 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe QCET Taxonomy of Standard Quality Criterion Names and Definitions for the Evaluation of NLP Systems
Sep 26, 2025



Prior work has shown that two NLP evaluation experiments that report results for the same quality criterion name (e.g. Fluency) do not necessarily evaluate the same aspect of quality, and the comparability implied by the name can be misleading. Not knowing when two evaluations are comparable in this sense means we currently lack the ability to draw reliable conclusions about system quality on the basis of multiple, independently conducted evaluations. This in turn hampers the ability of the field to progress scientifically as a whole, a pervasive issue in NLP since its beginning (Sparck Jones, 1981). It is hard to see how the issue of unclear comparability can be fully addressed other than by the creation of a standard set of quality criterion names and definitions that the several hundred quality criterion names actually in use in the field can be mapped to, and grounded in. Taking a strictly descriptive approach, the QCET Quality Criteria for Evaluation Taxonomy derives a standard set of quality criterion names and definitions from three surveys of evaluations reported in NLP, and structures them into a hierarchy where each parent node captures common aspects of its child nodes. We present QCET and the resources it consists of, and discuss its three main uses in (i) establishing comparability of existing evaluations, (ii) guiding the design of new evaluations, and (iii) assessing regulatory compliance.
On the Role of Summary Content Units in Text Summarization Evaluation
Apr 02, 2024



At the heart of the Pyramid evaluation method for text summarization lie human written summary content units (SCUs). These SCUs are concise sentences that decompose a summary into small facts. Such SCUs can be used to judge the quality of a candidate summary, possibly partially automated via natural language inference (NLI) systems. Interestingly, with the aim to fully automate the Pyramid evaluation, Zhang and Bansal (2021) show that SCUs can be approximated by automatically generated semantic role triplets (STUs). However, several questions currently lack answers, in particular: i) Are there other ways of approximating SCUs that can offer advantages? ii) Under which conditions are SCUs (or their approximations) offering the most value? In this work, we examine two novel strategies to approximate SCUs: generating SCU approximations from AMR meaning representations (SMUs) and from large language models (SGUs), respectively. We find that while STUs and SMUs are competitive, the best approximation quality is achieved by SGUs. We also show through a simple sentence-decomposition baseline (SSUs) that SCUs (and their approximations) offer the most value when ranking short summaries, but may not help as much when ranking systems or longer summaries.
Needle in a Haystack: An Analysis of Finding Qualified Workers on MTurk for Summarization
Dec 28, 2022



The acquisition of high-quality human annotations through crowdsourcing platforms like Amazon Mechanical Turk (MTurk) is more challenging than expected. The annotation quality might be affected by various aspects like annotation instructions, Human Intelligence Task (HIT) design, and wages paid to annotators, etc. To avoid potentially low-quality annotations which could mislead the evaluation of automatic summarization system outputs, we investigate the recruitment of high-quality MTurk workers via a three-step qualification pipeline. We show that we can successfully filter out bad workers before they carry out the evaluations and obtain high-quality annotations while optimizing the use of resources. This paper can serve as basis for the recruitment of qualified annotators in other challenging annotation tasks.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022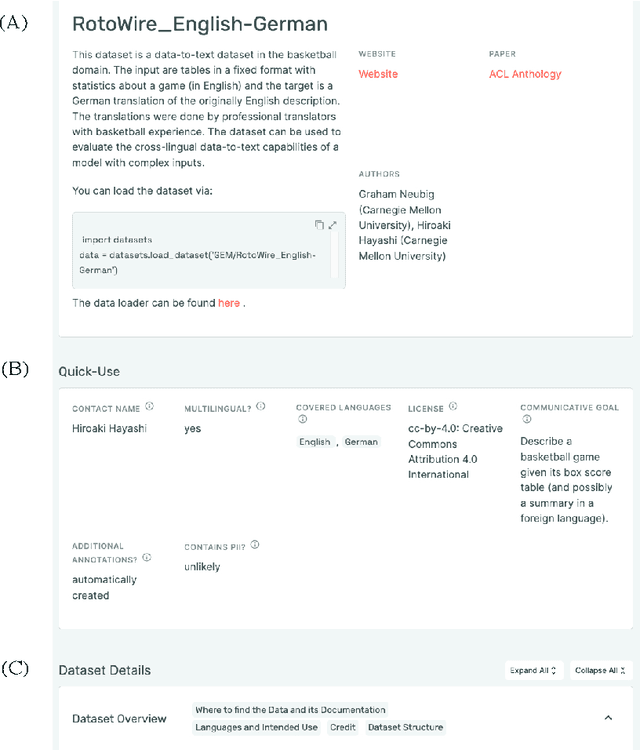


Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.
Quantified Reproducibility Assessment of NLP Results
Apr 12, 2022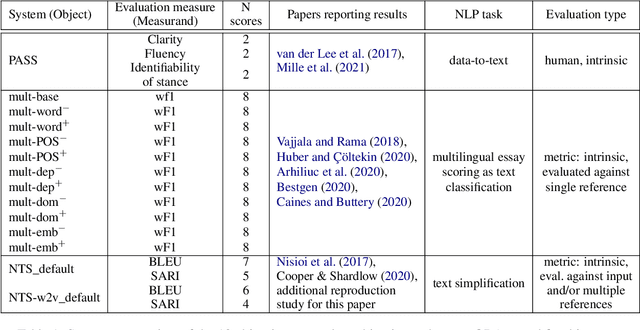

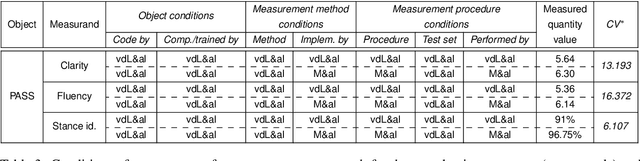
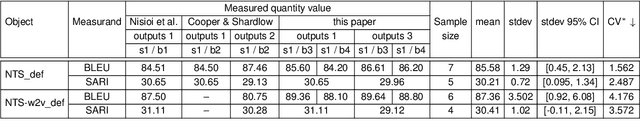
This paper describes and tests a method for carrying out quantified reproducibility assessment (QRA) that is based on concepts and definitions from metrology. QRA produces a single score estimating the degree of reproducibility of a given system and evaluation measure, on the basis of the scores from, and differences between, different reproductions. We test QRA on 18 system and evaluation measure combinations (involving diverse NLP tasks and types of evaluation), for each of which we have the original results and one to seven reproduction results. The proposed QRA method produces degree-of-reproducibility scores that are comparable across multiple reproductions not only of the same, but of different original studies. We find that the proposed method facilitates insights into causes of variation between reproductions, and allows conclusions to be drawn about what changes to system and/or evaluation design might lead to improved reproducibility.
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
Automatic Construction of Evaluation Suites for Natural Language Generation Datasets
Jun 16, 2021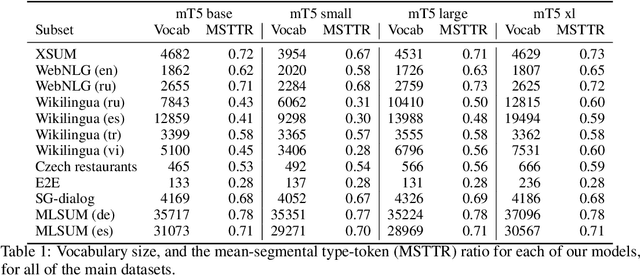
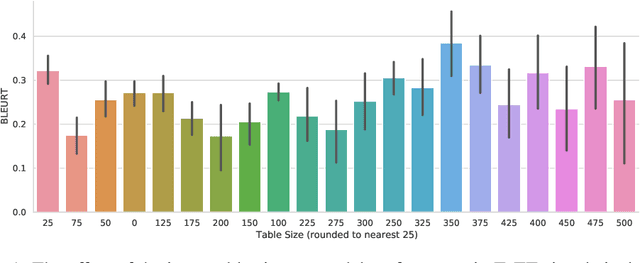
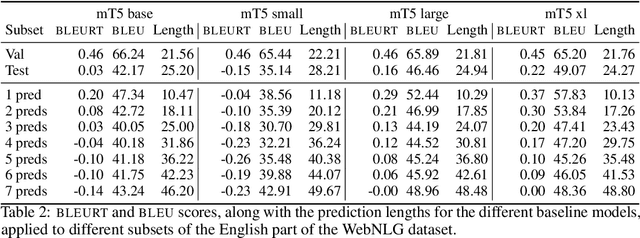
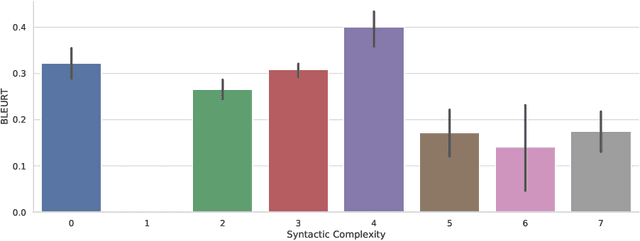
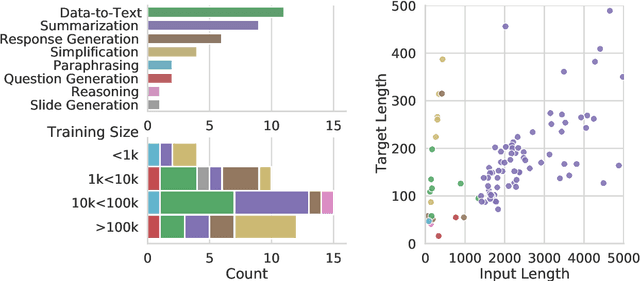
Machine learning approaches applied to NLP are often evaluated by summarizing their performance in a single number, for example accuracy. Since most test sets are constructed as an i.i.d. sample from the overall data, this approach overly simplifies the complexity of language and encourages overfitting to the head of the data distribution. As such, rare language phenomena or text about underrepresented groups are not equally included in the evaluation. To encourage more in-depth model analyses, researchers have proposed the use of multiple test sets, also called challenge sets, that assess specific capabilities of a model. In this paper, we develop a framework based on this idea which is able to generate controlled perturbations and identify subsets in text-to-scalar, text-to-text, or data-to-text settings. By applying this framework to the GEM generation benchmark, we propose an evaluation suite made of 80 challenge sets, demonstrate the kinds of analyses that it enables and shed light onto the limits of current generation models.
Assessing the Syntactic Capabilities of Transformer-based Multilingual Language Models
May 10, 2021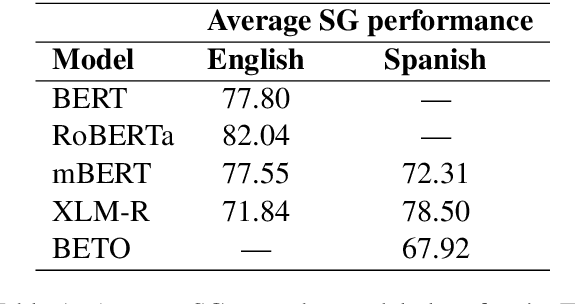
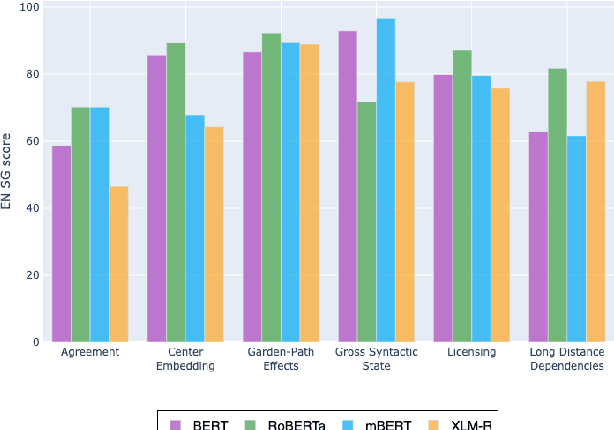
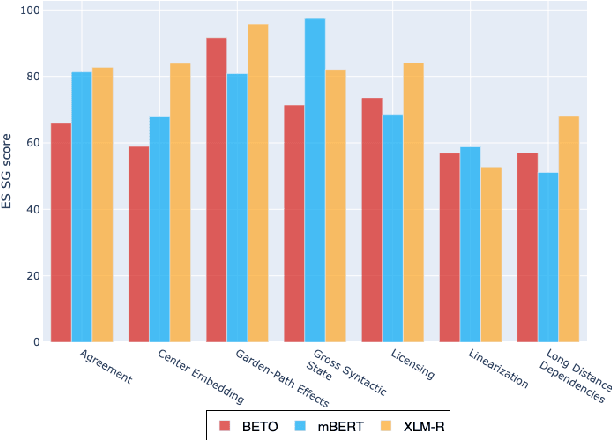
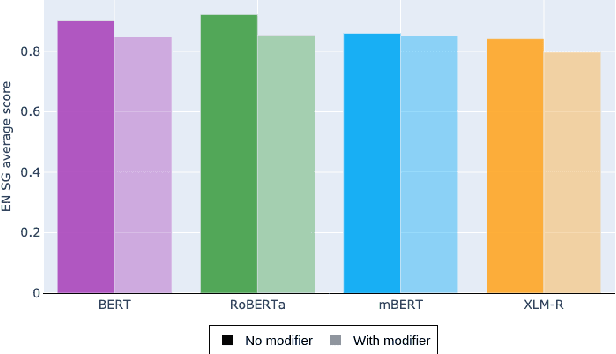
Multilingual Transformer-based language models, usually pretrained on more than 100 languages, have been shown to achieve outstanding results in a wide range of cross-lingual transfer tasks. However, it remains unknown whether the optimization for different languages conditions the capacity of the models to generalize over syntactic structures, and how languages with syntactic phenomena of different complexity are affected. In this work, we explore the syntactic generalization capabilities of the monolingual and multilingual versions of BERT and RoBERTa. More specifically, we evaluate the syntactic generalization potential of the models on English and Spanish tests, comparing the syntactic abilities of monolingual and multilingual models on the same language (English), and of multilingual models on two different languages (English and Spanish). For English, we use the available SyntaxGym test suite; for Spanish, we introduce SyntaxGymES, a novel ensemble of targeted syntactic tests in Spanish, designed to evaluate the syntactic generalization capabilities of language models through the SyntaxGym online platform.
The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics
Feb 03, 2021



We introduce GEM, a living benchmark for natural language Generation (NLG), its Evaluation, and Metrics. Measuring progress in NLG relies on a constantly evolving ecosystem of automated metrics, datasets, and human evaluation standards. However, due to this moving target, new models often still evaluate on divergent anglo-centric corpora with well-established, but flawed, metrics. This disconnect makes it challenging to identify the limitations of current models and opportunities for progress. Addressing this limitation, GEM provides an environment in which models can easily be applied to a wide set of corpora and evaluation strategies can be tested. Regular updates to the benchmark will help NLG research become more multilingual and evolve the challenge alongside models. This paper serves as the description of the initial release for which we are organizing a shared task at our ACL 2021 Workshop and to which we invite the entire NLG community to participate.