 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTune-Your-Style: Intensity-tunable 3D Style Transfer with Gaussian Splatting
Jan 31, 20263D style transfer refers to the artistic stylization of 3D assets based on reference style images. Recently, 3DGS-based stylization methods have drawn considerable attention, primarily due to their markedly enhanced training and rendering speeds. However, a vital challenge for 3D style transfer is to strike a balance between the content and the patterns and colors of the style. Although the existing methods strive to achieve relatively balanced outcomes, the fixed-output paradigm struggles to adapt to the diverse content-style balance requirements from different users. In this work, we introduce a creative intensity-tunable 3D style transfer paradigm, dubbed \textbf{Tune-Your-Style}, which allows users to flexibly adjust the style intensity injected into the scene to match their desired content-style balance, thus enhancing the customizability of 3D style transfer. To achieve this goal, we first introduce Gaussian neurons to explicitly model the style intensity and parameterize a learnable style tuner to achieve intensity-tunable style injection. To facilitate the learning of tunable stylization, we further propose the tunable stylization guidance, which obtains multi-view consistent stylized views from diffusion models through cross-view style alignment, and then employs a two-stage optimization strategy to provide stable and efficient guidance by modulating the balance between full-style guidance from the stylized views and zero-style guidance from the initial rendering. Extensive experiments demonstrate that our method not only delivers visually appealing results, but also exhibits flexible customizability for 3D style transfer. Project page is available at https://zhao-yian.github.io/TuneStyle.
MagicComp: Training-free Dual-Phase Refinement for Compositional Video Generation
Mar 18, 2025Text-to-video (T2V) generation has made significant strides with diffusion models. However, existing methods still struggle with accurately binding attributes, determining spatial relationships, and capturing complex action interactions between multiple subjects. To address these limitations, we propose MagicComp, a training-free method that enhances compositional T2V generation through dual-phase refinement. Specifically, (1) During the Conditioning Stage: We introduce the Semantic Anchor Disambiguation to reinforces subject-specific semantics and resolve inter-subject ambiguity by progressively injecting the directional vectors of semantic anchors into original text embedding; (2) During the Denoising Stage: We propose Dynamic Layout Fusion Attention, which integrates grounding priors and model-adaptive spatial perception to flexibly bind subjects to their spatiotemporal regions through masked attention modulation. Furthermore, MagicComp is a model-agnostic and versatile approach, which can be seamlessly integrated into existing T2V architectures. Extensive experiments on T2V-CompBench and VBench demonstrate that MagicComp outperforms state-of-the-art methods, highlighting its potential for applications such as complex prompt-based and trajectory-controllable video generation. Project page: https://hong-yu-zhang.github.io/MagicComp-Page/.
Qwen2.5-VL Technical Report
Feb 19, 2025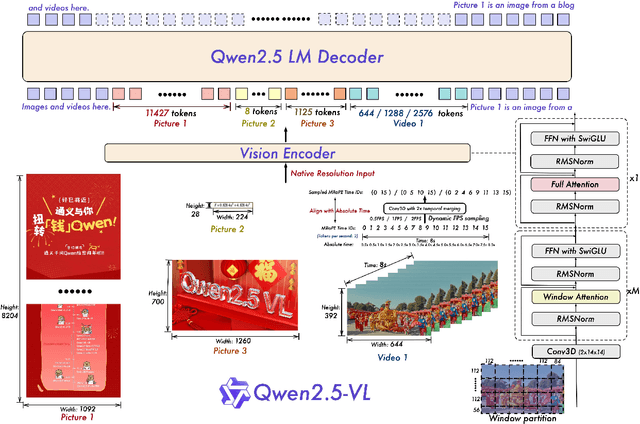
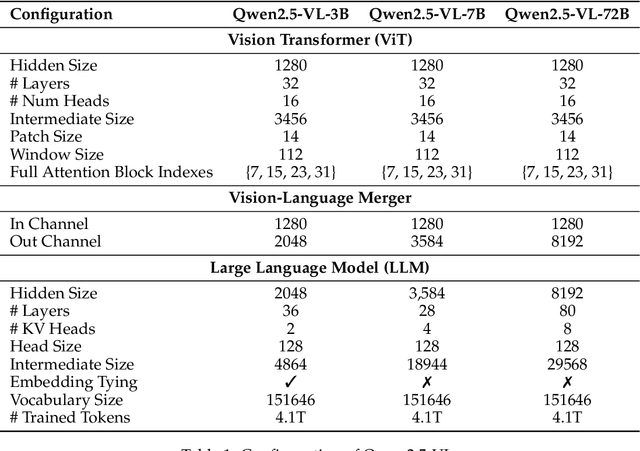
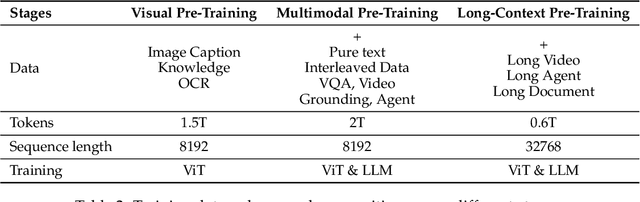
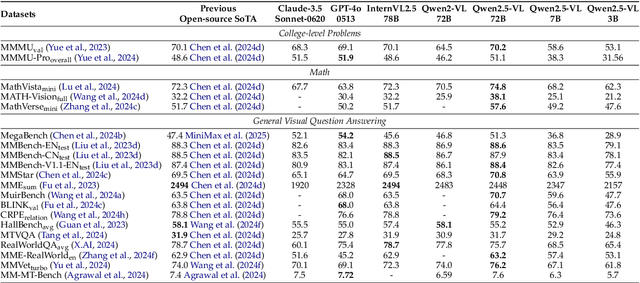
We introduce Qwen2.5-VL, the latest flagship model of Qwen vision-language series, which demonstrates significant advancements in both foundational capabilities and innovative functionalities. Qwen2.5-VL achieves a major leap forward in understanding and interacting with the world through enhanced visual recognition, precise object localization, robust document parsing, and long-video comprehension. A standout feature of Qwen2.5-VL is its ability to localize objects using bounding boxes or points accurately. It provides robust structured data extraction from invoices, forms, and tables, as well as detailed analysis of charts, diagrams, and layouts. To handle complex inputs, Qwen2.5-VL introduces dynamic resolution processing and absolute time encoding, enabling it to process images of varying sizes and videos of extended durations (up to hours) with second-level event localization. This allows the model to natively perceive spatial scales and temporal dynamics without relying on traditional normalization techniques. By training a native dynamic-resolution Vision Transformer (ViT) from scratch and incorporating Window Attention, we reduce computational overhead while maintaining native resolution. As a result, Qwen2.5-VL excels not only in static image and document understanding but also as an interactive visual agent capable of reasoning, tool usage, and task execution in real-world scenarios such as operating computers and mobile devices. Qwen2.5-VL is available in three sizes, addressing diverse use cases from edge AI to high-performance computing. The flagship Qwen2.5-VL-72B model matches state-of-the-art models like GPT-4o and Claude 3.5 Sonnet, particularly excelling in document and diagram understanding. Additionally, Qwen2.5-VL maintains robust linguistic performance, preserving the core language competencies of the Qwen2.5 LLM.
VideoRefer Suite: Advancing Spatial-Temporal Object Understanding with Video LLM
Jan 08, 2025Video Large Language Models (Video LLMs) have recently exhibited remarkable capabilities in general video understanding. However, they mainly focus on holistic comprehension and struggle with capturing fine-grained spatial and temporal details. Besides, the lack of high-quality object-level video instruction data and a comprehensive benchmark further hinders their advancements. To tackle these challenges, we introduce the VideoRefer Suite to empower Video LLM for finer-level spatial-temporal video understanding, i.e., enabling perception and reasoning on any objects throughout the video. Specially, we thoroughly develop VideoRefer Suite across three essential aspects: dataset, model, and benchmark. Firstly, we introduce a multi-agent data engine to meticulously curate a large-scale, high-quality object-level video instruction dataset, termed VideoRefer-700K. Next, we present the VideoRefer model, which equips a versatile spatial-temporal object encoder to capture precise regional and sequential representations. Finally, we meticulously create a VideoRefer-Bench to comprehensively assess the spatial-temporal understanding capability of a Video LLM, evaluating it across various aspects. Extensive experiments and analyses demonstrate that our VideoRefer model not only achieves promising performance on video referring benchmarks but also facilitates general video understanding capabilities.
Large Language Models Can Self-Improve in Long-context Reasoning
Nov 12, 2024



Large language models (LLMs) have achieved substantial progress in processing long contexts but still struggle with long-context reasoning. Existing approaches typically involve fine-tuning LLMs with synthetic data, which depends on annotations from human experts or advanced models like GPT-4, thus restricting further advancements. To address this issue, we investigate the potential for LLMs to self-improve in long-context reasoning and propose \ours, an approach specifically designed for this purpose. This approach is straightforward: we sample multiple outputs for each question, score them with Minimum Bayes Risk, and then apply supervised fine-tuning or preference optimization based on these outputs. Extensive experiments on several leading LLMs demonstrate the effectiveness of \ours, with an absolute improvement of $4.2$ points for Llama-3.1-8B-Instruct. Furthermore, \ours achieves superior performance compared to prior approaches that depend on data produced by human experts or advanced models. We anticipate that this work will open new avenues for self-improvement techniques in long-context scenarios, which are essential for the continual advancement of LLMs.
Breaking the Memory Barrier: Near Infinite Batch Size Scaling for Contrastive Loss
Oct 22, 2024



Contrastive loss is a powerful approach for representation learning, where larger batch sizes enhance performance by providing more negative samples to better distinguish between similar and dissimilar data. However, scaling batch sizes is constrained by the quadratic growth in GPU memory consumption, primarily due to the full instantiation of the similarity matrix. To address this, we propose a tile-based computation strategy that partitions the contrastive loss calculation into arbitrary small blocks, avoiding full materialization of the similarity matrix. Furthermore, we introduce a multi-level tiling strategy to leverage the hierarchical structure of distributed systems, employing ring-based communication at the GPU level to optimize synchronization and fused kernels at the CUDA core level to reduce I/O overhead. Experimental results show that the proposed method scales batch sizes to unprecedented levels. For instance, it enables contrastive training of a CLIP-ViT-L/14 model with a batch size of 4M or 12M using 8 or 32 A800 80GB without sacrificing any accuracy. Compared to SOTA memory-efficient solutions, it achieves a two-order-of-magnitude reduction in memory while maintaining comparable speed. The code will be made publicly available.
The Curse of Multi-Modalities: Evaluating Hallucinations of Large Multimodal Models across Language, Visual, and Audio
Oct 16, 2024



Recent advancements in large multimodal models (LMMs) have significantly enhanced performance across diverse tasks, with ongoing efforts to further integrate additional modalities such as video and audio. However, most existing LMMs remain vulnerable to hallucinations, the discrepancy between the factual multimodal input and the generated textual output, which has limited their applicability in various real-world scenarios. This paper presents the first systematic investigation of hallucinations in LMMs involving the three most common modalities: language, visual, and audio. Our study reveals two key contributors to hallucinations: overreliance on unimodal priors and spurious inter-modality correlations. To address these challenges, we introduce the benchmark The Curse of Multi-Modalities (CMM), which comprehensively evaluates hallucinations in LMMs, providing a detailed analysis of their underlying issues. Our findings highlight key vulnerabilities, including imbalances in modality integration and biases from training data, underscoring the need for balanced cross-modal learning and enhanced hallucination mitigation strategies. Based on our observations and findings, we suggest potential research directions that could enhance the reliability of LMMs.
A Survey on the Honesty of Large Language Models
Sep 27, 2024



Honesty is a fundamental principle for aligning large language models (LLMs) with human values, requiring these models to recognize what they know and don't know and be able to faithfully express their knowledge. Despite promising, current LLMs still exhibit significant dishonest behaviors, such as confidently presenting wrong answers or failing to express what they know. In addition, research on the honesty of LLMs also faces challenges, including varying definitions of honesty, difficulties in distinguishing between known and unknown knowledge, and a lack of comprehensive understanding of related research. To address these issues, we provide a survey on the honesty of LLMs, covering its clarification, evaluation approaches, and strategies for improvement. Moreover, we offer insights for future research, aiming to inspire further exploration in this important area.
Local Action-Guided Motion Diffusion Model for Text-to-Motion Generation
Jul 15, 2024



Text-to-motion generation requires not only grounding local actions in language but also seamlessly blending these individual actions to synthesize diverse and realistic global motions. However, existing motion generation methods primarily focus on the direct synthesis of global motions while neglecting the importance of generating and controlling local actions. In this paper, we propose the local action-guided motion diffusion model, which facilitates global motion generation by utilizing local actions as fine-grained control signals. Specifically, we provide an automated method for reference local action sampling and leverage graph attention networks to assess the guiding weight of each local action in the overall motion synthesis. During the diffusion process for synthesizing global motion, we calculate the local-action gradient to provide conditional guidance. This local-to-global paradigm reduces the complexity associated with direct global motion generation and promotes motion diversity via sampling diverse actions as conditions. Extensive experiments on two human motion datasets, i.e., HumanML3D and KIT, demonstrate the effectiveness of our method. Furthermore, our method provides flexibility in seamlessly combining various local actions and continuous guiding weight adjustment, accommodating diverse user preferences, which may hold potential significance for the community. The project page is available at https://jpthu17.github.io/GuidedMotion-project/.
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Jun 11, 2024



In this paper, we present the VideoLLaMA 2, a set of Video Large Language Models (Video-LLMs) designed to enhance spatial-temporal modeling and audio understanding in video and audio-oriented tasks. Building upon its predecessor, VideoLLaMA 2 incorporates a tailor-made Spatial-Temporal Convolution (STC) connector, which effectively captures the intricate spatial and temporal dynamics of video data. Additionally, we integrate an Audio Branch into the model through joint training, thereby enriching the multimodal understanding capabilities of the model by seamlessly incorporating audio cues. Comprehensive evaluations on multiple-choice video question answering (MC-VQA), open-ended video question answering (OE-VQA), and video captioning (VC) tasks demonstrate that VideoLLaMA 2 consistently achieves competitive results among open-source models and even gets close to some proprietary models on several benchmarks. Furthermore, VideoLLaMA 2 exhibits reasonable improvements in audio-only and audio-video question-answering (AQA & OE-AVQA) benchmarks over existing models. These advancements underline VideoLLaMA 2's superior performance in multimodal comprehension, setting a new standard for intelligent video analysis systems. All models are public to facilitate further research.