 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022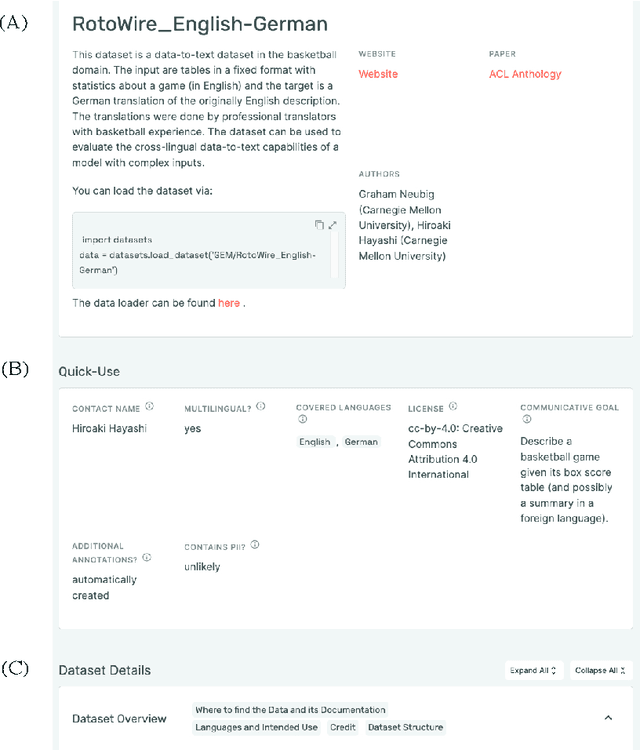

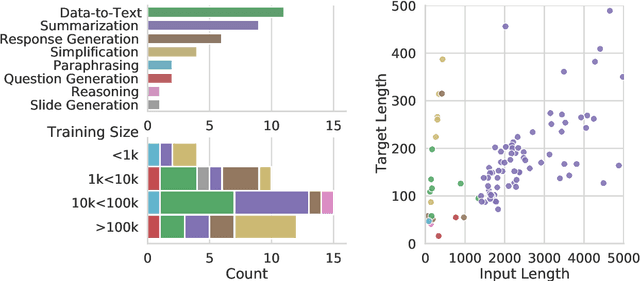

Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.
Generating Fluent Fact Checking Explanations with Unsupervised Post-Editing
Dec 13, 2021
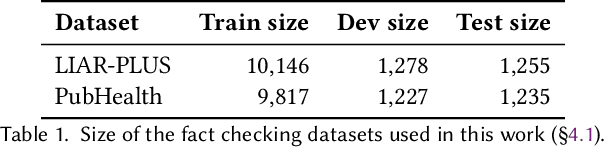
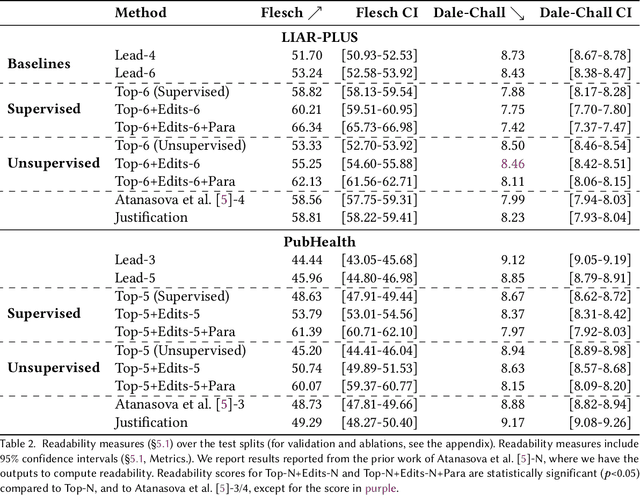
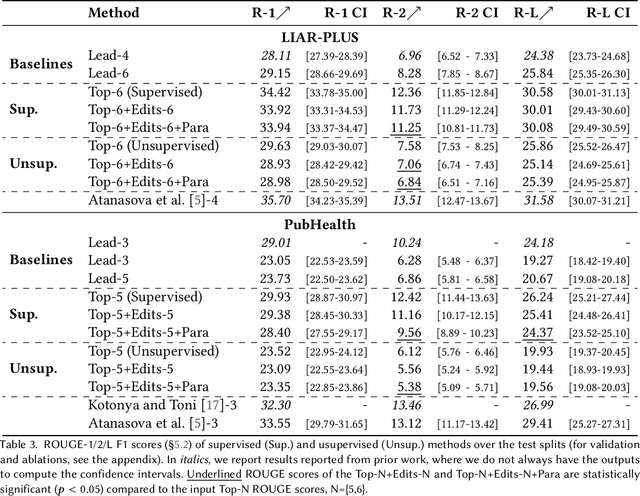
Fact-checking systems have become important tools to verify fake and misguiding news. These systems become more trustworthy when human-readable explanations accompany the veracity labels. However, manual collection of such explanations is expensive and time-consuming. Recent works frame explanation generation as extractive summarization, and propose to automatically select a sufficient subset of the most important facts from the ruling comments (RCs) of a professional journalist to obtain fact-checking explanations. However, these explanations lack fluency and sentence coherence. In this work, we present an iterative edit-based algorithm that uses only phrase-level edits to perform unsupervised post-editing of disconnected RCs. To regulate our editing algorithm, we use a scoring function with components including fluency and semantic preservation. In addition, we show the applicability of our approach in a completely unsupervised setting. We experiment with two benchmark datasets, LIAR-PLUS and PubHealth. We show that our model generates explanations that are fluent, readable, non-redundant, and cover important information for the fact check.
Search and Learn: Improving Semantic Coverage for Data-to-Text Generation
Dec 06, 2021
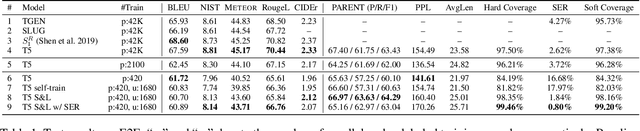
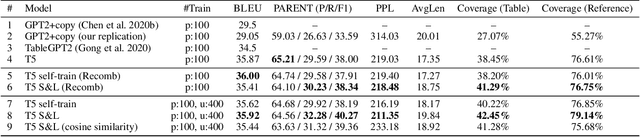

Data-to-text generation systems aim to generate text descriptions based on input data (often represented in the tabular form). A typical system uses huge training samples for learning the correspondence between tables and texts. However, large training sets are expensive to obtain, limiting the applicability of these approaches in real-world scenarios. In this work, we focus on few-shot data-to-text generation. We observe that, while fine-tuned pretrained language models may generate plausible sentences, they suffer from the low semantic coverage problem in the few-shot setting. In other words, important input slots tend to be missing in the generated text. To this end, we propose a search-and-learning approach that leverages pretrained language models but inserts the missing slots to improve the semantic coverage. We further fine-tune our system based on the search results to smooth out the search noise, yielding better-quality text and improving inference efficiency to a large extent. Experiments show that our model achieves high performance on E2E and WikiBio datasets. Especially, we cover 98.35% of input slots on E2E, largely alleviating the low coverage problem.
The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics
Feb 03, 2021



We introduce GEM, a living benchmark for natural language Generation (NLG), its Evaluation, and Metrics. Measuring progress in NLG relies on a constantly evolving ecosystem of automated metrics, datasets, and human evaluation standards. However, due to this moving target, new models often still evaluate on divergent anglo-centric corpora with well-established, but flawed, metrics. This disconnect makes it challenging to identify the limitations of current models and opportunities for progress. Addressing this limitation, GEM provides an environment in which models can easily be applied to a wide set of corpora and evaluation strategies can be tested. Regular updates to the benchmark will help NLG research become more multilingual and evolve the challenge alongside models. This paper serves as the description of the initial release for which we are organizing a shared task at our ACL 2021 Workshop and to which we invite the entire NLG community to participate.
Leveraging Visual Question Answering to Improve Text-to-Image Synthesis
Oct 28, 2020
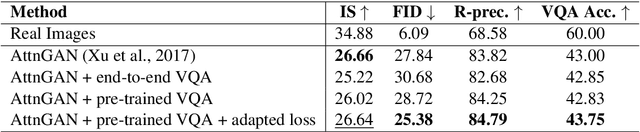
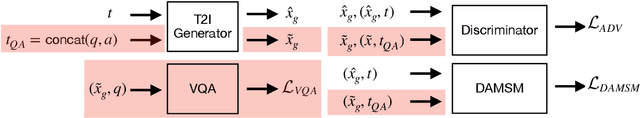
Generating images from textual descriptions has recently attracted a lot of interest. While current models can generate photo-realistic images of individual objects such as birds and human faces, synthesising images with multiple objects is still very difficult. In this paper, we propose an effective way to combine Text-to-Image (T2I) synthesis with Visual Question Answering (VQA) to improve the image quality and image-text alignment of generated images by leveraging the VQA 2.0 dataset. We create additional training samples by concatenating question and answer (QA) pairs and employ a standard VQA model to provide the T2I model with an auxiliary learning signal. We encourage images generated from QA pairs to look realistic and additionally minimize an external VQA loss. Our method lowers the FID from 27.84 to 25.38 and increases the R-prec. from 83.82% to 84.79% when compared to the baseline, which indicates that T2I synthesis can successfully be improved using a standard VQA model.
P $\approx$ NP, at least in Visual Question Answering
Mar 27, 2020
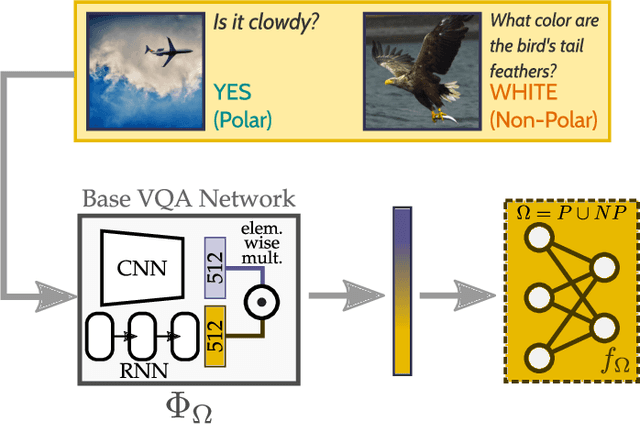
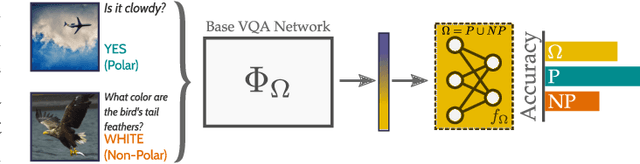
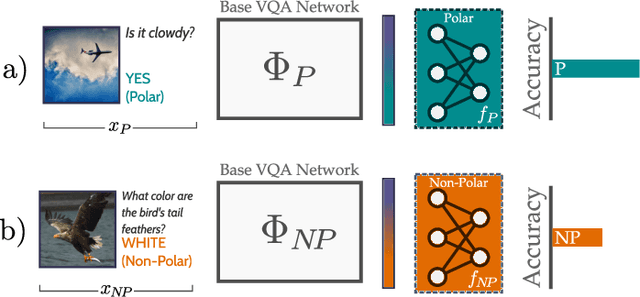
In recent years, progress in the Visual Question Answering (VQA) field has largely been driven by public challenges and large datasets. One of the most widely-used of these is the VQA 2.0 dataset, consisting of polar ("yes/no") and non-polar questions. Looking at the question distribution over all answers, we find that the answers "yes" and "no" account for 38 % of the questions, while the remaining 62% are spread over the more than 3000 remaining answers. While several sources of biases have already been investigated in the field, the effects of such an over-representation of polar vs. non-polar questions remain unclear. In this paper, we measure the potential confounding factors when polar and non-polar samples are used jointly to train a baseline VQA classifier, and compare it to an upper bound where the over-representation of polar questions is excluded from the training. Further, we perform cross-over experiments to analyze how well the feature spaces align. Contrary to expectations, we find no evidence of counterproductive effects in the joint training of unbalanced classes. In fact, by exploring the intermediate feature space of visual-text embeddings, we find that the feature space of polar questions already encodes sufficient structure to answer many non-polar questions. Our results indicate that the polar (P) and the non-polar (NP) feature spaces are strongly aligned, hence the expression P $\approx$ NP
The Wisdom of MaSSeS: Majority, Subjectivity, and Semantic Similarity in the Evaluation of VQA
Sep 12, 2018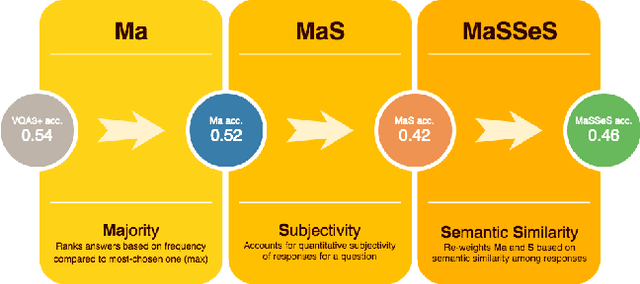


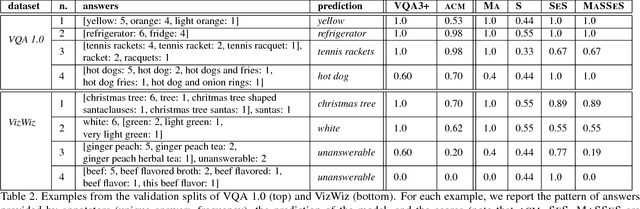
We introduce MASSES, a simple evaluation metric for the task of Visual Question Answering (VQA). In its standard form, the VQA task is operationalized as follows: Given an image and an open-ended question in natural language, systems are required to provide a suitable answer. Currently, model performance is evaluated by means of a somehow simplistic metric: If the predicted answer is chosen by at least 3 human annotators out of 10, then it is 100% correct. Though intuitively valuable, this metric has some important limitations. First, it ignores whether the predicted answer is the one selected by the Majority (MA) of annotators. Second, it does not account for the quantitative Subjectivity (S) of the answers in the sample (and dataset). Third, information about the Semantic Similarity (SES) of the responses is completely neglected. Based on such limitations, we propose a multi-component metric that accounts for all these issues. We show that our metric is effective in providing a more fine-grained evaluation both on the quantitative and qualitative level.
How do Convolutional Neural Networks Learn Design?
Aug 25, 2018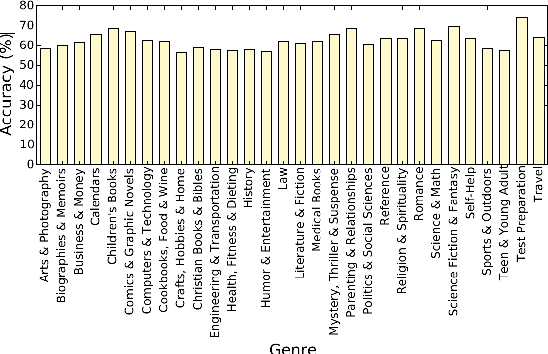
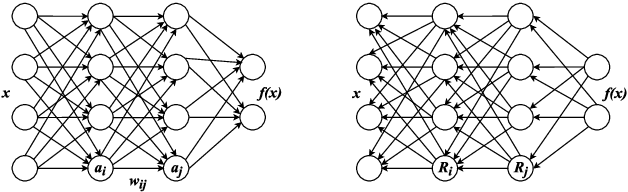
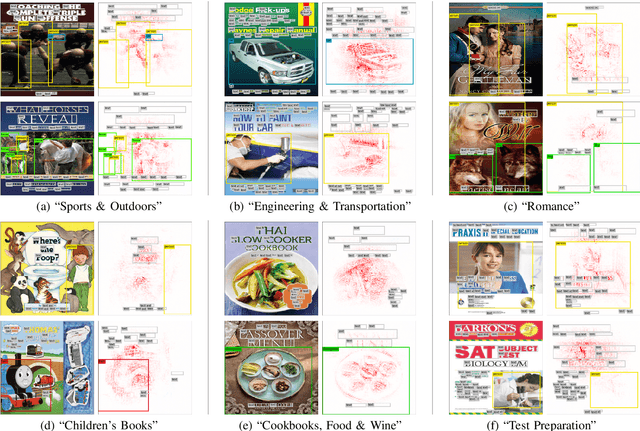

In this paper, we aim to understand the design principles in book cover images which are carefully crafted by experts. Book covers are designed in a unique way, specific to genres which convey important information to their readers. By using Convolutional Neural Networks (CNN) to predict book genres from cover images, visual cues which distinguish genres can be highlighted and analyzed. In order to understand these visual clues contributing towards the decision of a genre, we present the application of Layer-wise Relevance Propagation (LRP) on the book cover image classification results. We use LRP to explain the pixel-wise contributions of book cover design and highlight the design elements contributing towards particular genres. In addition, with the use of state-of-the-art object and text detection methods, insights about genre-specific book cover designs are discovered.