 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfiniteICL: Breaking the Limit of Context Window Size via Long Short-term Memory Transformation
Apr 03, 2025



In-context learning (ICL) is critical for large language models (LLMs), but its effectiveness is constrained by finite context windows, particularly in ultra-long contexts. To overcome this, we introduce InfiniteICL, a framework that parallels context and parameters in LLMs with short- and long-term memory in human cognitive systems, focusing on transforming temporary context knowledge into permanent parameter updates. This approach significantly reduces memory usage, maintains robust performance across varying input lengths, and theoretically enables infinite context integration through the principles of context knowledge elicitation, selection, and consolidation. Evaluations demonstrate that our method reduces context length by 90% while achieving 103% average performance of full-context prompting across fact recall, grounded reasoning, and skill acquisition tasks. When conducting sequential multi-turn transformations on complex, real-world contexts (with length up to 2M tokens), our approach surpasses full-context prompting while using only 0.4% of the original contexts. These findings highlight InfiniteICL's potential to enhance the scalability and efficiency of LLMs by breaking the limitations of conventional context window sizes.
MagicID: Hybrid Preference Optimization for ID-Consistent and Dynamic-Preserved Video Customization
Mar 16, 2025



Video identity customization seeks to produce high-fidelity videos that maintain consistent identity and exhibit significant dynamics based on users' reference images. However, existing approaches face two key challenges: identity degradation over extended video length and reduced dynamics during training, primarily due to their reliance on traditional self-reconstruction training with static images. To address these issues, we introduce $\textbf{MagicID}$, a novel framework designed to directly promote the generation of identity-consistent and dynamically rich videos tailored to user preferences. Specifically, we propose constructing pairwise preference video data with explicit identity and dynamic rewards for preference learning, instead of sticking to the traditional self-reconstruction. To address the constraints of customized preference data, we introduce a hybrid sampling strategy. This approach first prioritizes identity preservation by leveraging static videos derived from reference images, then enhances dynamic motion quality in the generated videos using a Frontier-based sampling method. By utilizing these hybrid preference pairs, we optimize the model to align with the reward differences between pairs of customized preferences. Extensive experiments show that MagicID successfully achieves consistent identity and natural dynamics, surpassing existing methods across various metrics.
GCA-3D: Towards Generalized and Consistent Domain Adaptation of 3D Generators
Dec 20, 2024Recently, 3D generative domain adaptation has emerged to adapt the pre-trained generator to other domains without collecting massive datasets and camera pose distributions. Typically, they leverage large-scale pre-trained text-to-image diffusion models to synthesize images for the target domain and then fine-tune the 3D model. However, they suffer from the tedious pipeline of data generation, which inevitably introduces pose bias between the source domain and synthetic dataset. Furthermore, they are not generalized to support one-shot image-guided domain adaptation, which is more challenging due to the more severe pose bias and additional identity bias introduced by the single image reference. To address these issues, we propose GCA-3D, a generalized and consistent 3D domain adaptation method without the intricate pipeline of data generation. Different from previous pipeline methods, we introduce multi-modal depth-aware score distillation sampling loss to efficiently adapt 3D generative models in a non-adversarial manner. This multi-modal loss enables GCA-3D in both text prompt and one-shot image prompt adaptation. Besides, it leverages per-instance depth maps from the volume rendering module to mitigate the overfitting problem and retain the diversity of results. To enhance the pose and identity consistency, we further propose a hierarchical spatial consistency loss to align the spatial structure between the generated images in the source and target domain. Experiments demonstrate that GCA-3D outperforms previous methods in terms of efficiency, generalization, pose accuracy, and identity consistency.
PersonalVideo: High ID-Fidelity Video Customization without Dynamic and Semantic Degradation
Nov 26, 2024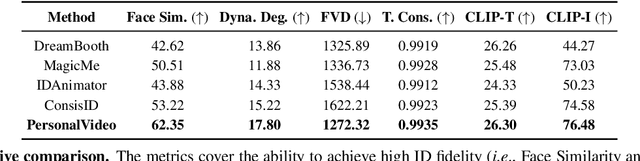
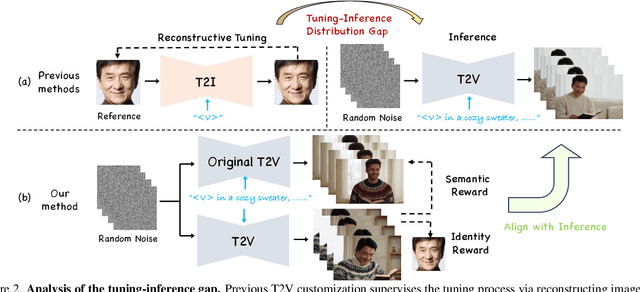
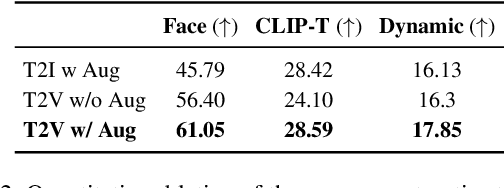
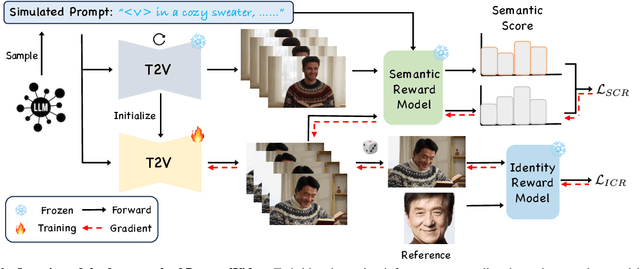
The current text-to-video (T2V) generation has made significant progress in synthesizing realistic general videos, but it is still under-explored in identity-specific human video generation with customized ID images. The key challenge lies in maintaining high ID fidelity consistently while preserving the original motion dynamic and semantic following after the identity injection. Current video identity customization methods mainly rely on reconstructing given identity images on text-to-image models, which have a divergent distribution with the T2V model. This process introduces a tuning-inference gap, leading to dynamic and semantic degradation. To tackle this problem, we propose a novel framework, dubbed \textbf{PersonalVideo}, that applies direct supervision on videos synthesized by the T2V model to bridge the gap. Specifically, we introduce a learnable Isolated Identity Adapter to customize the specific identity non-intrusively, which does not comprise the original T2V model's abilities (e.g., motion dynamic and semantic following). With the non-reconstructive identity loss, we further employ simulated prompt augmentation to reduce overfitting by supervising generated results in more semantic scenarios, gaining good robustness even with only a single reference image available. Extensive experiments demonstrate our method's superiority in delivering high identity faithfulness while preserving the inherent video generation qualities of the original T2V model, outshining prior approaches. Notably, our PersonalVideo seamlessly integrates with pre-trained SD components, such as ControlNet and style LoRA, requiring no extra tuning overhead.
Delving into the Reversal Curse: How Far Can Large Language Models Generalize?
Oct 24, 2024



While large language models (LLMs) showcase unprecedented capabilities, they also exhibit certain inherent limitations when facing seemingly trivial tasks. A prime example is the recently debated "reversal curse", which surfaces when models, having been trained on the fact "A is B", struggle to generalize this knowledge to infer that "B is A". In this paper, we examine the manifestation of the reversal curse across various tasks and delve into both the generalization abilities and the problem-solving mechanisms of LLMs. This investigation leads to a series of significant insights: (1) LLMs are able to generalize to "B is A" when both A and B are presented in the context as in the case of a multiple-choice question. (2) This generalization ability is highly correlated to the structure of the fact "A is B" in the training documents. For example, this generalization only applies to biographies structured in "[Name] is [Description]" but not to "[Description] is [Name]". (3) We propose and verify the hypothesis that LLMs possess an inherent bias in fact recalling during knowledge application, which explains and underscores the importance of the document structure to successful learning. (4) The negative impact of this bias on the downstream performance of LLMs can hardly be mitigated through training alone. Based on these intriguing findings, our work not only presents a novel perspective for interpreting LLMs' generalization abilities from their intrinsic working mechanism but also provides new insights for the development of more effective learning methods for LLMs.
A Survey on the Honesty of Large Language Models
Sep 27, 2024



Honesty is a fundamental principle for aligning large language models (LLMs) with human values, requiring these models to recognize what they know and don't know and be able to faithfully express their knowledge. Despite promising, current LLMs still exhibit significant dishonest behaviors, such as confidently presenting wrong answers or failing to express what they know. In addition, research on the honesty of LLMs also faces challenges, including varying definitions of honesty, difficulties in distinguishing between known and unknown knowledge, and a lack of comprehensive understanding of related research. To address these issues, we provide a survey on the honesty of LLMs, covering its clarification, evaluation approaches, and strategies for improvement. Moreover, we offer insights for future research, aiming to inspire further exploration in this important area.
From Yes-Men to Truth-Tellers: Addressing Sycophancy in Large Language Models with Pinpoint Tuning
Sep 03, 2024



Large Language Models (LLMs) tend to prioritize adherence to user prompts over providing veracious responses, leading to the sycophancy issue. When challenged by users, LLMs tend to admit mistakes and provide inaccurate responses even if they initially provided the correct answer. Recent works propose to employ supervised fine-tuning (SFT) to mitigate the sycophancy issue, while it typically leads to the degeneration of LLMs' general capability. To address the challenge, we propose a novel supervised pinpoint tuning (SPT), where the region-of-interest modules are tuned for a given objective. Specifically, SPT first reveals and verifies a small percentage (<5%) of the basic modules, which significantly affect a particular behavior of LLMs. i.e., sycophancy. Subsequently, SPT merely fine-tunes these identified modules while freezing the rest. To verify the effectiveness of the proposed SPT, we conduct comprehensive experiments, demonstrating that SPT significantly mitigates the sycophancy issue of LLMs (even better than SFT). Moreover, SPT introduces limited or even no side effects on the general capability of LLMs. Our results shed light on how to precisely, effectively, and efficiently explain and improve the targeted ability of LLMs.
DOCBENCH: A Benchmark for Evaluating LLM-based Document Reading Systems
Jul 15, 2024



Recently, there has been a growing interest among large language model (LLM) developers in LLM-based document reading systems, which enable users to upload their own documents and pose questions related to the document contents, going beyond simple reading comprehension tasks. Consequently, these systems have been carefully designed to tackle challenges such as file parsing, metadata extraction, multi-modal information understanding and long-context reading. However, no current benchmark exists to evaluate their performance in such scenarios, where a raw file and questions are provided as input, and a corresponding response is expected as output. In this paper, we introduce DocBench, a new benchmark designed to evaluate LLM-based document reading systems. Our benchmark involves a meticulously crafted process, including the recruitment of human annotators and the generation of synthetic questions. It includes 229 real documents and 1,102 questions, spanning across five different domains and four major types of questions. We evaluate both proprietary LLM-based systems accessible via web interfaces or APIs, and a parse-then-read pipeline employing open-source LLMs. Our evaluations reveal noticeable gaps between existing LLM-based document reading systems and human performance, underscoring the challenges of developing proficient systems. To summarize, DocBench aims to establish a standardized benchmark for evaluating LLM-based document reading systems under diverse real-world scenarios, thereby guiding future advancements in this research area.
TASeg: Temporal Aggregation Network for LiDAR Semantic Segmentation
Jul 13, 2024



Training deep models for LiDAR semantic segmentation is challenging due to the inherent sparsity of point clouds. Utilizing temporal data is a natural remedy against the sparsity problem as it makes the input signal denser. However, previous multi-frame fusion algorithms fall short in utilizing sufficient temporal information due to the memory constraint, and they also ignore the informative temporal images. To fully exploit rich information hidden in long-term temporal point clouds and images, we present the Temporal Aggregation Network, termed TASeg. Specifically, we propose a Temporal LiDAR Aggregation and Distillation (TLAD) algorithm, which leverages historical priors to assign different aggregation steps for different classes. It can largely reduce memory and time overhead while achieving higher accuracy. Besides, TLAD trains a teacher injected with gt priors to distill the model, further boosting the performance. To make full use of temporal images, we design a Temporal Image Aggregation and Fusion (TIAF) module, which can greatly expand the camera FOV and enhance the present features. Temporal LiDAR points in the camera FOV are used as mediums to transform temporal image features to the present coordinate for temporal multi-modal fusion. Moreover, we develop a Static-Moving Switch Augmentation (SMSA) algorithm, which utilizes sufficient temporal information to enable objects to switch their motion states freely, thus greatly increasing static and moving training samples. Our TASeg ranks 1st on three challenging tracks, i.e., SemanticKITTI single-scan track, multi-scan track and nuScenes LiDAR segmentation track, strongly demonstrating the superiority of our method. Codes are available at https://github.com/LittlePey/TASeg.
GLBench: A Comprehensive Benchmark for Graph with Large Language Models
Jul 11, 2024



The emergence of large language models (LLMs) has revolutionized the way we interact with graphs, leading to a new paradigm called GraphLLM. Despite the rapid development of GraphLLM methods in recent years, the progress and understanding of this field remain unclear due to the lack of a benchmark with consistent experimental protocols. To bridge this gap, we introduce GLBench, the first comprehensive benchmark for evaluating GraphLLM methods in both supervised and zero-shot scenarios. GLBench provides a fair and thorough evaluation of different categories of GraphLLM methods, along with traditional baselines such as graph neural networks. Through extensive experiments on a collection of real-world datasets with consistent data processing and splitting strategies, we have uncovered several key findings. Firstly, GraphLLM methods outperform traditional baselines in supervised settings, with LLM-as-enhancers showing the most robust performance. However, using LLMs as predictors is less effective and often leads to uncontrollable output issues. We also notice that no clear scaling laws exist for current GraphLLM methods. In addition, both structures and semantics are crucial for effective zero-shot transfer, and our proposed simple baseline can even outperform several models tailored for zero-shot scenarios. The data and code of the benchmark can be found at https://github.com/NineAbyss/GLBench.