 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAfriMed-QA: A Pan-African, Multi-Specialty, Medical Question-Answering Benchmark Dataset
Nov 23, 2024

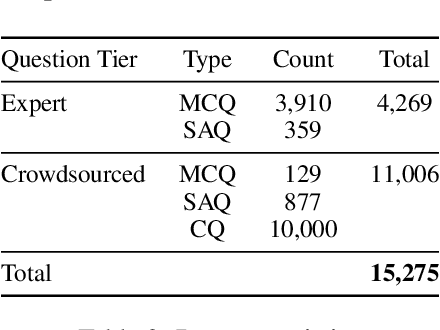

Recent advancements in large language model(LLM) performance on medical multiple choice question (MCQ) benchmarks have stimulated interest from healthcare providers and patients globally. Particularly in low-and middle-income countries (LMICs) facing acute physician shortages and lack of specialists, LLMs offer a potentially scalable pathway to enhance healthcare access and reduce costs. However, their effectiveness in the Global South, especially across the African continent, remains to be established. In this work, we introduce AfriMed-QA, the first large scale Pan-African English multi-specialty medical Question-Answering (QA) dataset, 15,000 questions (open and closed-ended) sourced from over 60 medical schools across 16 countries, covering 32 medical specialties. We further evaluate 30 LLMs across multiple axes including correctness and demographic bias. Our findings show significant performance variation across specialties and geographies, MCQ performance clearly lags USMLE (MedQA). We find that biomedical LLMs underperform general models and smaller edge-friendly LLMs struggle to achieve a passing score. Interestingly, human evaluations show a consistent consumer preference for LLM answers and explanations when compared with clinician answers.
CodeUnlearn: Amortized Zero-Shot Machine Unlearning in Language Models Using Discrete Concept
Oct 08, 2024



Large Language Models (LLMs) offer extensive knowledge across various domains, but they may inadvertently memorize sensitive, unauthorized, or malicious data, such as personal information in the medical and financial sectors. Machine unlearning methods aim to remove specific information from models after training to address this. However, current approaches require additional model training or struggle to effectively erase particular data points and their associated context due to LLMs' complex, dense, and continuous nature. In this study, we propose a novel amortized unlearning approach using codebook features and Sparse Autoencoders (SAEs). By leveraging a bottleneck to decompose the activation space and regulate information flow, our method efficiently unlearns targeted information while preserving the model's performance on unrelated data. To the best of our knowledge, this is the first work that successfully enables unlearning specific topics with contextual relevance in an LLM, marking a significant step towards real-world applications of machine unlearning.
InkubaLM: A small language model for low-resource African languages
Sep 03, 2024



High-resource language models often fall short in the African context, where there is a critical need for models that are efficient, accessible, and locally relevant, even amidst significant computing and data constraints. This paper introduces InkubaLM, a small language model with 0.4 billion parameters, which achieves performance comparable to models with significantly larger parameter counts and more extensive training data on tasks such as machine translation, question-answering, AfriMMLU, and the AfriXnli task. Notably, InkubaLM outperforms many larger models in sentiment analysis and demonstrates remarkable consistency across multiple languages. This work represents a pivotal advancement in challenging the conventional paradigm that effective language models must rely on substantial resources. Our model and datasets are publicly available at https://huggingface.co/lelapa to encourage research and development on low-resource languages.
A Study of Acquisition Functions for Medical Imaging Deep Active Learning
Jan 28, 2024



The Deep Learning revolution has enabled groundbreaking achievements in recent years. From breast cancer detection to protein folding, deep learning algorithms have been at the core of very important advancements. However, these modern advancements are becoming more and more data-hungry, especially on labeled data whose availability is scarce: this is even more prevalent in the medical context. In this work, we show how active learning could be very effective in data scarcity situations, where obtaining labeled data (or annotation budget is very limited). We compare several selection criteria (BALD, MeanSTD, and MaxEntropy) on the ISIC 2016 dataset. We also explored the effect of acquired pool size on the model's performance. Our results suggest that uncertainty is useful to the Melanoma detection task, and confirms the hypotheses of the author of the paper of interest, that \textit{bald} performs on average better than other acquisition functions. Our extended analyses however revealed that all acquisition functions perform badly on the positive (cancerous) samples, suggesting exploitation of class unbalance, which could be crucial in real-world settings. We finish by suggesting future work directions that would be useful to improve this current work. The code of our implementation is open-sourced at \url{https://github.com/bonaventuredossou/ece526_course_project}
AfriSpeech-200: Pan-African Accented Speech Dataset for Clinical and General Domain ASR
Sep 30, 2023Africa has a very low doctor-to-patient ratio. At very busy clinics, doctors could see 30+ patients per day -- a heavy patient burden compared with developed countries -- but productivity tools such as clinical automatic speech recognition (ASR) are lacking for these overworked clinicians. However, clinical ASR is mature, even ubiquitous, in developed nations, and clinician-reported performance of commercial clinical ASR systems is generally satisfactory. Furthermore, the recent performance of general domain ASR is approaching human accuracy. However, several gaps exist. Several publications have highlighted racial bias with speech-to-text algorithms and performance on minority accents lags significantly. To our knowledge, there is no publicly available research or benchmark on accented African clinical ASR, and speech data is non-existent for the majority of African accents. We release AfriSpeech, 200hrs of Pan-African English speech, 67,577 clips from 2,463 unique speakers across 120 indigenous accents from 13 countries for clinical and general domain ASR, a benchmark test set, with publicly available pre-trained models with SOTA performance on the AfriSpeech benchmark.
FonMTL: Towards Multitask Learning for the Fon Language
Sep 11, 2023



The Fon language, spoken by an average 2 million of people, is a truly low-resourced African language, with a limited online presence, and existing datasets (just to name but a few). Multitask learning is a learning paradigm that aims to improve the generalization capacity of a model by sharing knowledge across different but related tasks: this could be prevalent in very data-scarce scenarios. In this paper, we present the first explorative approach to multitask learning, for model capabilities enhancement in Natural Language Processing for the Fon language. Specifically, we explore the tasks of Named Entity Recognition (NER) and Part of Speech Tagging (POS) for Fon. We leverage two language model heads as encoders to build shared representations for the inputs, and we use linear layers blocks for classification relative to each task. Our results on the NER and POS tasks for Fon, show competitive (or better) performances compared to several multilingual pretrained language models finetuned on single tasks. Additionally, we perform a few ablation studies to leverage the efficiency of two different loss combination strategies and find out that the equal loss weighting approach works best in our case. Our code is open-sourced at https://github.com/bonaventuredossou/multitask_fon.
Adapting Pretrained ASR Models to Low-resource Clinical Speech using Epistemic Uncertainty-based Data Selection
Jun 03, 2023While there has been significant progress in ASR, African-accented clinical ASR has been understudied due to a lack of training datasets. Building robust ASR systems in this domain requires large amounts of annotated or labeled data, for a wide variety of linguistically and morphologically rich accents, which are expensive to create. Our study aims to address this problem by reducing annotation expenses through informative uncertainty-based data selection. We show that incorporating epistemic uncertainty into our adaptation rounds outperforms several baseline results, established using state-of-the-art (SOTA) ASR models, while reducing the required amount of labeled data, and hence reducing annotation costs. Our approach also improves out-of-distribution generalization for very low-resource accents, demonstrating the viability of our approach for building generalizable ASR models in the context of accented African clinical ASR, where training datasets are predominantly scarce.
AfriNames: Most ASR models "butcher" African Names
Jun 02, 2023



Useful conversational agents must accurately capture named entities to minimize error for downstream tasks, for example, asking a voice assistant to play a track from a certain artist, initiating navigation to a specific location, or documenting a laboratory result for a patient. However, where named entities such as ``Ukachukwu`` (Igbo), ``Lakicia`` (Swahili), or ``Ingabire`` (Rwandan) are spoken, automatic speech recognition (ASR) models' performance degrades significantly, propagating errors to downstream systems. We model this problem as a distribution shift and demonstrate that such model bias can be mitigated through multilingual pre-training, intelligent data augmentation strategies to increase the representation of African-named entities, and fine-tuning multilingual ASR models on multiple African accents. The resulting fine-tuned models show an 81.5\% relative WER improvement compared with the baseline on samples with African-named entities.
MasakhaPOS: Part-of-Speech Tagging for Typologically Diverse African Languages
May 23, 2023



In this paper, we present MasakhaPOS, the largest part-of-speech (POS) dataset for 20 typologically diverse African languages. We discuss the challenges in annotating POS for these languages using the UD (universal dependencies) guidelines. We conducted extensive POS baseline experiments using conditional random field and several multilingual pre-trained language models. We applied various cross-lingual transfer models trained with data available in UD. Evaluating on the MasakhaPOS dataset, we show that choosing the best transfer language(s) in both single-source and multi-source setups greatly improves the POS tagging performance of the target languages, in particular when combined with cross-lingual parameter-efficient fine-tuning methods. Crucially, transferring knowledge from a language that matches the language family and morphosyntactic properties seems more effective for POS tagging in unseen languages.
AfriQA: Cross-lingual Open-Retrieval Question Answering for African Languages
May 11, 2023



African languages have far less in-language content available digitally, making it challenging for question answering systems to satisfy the information needs of users. Cross-lingual open-retrieval question answering (XOR QA) systems -- those that retrieve answer content from other languages while serving people in their native language -- offer a means of filling this gap. To this end, we create AfriQA, the first cross-lingual QA dataset with a focus on African languages. AfriQA includes 12,000+ XOR QA examples across 10 African languages. While previous datasets have focused primarily on languages where cross-lingual QA augments coverage from the target language, AfriQA focuses on languages where cross-lingual answer content is the only high-coverage source of answer content. Because of this, we argue that African languages are one of the most important and realistic use cases for XOR QA. Our experiments demonstrate the poor performance of automatic translation and multilingual retrieval methods. Overall, AfriQA proves challenging for state-of-the-art QA models. We hope that the dataset enables the development of more equitable QA technology.