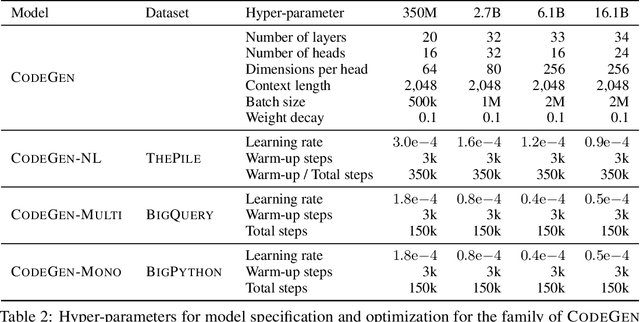
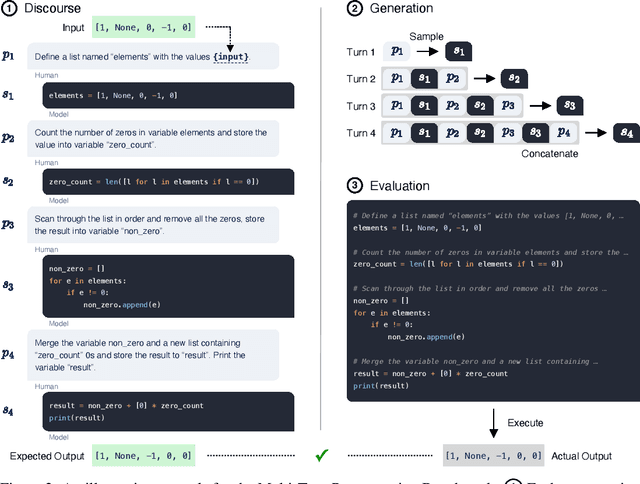
Program synthesis strives to generate a computer program as a solution to a given problem specification. We propose a conversational program synthesis approach via large language models, which addresses the challenges of searching over a vast program space and user intent specification faced in prior approaches. Our new approach casts the process of writing a specification and program as a multi-turn conversation between a user and a system. It treats program synthesis as a sequence prediction problem, in which the specification is expressed in natural language and the desired program is conditionally sampled. We train a family of large language models, called CodeGen, on natural language and programming language data. With weak supervision in the data and the scaling up of data size and model size, conversational capacities emerge from the simple autoregressive language modeling. To study the model behavior on conversational program synthesis, we develop a multi-turn programming benchmark (MTPB), where solving each problem requires multi-step synthesis via multi-turn conversation between the user and the model. Our findings show the emergence of conversational capabilities and the effectiveness of the proposed conversational program synthesis paradigm. In addition, our model CodeGen (with up to 16B parameters trained on TPU-v4) outperforms OpenAI's Codex on the HumanEval benchmark. We make the training library JaxFormer including checkpoints available as open source contribution: https://github.com/salesforce/CodeGen.
DEEP: DEnoising Entity Pre-training for Neural Machine Translation
Nov 14, 2021
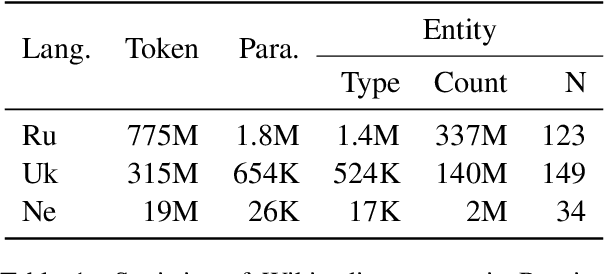
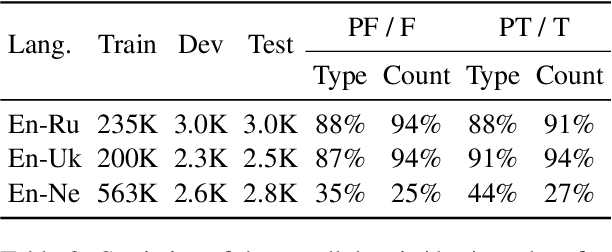
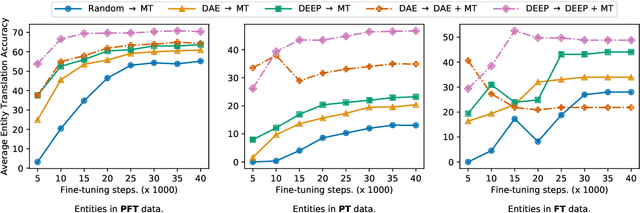
It has been shown that machine translation models usually generate poor translations for named entities that are infrequent in the training corpus. Earlier named entity translation methods mainly focus on phonetic transliteration, which ignores the sentence context for translation and is limited in domain and language coverage. To address this limitation, we propose DEEP, a DEnoising Entity Pre-training method that leverages large amounts of monolingual data and a knowledge base to improve named entity translation accuracy within sentences. Besides, we investigate a multi-task learning strategy that finetunes a pre-trained neural machine translation model on both entity-augmented monolingual data and parallel data to further improve entity translation. Experimental results on three language pairs demonstrate that \method results in significant improvements over strong denoising auto-encoding baselines, with a gain of up to 1.3 BLEU and up to 9.2 entity accuracy points for English-Russian translation.
Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
Jul 28, 2021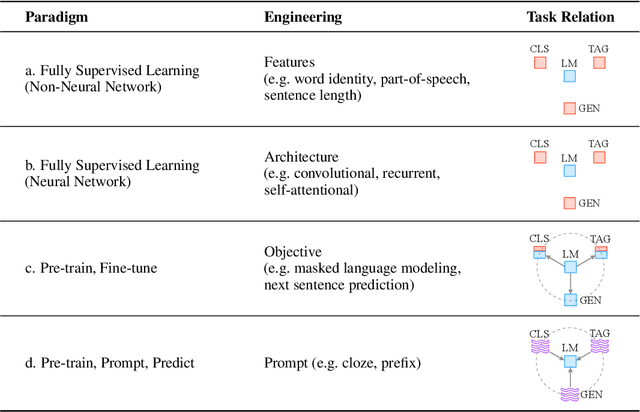
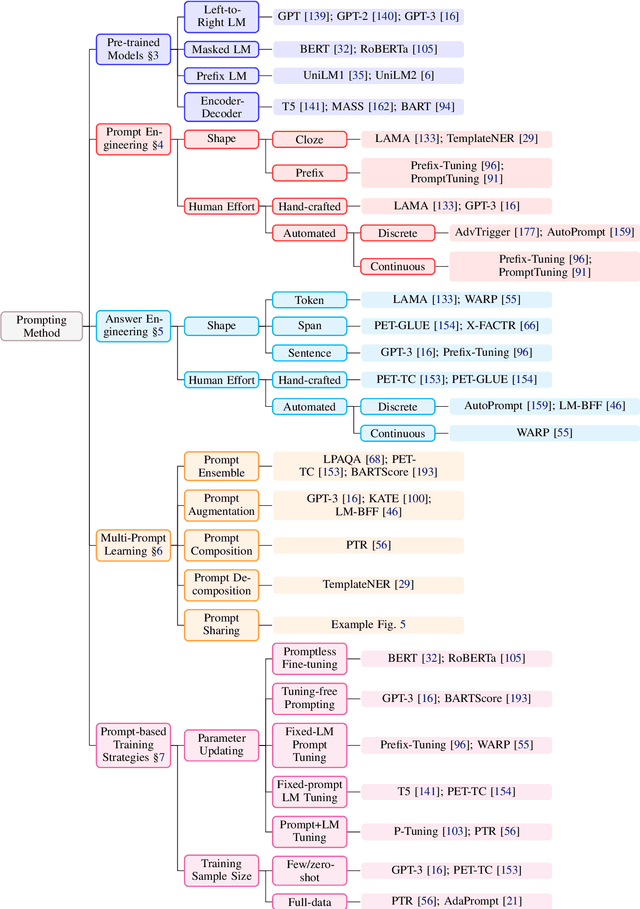
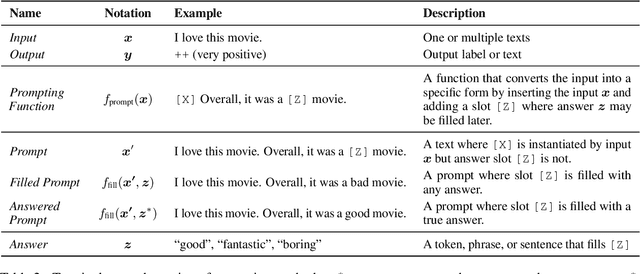
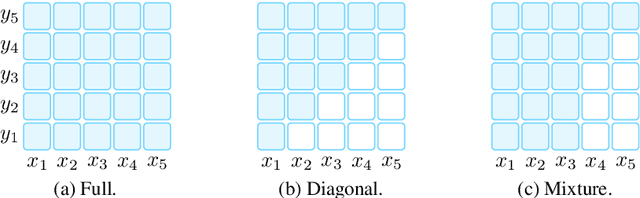
This paper surveys and organizes research works in a new paradigm in natural language processing, which we dub "prompt-based learning". Unlike traditional supervised learning, which trains a model to take in an input x and predict an output y as P(y|x), prompt-based learning is based on language models that model the probability of text directly. To use these models to perform prediction tasks, the original input x is modified using a template into a textual string prompt x' that has some unfilled slots, and then the language model is used to probabilistically fill the unfilled information to obtain a final string x, from which the final output y can be derived. This framework is powerful and attractive for a number of reasons: it allows the language model to be pre-trained on massive amounts of raw text, and by defining a new prompting function the model is able to perform few-shot or even zero-shot learning, adapting to new scenarios with few or no labeled data. In this paper we introduce the basics of this promising paradigm, describe a unified set of mathematical notations that can cover a wide variety of existing work, and organize existing work along several dimensions, e.g.the choice of pre-trained models, prompts, and tuning strategies. To make the field more accessible to interested beginners, we not only make a systematic review of existing works and a highly structured typology of prompt-based concepts, but also release other resources, e.g., a website http://pretrain.nlpedia.ai/ including constantly-updated survey, and paperlist.
WikiAsp: A Dataset for Multi-domain Aspect-based Summarization
Nov 16, 2020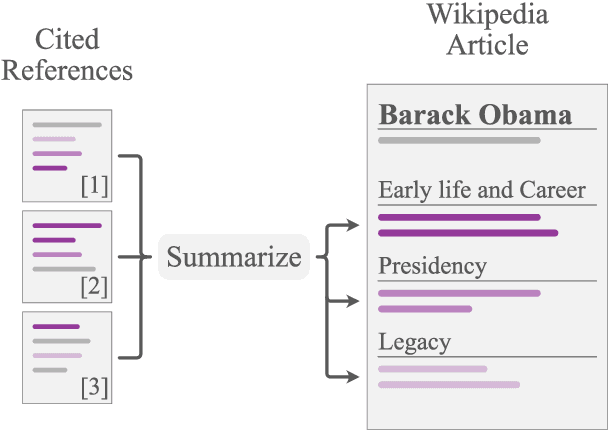
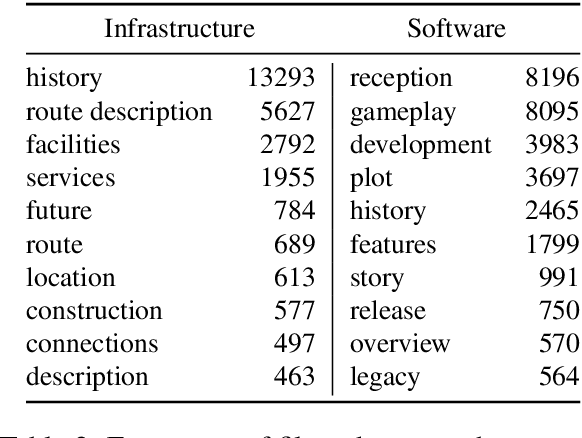
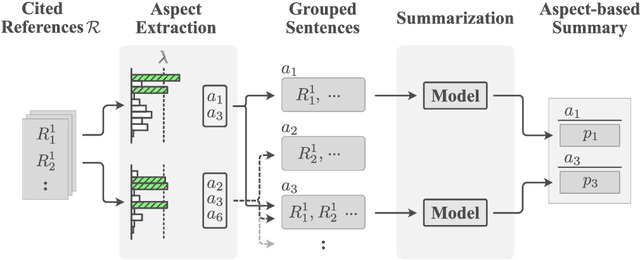
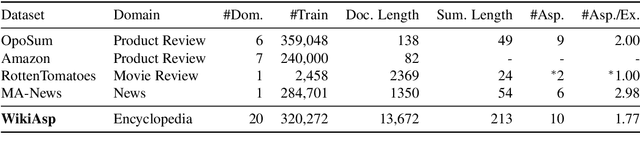
Aspect-based summarization is the task of generating focused summaries based on specific points of interest. Such summaries aid efficient analysis of text, such as quickly understanding reviews or opinions from different angles. However, due to large differences in the type of aspects for different domains (e.g., sentiment, product features), the development of previous models has tended to be domain-specific. In this paper, we propose WikiAsp, a large-scale dataset for multi-domain aspect-based summarization that attempts to spur research in the direction of open-domain aspect-based summarization. Specifically, we build the dataset using Wikipedia articles from 20 different domains, using the section titles and boundaries of each article as a proxy for aspect annotation. We propose several straightforward baseline models for this task and conduct experiments on the dataset. Results highlight key challenges that existing summarization models face in this setting, such as proper pronoun handling of quoted sources and consistent explanation of time-sensitive events.