 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAfrIFact: Cultural Information Retrieval, Evidence Extraction and Fact Checking for African Languages
Apr 01, 2026Assessing the veracity of a claim made online is a complex and important task with real-world implications. When these claims are directed at communities with limited access to information and the content concerns issues such as healthcare and culture, the consequences intensify, especially in low-resource languages. In this work, we introduce AfrIFact, a dataset that covers the necessary steps for automatic fact-checking (i.e., information retrieval, evidence extraction, and fact checking), in ten African languages and English. Our evaluation results show that even the best embedding models lack cross-lingual retrieval capabilities, and that cultural and news documents are easier to retrieve than healthcare-domain documents, both in large corpora and in single documents. We show that LLMs lack robust multilingual fact-verification capabilities in African languages, while few-shot prompting improves performance by up to 43% in AfriqueQwen-14B, and task-specific fine-tuning further improves fact-checking accuracy by up to 26%. These findings, along with our release of the AfrIFact dataset, encourage work on low-resource information retrieval, evidence retrieval, and fact checking.
Ethio-ASR: Joint Multilingual Speech Recognition and Language Identification for Ethiopian Languages
Mar 24, 2026We present Ethio-ASR, a suite of multilingual CTC-based automatic speech recognition (ASR) models jointly trained on five Ethiopian languages: Amharic, Tigrinya, Oromo, Sidaama, and Wolaytta. These languages belong to the Semitic, Cushitic, and Omotic branches of the Afroasiatic family, and remain severely underrepresented in speech technology despite being spoken by the vast majority of Ethiopia's population. We train our models on the recently released WAXAL corpus using several pre-trained speech encoders and evaluate against strong multilingual baselines, including OmniASR. Our best model achieves an average WER of 30.48% on the WAXAL test set, outperforming the best OmniASR model with substantially fewer parameters. We further provide a comprehensive analysis of gender bias, the contribution of vowel length and consonant gemination to ASR errors, and the training dynamics of multilingual CTC models. Our models and codebase are publicly available to the research community.
CommonLID: Re-evaluating State-of-the-Art Language Identification Performance on Web Data
Jan 25, 2026Language identification (LID) is a fundamental step in curating multilingual corpora. However, LID models still perform poorly for many languages, especially on the noisy and heterogeneous web data often used to train multilingual language models. In this paper, we introduce CommonLID, a community-driven, human-annotated LID benchmark for the web domain, covering 109 languages. Many of the included languages have been previously under-served, making CommonLID a key resource for developing more representative high-quality text corpora. We show CommonLID's value by using it, alongside five other common evaluation sets, to test eight popular LID models. We analyse our results to situate our contribution and to provide an overview of the state of the art. In particular, we highlight that existing evaluations overestimate LID accuracy for many languages in the web domain. We make CommonLID and the code used to create it available under an open, permissive license.
Afri-MCQA: Multimodal Cultural Question Answering for African Languages
Jan 09, 2026Africa is home to over one-third of the world's languages, yet remains underrepresented in AI research. We introduce Afri-MCQA, the first Multilingual Cultural Question-Answering benchmark covering 7.5k Q&A pairs across 15 African languages from 12 countries. The benchmark offers parallel English-African language Q&A pairs across text and speech modalities and was entirely created by native speakers. Benchmarking large language models (LLMs) on Afri-MCQA shows that open-weight models perform poorly across evaluated cultures, with near-zero accuracy on open-ended VQA when queried in native language or speech. To evaluate linguistic competence, we include control experiments meant to assess this specific aspect separate from cultural knowledge, and we observe significant performance gaps between native languages and English for both text and speech. These findings underscore the need for speech-first approaches, culturally grounded pretraining, and cross-lingual cultural transfer. To support more inclusive multimodal AI development in African languages, we release our Afri-MCQA under academic license or CC BY-NC 4.0 on HuggingFace (https://huggingface.co/datasets/Atnafu/Afri-MCQA)
CaMMT: Benchmarking Culturally Aware Multimodal Machine Translation
May 30, 2025
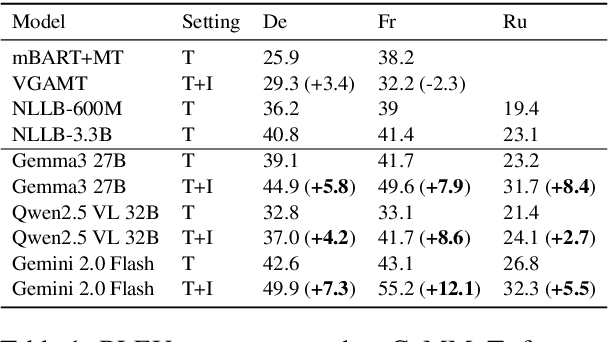

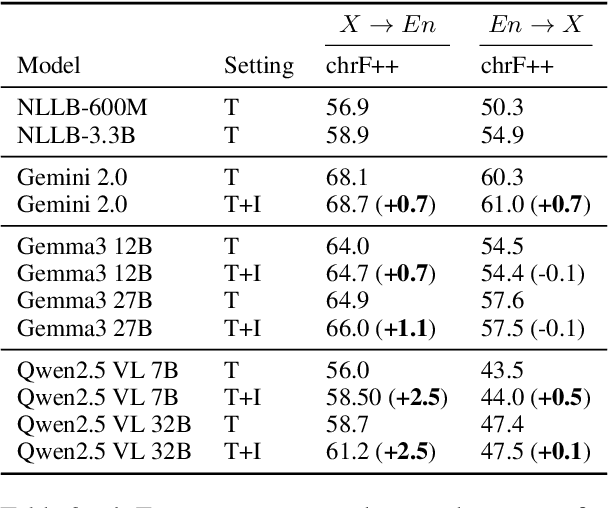
Cultural content poses challenges for machine translation systems due to the differences in conceptualizations between cultures, where language alone may fail to convey sufficient context to capture region-specific meanings. In this work, we investigate whether images can act as cultural context in multimodal translation. We introduce CaMMT, a human-curated benchmark of over 5,800 triples of images along with parallel captions in English and regional languages. Using this dataset, we evaluate five Vision Language Models (VLMs) in text-only and text+image settings. Through automatic and human evaluations, we find that visual context generally improves translation quality, especially in handling Culturally-Specific Items (CSIs), disambiguation, and correct gender usage. By releasing CaMMT, we aim to support broader efforts in building and evaluating multimodal translation systems that are better aligned with cultural nuance and regional variation.
The Esethu Framework: Reimagining Sustainable Dataset Governance and Curation for Low-Resource Languages
Feb 21, 2025



This paper presents the Esethu Framework, a sustainable data curation framework specifically designed to empower local communities and ensure equitable benefit-sharing from their linguistic resources. This framework is supported by the Esethu license, a novel community-centric data license. As a proof of concept, we introduce the Vuk'uzenzele isiXhosa Speech Dataset (ViXSD), an open-source corpus developed under the Esethu Framework and License. The dataset, containing read speech from native isiXhosa speakers enriched with demographic and linguistic metadata, demonstrates how community-driven licensing and curation principles can bridge resource gaps in automatic speech recognition (ASR) for African languages while safeguarding the interests of data creators. We describe the framework guiding dataset development, outline the Esethu license provisions, present the methodology for ViXSD, and present ASR experiments validating ViXSD's usability in building and refining voice-driven applications for isiXhosa.
ProverbEval: Exploring LLM Evaluation Challenges for Low-resource Language Understanding
Nov 07, 2024



With the rapid development of evaluation datasets to assess LLMs understanding across a wide range of subjects and domains, identifying a suitable language understanding benchmark has become increasingly challenging. In this work, we explore LLM evaluation challenges for low-resource language understanding and introduce ProverbEval, LLM evaluation benchmark for low-resource languages based on proverbs to focus on low-resource language understanding in culture-specific scenarios. We benchmark various LLMs and explore factors that create variability in the benchmarking process. We observed performance variances of up to 50%, depending on the order in which answer choices were presented in multiple-choice tasks. Native language proverb descriptions significantly improve tasks such as proverb generation, contributing to improved outcomes. Additionally, monolingual evaluations consistently outperformed their cross-lingual counterparts. We argue special attention must be given to the order of choices, choice of prompt language, task variability, and generation tasks when creating LLM evaluation benchmarks.
The Zeno's Paradox of `Low-Resource' Languages
Oct 28, 2024



The disparity in the languages commonly studied in Natural Language Processing (NLP) is typically reflected by referring to languages as low vs high-resourced. However, there is limited consensus on what exactly qualifies as a `low-resource language.' To understand how NLP papers define and study `low resource' languages, we qualitatively analyzed 150 papers from the ACL Anthology and popular speech-processing conferences that mention the keyword `low-resource.' Based on our analysis, we show how several interacting axes contribute to `low-resourcedness' of a language and why that makes it difficult to track progress for each individual language. We hope our work (1) elicits explicit definitions of the terminology when it is used in papers and (2) provides grounding for the different axes to consider when connoting a language as low-resource.
InkubaLM: A small language model for low-resource African languages
Sep 03, 2024



High-resource language models often fall short in the African context, where there is a critical need for models that are efficient, accessible, and locally relevant, even amidst significant computing and data constraints. This paper introduces InkubaLM, a small language model with 0.4 billion parameters, which achieves performance comparable to models with significantly larger parameter counts and more extensive training data on tasks such as machine translation, question-answering, AfriMMLU, and the AfriXnli task. Notably, InkubaLM outperforms many larger models in sentiment analysis and demonstrates remarkable consistency across multiple languages. This work represents a pivotal advancement in challenging the conventional paradigm that effective language models must rely on substantial resources. Our model and datasets are publicly available at https://huggingface.co/lelapa to encourage research and development on low-resource languages.
CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark
Jun 10, 2024



Visual Question Answering (VQA) is an important task in multimodal AI, and it is often used to test the ability of vision-language models to understand and reason on knowledge present in both visual and textual data. However, most of the current VQA models use datasets that are primarily focused on English and a few major world languages, with images that are typically Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, although these datasets often extend their linguistic range via translation or some other approaches, they usually keep images the same, resulting in narrow cultural representation. To address these limitations, we construct CVQA, a new Culturally-diverse multilingual Visual Question Answering benchmark, designed to cover a rich set of languages and cultures, where we engage native speakers and cultural experts in the data collection process. As a result, CVQA includes culturally-driven images and questions from across 28 countries on four continents, covering 26 languages with 11 scripts, providing a total of 9k questions. We then benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and show that the dataset is challenging for the current state-of-the-art models. This benchmark can serve as a probing evaluation suite for assessing the cultural capability and bias of multimodal models and hopefully encourage more research efforts toward increasing cultural awareness and linguistic diversity in this field.