 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Long Document Long Form Summarisation with Self-Planning
Dec 19, 2025We introduce a novel approach for long context summarisation, highlight-guided generation, that leverages sentence-level information as a content plan to improve the traceability and faithfulness of generated summaries. Our framework applies self-planning methods to identify important content and then generates a summary conditioned on the plan. We explore both an end-to-end and two-stage variants of the approach, finding that the two-stage pipeline performs better on long and information-dense documents. Experiments on long-form summarisation datasets demonstrate that our method consistently improves factual consistency while preserving relevance and overall quality. On GovReport, our best approach has improved ROUGE-L by 4.1 points and achieves about 35% gains in SummaC scores. Qualitative analysis shows that highlight-guided summarisation helps preserve important details, leading to more accurate and insightful summaries across domains.
Uncertainty Quantification in Retrieval Augmented Question Answering
Feb 25, 2025



Retrieval augmented Question Answering (QA) helps QA models overcome knowledge gaps by incorporating retrieved evidence, typically a set of passages, alongside the question at test time. Previous studies show that this approach improves QA performance and reduces hallucinations, without, however, assessing whether the retrieved passages are indeed useful at answering correctly. In this work, we propose to quantify the uncertainty of a QA model via estimating the utility of the passages it is provided with. We train a lightweight neural model to predict passage utility for a target QA model and show that while simple information theoretic metrics can predict answer correctness up to a certain extent, our approach efficiently approximates or outperforms more expensive sampling-based methods. Code and data are available at https://github.com/lauhaide/ragu.
Leveraging Entailment Judgements in Cross-Lingual Summarisation
Aug 01, 2024



Synthetically created Cross-Lingual Summarisation (CLS) datasets are prone to include document-summary pairs where the reference summary is unfaithful to the corresponding document as it contains content not supported by the document (i.e., hallucinated content). This low data quality misleads model learning and obscures evaluation results. Automatic ways to assess hallucinations and improve training have been proposed for monolingual summarisation, predominantly in English. For CLS, we propose to use off-the-shelf cross-lingual Natural Language Inference (X-NLI) to evaluate faithfulness of reference and model generated summaries. Then, we study training approaches that are aware of faithfulness issues in the training data and propose an approach that uses unlikelihood loss to teach a model about unfaithful summary sequences. Our results show that it is possible to train CLS models that yield more faithful summaries while maintaining comparable or better informativess.
The Hallucinations Leaderboard -- An Open Effort to Measure Hallucinations in Large Language Models
Apr 08, 2024Large Language Models (LLMs) have transformed the Natural Language Processing (NLP) landscape with their remarkable ability to understand and generate human-like text. However, these models are prone to ``hallucinations'' -- outputs that do not align with factual reality or the input context. This paper introduces the Hallucinations Leaderboard, an open initiative to quantitatively measure and compare the tendency of each model to produce hallucinations. The leaderboard uses a comprehensive set of benchmarks focusing on different aspects of hallucinations, such as factuality and faithfulness, across various tasks, including question-answering, summarisation, and reading comprehension. Our analysis provides insights into the performance of different models, guiding researchers and practitioners in choosing the most reliable models for their applications.
Fine-Grained Natural Language Inference Based Faithfulness Evaluation for Diverse Summarisation Tasks
Feb 27, 2024We study existing approaches to leverage off-the-shelf Natural Language Inference (NLI) models for the evaluation of summary faithfulness and argue that these are sub-optimal due to the granularity level considered for premises and hypotheses. That is, the smaller content unit considered as hypothesis is a sentence and premises are made up of a fixed number of document sentences. We propose a novel approach, namely InFusE, that uses a variable premise size and simplifies summary sentences into shorter hypotheses. Departing from previous studies which focus on single short document summarisation, we analyse NLI based faithfulness evaluation for diverse summarisation tasks. We introduce DiverSumm, a new benchmark comprising long form summarisation (long documents and summaries) and diverse summarisation tasks (e.g., meeting and multi-document summarisation). In experiments, InFusE obtains superior performance across the different summarisation tasks. Our code and data are available at https://github.com/HJZnlp/infuse.
Improving User Controlled Table-To-Text Generation Robustness
Feb 20, 2023



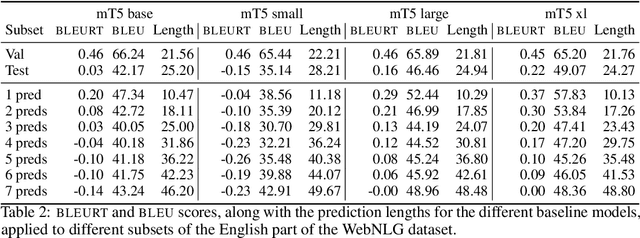
In this work we study user controlled table-to-text generation where users explore the content in a table by selecting cells and reading a natural language description thereof automatically produce by a natural language generator. Such generation models usually learn from carefully selected cell combinations (clean cell selections); however, in practice users may select unexpected, redundant, or incoherent cell combinations (noisy cell selections). In experiments, we find that models perform well on test sets coming from the same distribution as the train data but their performance drops when evaluated on realistic noisy user inputs. We propose a fine-tuning regime with additional user-simulated noisy cell selections. Models fine-tuned with the proposed regime gain 4.85 BLEU points on user noisy test cases and 1.4 on clean test cases; and achieve comparable state-of-the-art performance on the ToTTo dataset.
Semantic Parsing for Conversational Question Answering over Knowledge Graphs
Jan 28, 2023



In this paper, we are interested in developing semantic parsers which understand natural language questions embedded in a conversation with a user and ground them to formal queries over definitions in a general purpose knowledge graph (KG) with very large vocabularies (covering thousands of concept names and relations, and millions of entities). To this end, we develop a dataset where user questions are annotated with Sparql parses and system answers correspond to execution results thereof. We present two different semantic parsing approaches and highlight the challenges of the task: dealing with large vocabularies, modelling conversation context, predicting queries with multiple entities, and generalising to new questions at test time. We hope our dataset will serve as useful testbed for the development of conversational semantic parsers. Our dataset and models are released at https://github.com/EdinburghNLP/SPICE.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022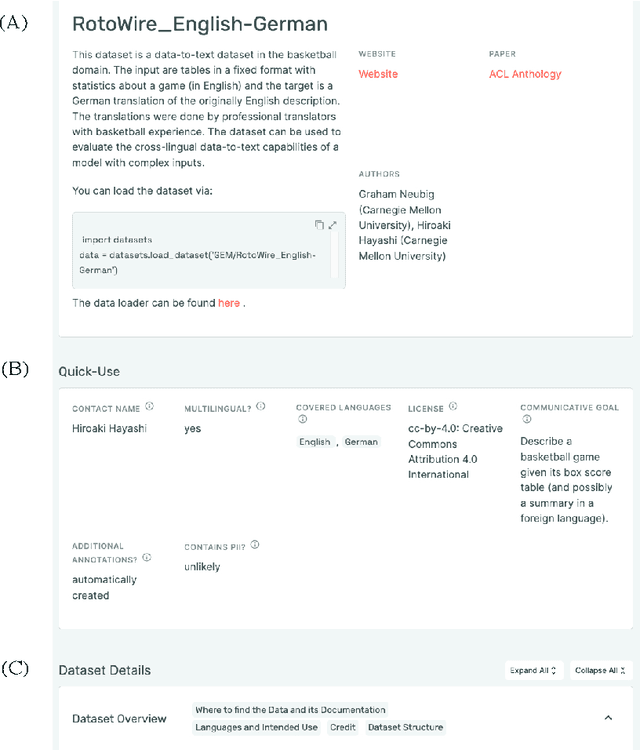


Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.
Models and Datasets for Cross-Lingual Summarisation
Feb 19, 2022
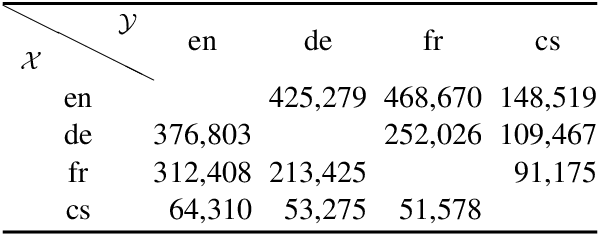
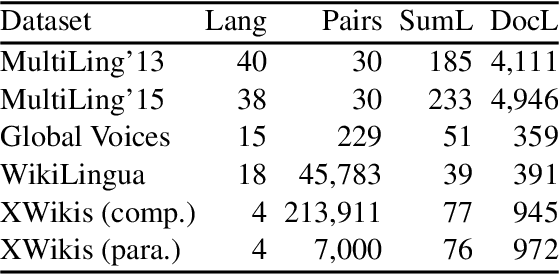

We present a cross-lingual summarisation corpus with long documents in a source language associated with multi-sentence summaries in a target language. The corpus covers twelve language pairs and directions for four European languages, namely Czech, English, French and German, and the methodology for its creation can be applied to several other languages. We derive cross-lingual document-summary instances from Wikipedia by combining lead paragraphs and articles' bodies from language aligned Wikipedia titles. We analyse the proposed cross-lingual summarisation task with automatic metrics and validate it with a human study. To illustrate the utility of our dataset we report experiments with multi-lingual pre-trained models in supervised, zero- and few-shot, and out-of-domain scenarios.
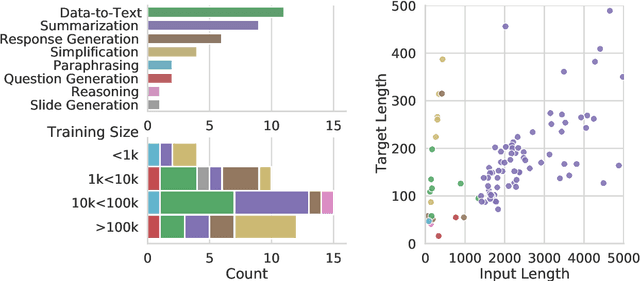
Automatic Construction of Evaluation Suites for Natural Language Generation Datasets
Jun 16, 2021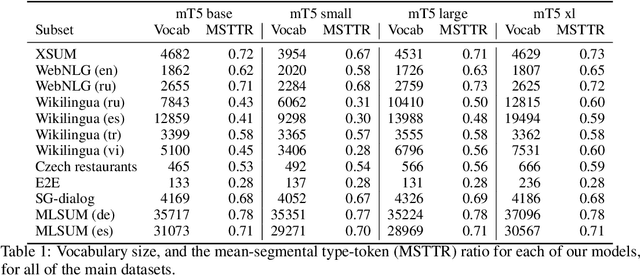
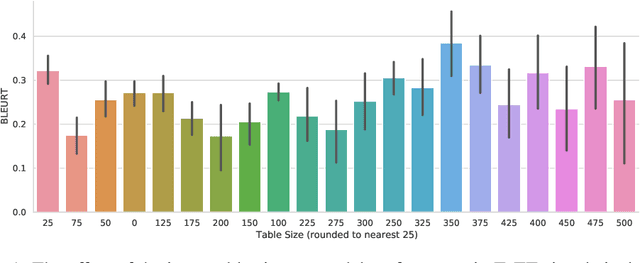
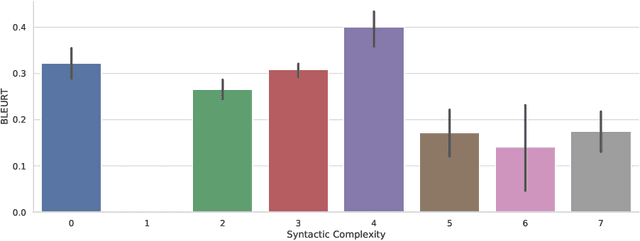
Machine learning approaches applied to NLP are often evaluated by summarizing their performance in a single number, for example accuracy. Since most test sets are constructed as an i.i.d. sample from the overall data, this approach overly simplifies the complexity of language and encourages overfitting to the head of the data distribution. As such, rare language phenomena or text about underrepresented groups are not equally included in the evaluation. To encourage more in-depth model analyses, researchers have proposed the use of multiple test sets, also called challenge sets, that assess specific capabilities of a model. In this paper, we develop a framework based on this idea which is able to generate controlled perturbations and identify subsets in text-to-scalar, text-to-text, or data-to-text settings. By applying this framework to the GEM generation benchmark, we propose an evaluation suite made of 80 challenge sets, demonstrate the kinds of analyses that it enables and shed light onto the limits of current generation models.