 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Leaderboard Illusion
Apr 29, 2025Measuring progress is fundamental to the advancement of any scientific field. As benchmarks play an increasingly central role, they also grow more susceptible to distortion. Chatbot Arena has emerged as the go-to leaderboard for ranking the most capable AI systems. Yet, in this work we identify systematic issues that have resulted in a distorted playing field. We find that undisclosed private testing practices benefit a handful of providers who are able to test multiple variants before public release and retract scores if desired. We establish that the ability of these providers to choose the best score leads to biased Arena scores due to selective disclosure of performance results. At an extreme, we identify 27 private LLM variants tested by Meta in the lead-up to the Llama-4 release. We also establish that proprietary closed models are sampled at higher rates (number of battles) and have fewer models removed from the arena than open-weight and open-source alternatives. Both these policies lead to large data access asymmetries over time. Providers like Google and OpenAI have received an estimated 19.2% and 20.4% of all data on the arena, respectively. In contrast, a combined 83 open-weight models have only received an estimated 29.7% of the total data. We show that access to Chatbot Arena data yields substantial benefits; even limited additional data can result in relative performance gains of up to 112% on the arena distribution, based on our conservative estimates. Together, these dynamics result in overfitting to Arena-specific dynamics rather than general model quality. The Arena builds on the substantial efforts of both the organizers and an open community that maintains this valuable evaluation platform. We offer actionable recommendations to reform the Chatbot Arena's evaluation framework and promote fairer, more transparent benchmarking for the field
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
TICKing All the Boxes: Generated Checklists Improve LLM Evaluation and Generation
Oct 04, 2024



Given the widespread adoption and usage of Large Language Models (LLMs), it is crucial to have flexible and interpretable evaluations of their instruction-following ability. Preference judgments between model outputs have become the de facto evaluation standard, despite distilling complex, multi-faceted preferences into a single ranking. Furthermore, as human annotation is slow and costly, LLMs are increasingly used to make these judgments, at the expense of reliability and interpretability. In this work, we propose TICK (Targeted Instruct-evaluation with ChecKlists), a fully automated, interpretable evaluation protocol that structures evaluations with LLM-generated, instruction-specific checklists. We first show that, given an instruction, LLMs can reliably produce high-quality, tailored evaluation checklists that decompose the instruction into a series of YES/NO questions. Each question asks whether a candidate response meets a specific requirement of the instruction. We demonstrate that using TICK leads to a significant increase (46.4% $\to$ 52.2%) in the frequency of exact agreements between LLM judgements and human preferences, as compared to having an LLM directly score an output. We then show that STICK (Self-TICK) can be used to improve generation quality across multiple benchmarks via self-refinement and Best-of-N selection. STICK self-refinement on LiveBench reasoning tasks leads to an absolute gain of $+$7.8%, whilst Best-of-N selection with STICK attains $+$6.3% absolute improvement on the real-world instruction dataset, WildBench. In light of this, structured, multi-faceted self-improvement is shown to be a promising way to further advance LLM capabilities. Finally, by providing LLM-generated checklists to human evaluators tasked with directly scoring LLM responses to WildBench instructions, we notably increase inter-annotator agreement (0.194 $\to$ 0.256).
JEN-1 DreamStyler: Customized Musical Concept Learning via Pivotal Parameters Tuning
Jun 18, 2024Large models for text-to-music generation have achieved significant progress, facilitating the creation of high-quality and varied musical compositions from provided text prompts. However, input text prompts may not precisely capture user requirements, particularly when the objective is to generate music that embodies a specific concept derived from a designated reference collection. In this paper, we propose a novel method for customized text-to-music generation, which can capture the concept from a two-minute reference music and generate a new piece of music conforming to the concept. We achieve this by fine-tuning a pretrained text-to-music model using the reference music. However, directly fine-tuning all parameters leads to overfitting issues. To address this problem, we propose a Pivotal Parameters Tuning method that enables the model to assimilate the new concept while preserving its original generative capabilities. Additionally, we identify a potential concept conflict when introducing multiple concepts into the pretrained model. We present a concept enhancement strategy to distinguish multiple concepts, enabling the fine-tuned model to generate music incorporating either individual or multiple concepts simultaneously. Since we are the first to work on the customized music generation task, we also introduce a new dataset and evaluation protocol for the new task. Our proposed Jen1-DreamStyler outperforms several baselines in both qualitative and quantitative evaluations. Demos will be available at https://www.jenmusic.ai/research#DreamStyler.
OpenChemIE: An Information Extraction Toolkit For Chemistry Literature
Apr 01, 2024



Information extraction from chemistry literature is vital for constructing up-to-date reaction databases for data-driven chemistry. Complete extraction requires combining information across text, tables, and figures, whereas prior work has mainly investigated extracting reactions from single modalities. In this paper, we present OpenChemIE to address this complex challenge and enable the extraction of reaction data at the document level. OpenChemIE approaches the problem in two steps: extracting relevant information from individual modalities and then integrating the results to obtain a final list of reactions. For the first step, we employ specialized neural models that each address a specific task for chemistry information extraction, such as parsing molecules or reactions from text or figures. We then integrate the information from these modules using chemistry-informed algorithms, allowing for the extraction of fine-grained reaction data from reaction condition and substrate scope investigations. Our machine learning models attain state-of-the-art performance when evaluated individually, and we meticulously annotate a challenging dataset of reaction schemes with R-groups to evaluate our pipeline as a whole, achieving an F1 score of 69.5%. Additionally, the reaction extraction results of \ours attain an accuracy score of 64.3% when directly compared against the Reaxys chemical database. We provide OpenChemIE freely to the public as an open-source package, as well as through a web interface.
Pruning for Protection: Increasing Jailbreak Resistance in Aligned LLMs Without Fine-Tuning
Jan 19, 2024Large Language Models (LLMs) are vulnerable to `Jailbreaking' prompts, a type of attack that can coax these models into generating harmful and illegal content. In this paper, we show that pruning up to 20% of LLM parameters markedly increases their resistance to such attacks without additional training and without sacrificing their performance in standard benchmarks. Intriguingly, we discovered that the enhanced safety observed post-pruning correlates to the initial safety training level of the model, hinting that the effect of pruning could be more general and may hold for other LLM behaviors beyond safety. Additionally, we introduce a curated dataset of 225 harmful tasks across five categories, inserted into ten different Jailbreaking prompts, showing that pruning aids LLMs in concentrating attention on task-relevant tokens in jailbreaking prompts. Lastly, our experiments reveal that the prominent chat models, such as LLaMA-2 Chat, Vicuna, and Mistral Instruct exhibit high susceptibility to jailbreaking attacks, with some categories achieving nearly 70-100% success rate. These insights underline the potential of pruning as a generalizable approach for improving LLM safety, reliability, and potentially other desired behaviors.
JEN-1 Composer: A Unified Framework for High-Fidelity Multi-Track Music Generation
Nov 03, 2023



With rapid advances in generative artificial intelligence, the text-to-music synthesis task has emerged as a promising direction for music generation from scratch. However, finer-grained control over multi-track generation remains an open challenge. Existing models exhibit strong raw generation capability but lack the flexibility to compose separate tracks and combine them in a controllable manner, differing from typical workflows of human composers. To address this issue, we propose JEN-1 Composer, a unified framework to efficiently model marginal, conditional, and joint distributions over multi-track music via a single model. JEN-1 Composer framework exhibits the capacity to seamlessly incorporate any diffusion-based music generation system, \textit{e.g.} Jen-1, enhancing its capacity for versatile multi-track music generation. We introduce a curriculum training strategy aimed at incrementally instructing the model in the transition from single-track generation to the flexible generation of multi-track combinations. During the inference, users have the ability to iteratively produce and choose music tracks that meet their preferences, subsequently creating an entire musical composition incrementally following the proposed Human-AI co-composition workflow. Quantitative and qualitative assessments demonstrate state-of-the-art performance in controllable and high-fidelity multi-track music synthesis. The proposed JEN-1 Composer represents a significant advance toward interactive AI-facilitated music creation and composition. Demos will be available at https://www.jenmusic.ai/audio-demos.
When Less is More: Investigating Data Pruning for Pretraining LLMs at Scale
Sep 08, 2023Large volumes of text data have contributed significantly to the development of large language models (LLMs) in recent years. This data is typically acquired by scraping the internet, leading to pretraining datasets comprised of noisy web text. To date, efforts to prune these datasets down to a higher quality subset have relied on hand-crafted heuristics encoded as rule-based filters. In this work, we take a wider view and explore scalable estimates of data quality that can be used to systematically measure the quality of pretraining data. We perform a rigorous comparison at scale of the simple data quality estimator of perplexity, as well as more sophisticated and computationally intensive estimates of the Error L2-Norm and memorization. These metrics are used to rank and prune pretraining corpora, and we subsequently compare LLMs trained on these pruned datasets. Surprisingly, we find that the simple technique of perplexity outperforms our more computationally expensive scoring methods. We improve over our no-pruning baseline while training on as little as 30% of the original training dataset. Our work sets the foundation for unexplored strategies in automatically curating high quality corpora and suggests the majority of pretraining data can be removed while retaining performance.
JEN-1: Text-Guided Universal Music Generation with Omnidirectional Diffusion Models
Aug 09, 2023



Music generation has attracted growing interest with the advancement of deep generative models. However, generating music conditioned on textual descriptions, known as text-to-music, remains challenging due to the complexity of musical structures and high sampling rate requirements. Despite the task's significance, prevailing generative models exhibit limitations in music quality, computational efficiency, and generalization. This paper introduces JEN-1, a universal high-fidelity model for text-to-music generation. JEN-1 is a diffusion model incorporating both autoregressive and non-autoregressive training. Through in-context learning, JEN-1 performs various generation tasks including text-guided music generation, music inpainting, and continuation. Evaluations demonstrate JEN-1's superior performance over state-of-the-art methods in text-music alignment and music quality while maintaining computational efficiency. Our demos are available at http://futureverse.com/research/jen/demos/jen1
GLARE: A Dataset for Traffic Sign Detection in Sun Glare
Sep 19, 2022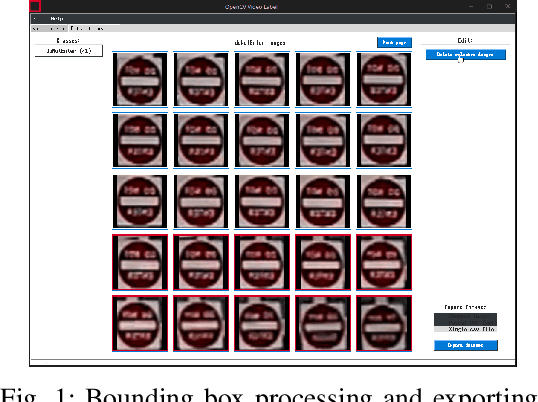
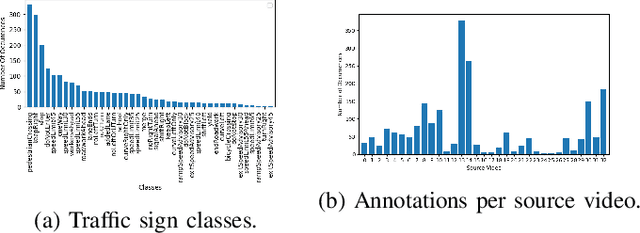

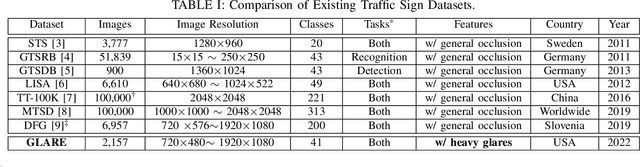
Real-time machine learning detection algorithms are often found within autonomous vehicle technology and depend on quality datasets. It is essential that these algorithms work correctly in everyday conditions as well as under strong sun glare. Reports indicate glare is one of the two most prominent environment-related reasons for crashes. However, existing datasets, such as LISA and the German Traffic Sign Recognition Benchmark, do not reflect the existence of sun glare at all. This paper presents the GLARE traffic sign dataset: a collection of images with U.S based traffic signs under heavy visual interference by sunlight. GLARE contains 2,157 images of traffic signs with sun glare, pulled from 33 videos of dashcam footage of roads in the United States. It provides an essential enrichment to the widely used LISA Traffic Sign dataset. Our experimental study shows that although several state-of-the-art baseline methods demonstrate superior performance when trained and tested against traffic sign datasets without sun glare, they greatly suffer when tested against GLARE (e.g., ranging from 9% to 21% mean mAP, which is significantly lower than the performances on LISA dataset). We also notice that current architectures have better detection accuracy (e.g., on average 42% mean mAP gain for mainstream algorithms) when trained on images of traffic signs in sun glare.