 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous and Adept Snapshot Distillation for 3D Semantic Segmentation
Jun 24, 2026Multi-modal fusion and multi-model ensembling are prevalent in enhancing the performance of 3D semantic segmentation. Despite the impressive performance, these methods either rely on auxiliary input signals or suffer from costly computational expense. To efficaciously enhance the segmentation performance without introducing intolerable costs, we propose to transfer the rich knowledge from the multi-modal model (i.e., point clouds and images) and multiple model experts to the point-cloudbased network through knowledge distillation. Specifically, we present Information-oriented Heterogeneous Distillation (IHD) to help the uni-modal model absorb the complementary knowledge from the multi-modal teacher. We design the Information-Oriented Filtering (IOF) strategy to select informative images from the continuous image sequence for multi-modal fusion. This practice can boost the performance of the multi-modal teacher, thus benefiting the learning of the student. Besides, as opposed to vanilla model ensembling that requires the separate training of each expert, we propose Adept Snapshot Distillation (ASD). ASD treats the freely available model snapshots generated during the training phase as multiple experts, which significantly reduces the training cost for model ensembling. For each expert teacher, it only provides supervision to the student in the class where it is adept. The resulting Heterogeneous and Adept Snapshot Knowledge Distillation, dubbed HAS-KD, attains state-of-the-art results on ScanNetV2 and S3DIS datasets. HAS-KD can be seamlessly integrated into contemporary 3D segmentation algorithms and bring considerable gains without introducing extra inference burdens. The code will be made publicly available upon publication.
InfoQuant: Shaping Activation Distributions for Low-Bit LLM Quantization
May 25, 2026Low-bit activation quantization remains a major bottleneck in efficient large language model (LLM) deployment. The difficulty is not only that activations contain outliers, but that their distributions are often poorly matched to a low-bit uniform quantizer. Existing post-training quantization (PTQ) methods suppress peaks, balance channels, or minimize reconstruction error, yet they rarely specify what activation distribution is actually easy to discretize. As a result, activations may appear numerically smoother while still incurring large quantization error because the quantization range remains wide or most values collapse into a few levels near the mean. We recast activation transformation as quantizer-facing distribution design and analyze quantization error from an information-theoretic perspective. Our analysis shows that quantization-friendly activations should jointly have a smaller numerical range and sufficient dispersion within that range. Guided by this analysis, we propose InfoQuant, a train-free method that employs Peak Suppression Orthogonal Transformation (PSOT) to shape activations into more quantization-friendly distributions. We further introduce adaptive outlier-token selection to improve the robustness of PSOT during optimization. Across multiple LLM families, InfoQuant consistently outperforms prior PTQ and end-to-end training baselines. Under W4A4KV4, it preserves 97% of floating-point accuracy on average and reduces the LLaMA-2 13B performance gap by 42% over the previous state of the art. Code is available at [https://github.com/LLIKKE/InfoQuant](https://github.com/LLIKKE/InfoQuant)
HeteroCache: A Dynamic Retrieval Approach to Heterogeneous KV Cache Compression for Long-Context LLM Inference
Jan 20, 2026The linear memory growth of the KV cache poses a significant bottleneck for LLM inference in long-context tasks. Existing static compression methods often fail to preserve globally important information, principally because they overlook the attention drift phenomenon where token significance evolves dynamically. Although recent dynamic retrieval approaches attempt to address this issue, they typically suffer from coarse-grained caching strategies and incur high I/O overhead due to frequent data transfers. To overcome these limitations, we propose HeteroCache, a training-free dynamic compression framework. Our method is built on two key insights: attention heads exhibit diverse temporal heterogeneity, and there is significant spatial redundancy among heads within the same layer. Guided by these insights, HeteroCache categorizes heads based on stability and redundancy. Consequently, we apply a fine-grained weighting strategy that allocates larger cache budgets to heads with rapidly shifting attention to capture context changes, thereby addressing the inefficiency of coarse-grained strategies. Furthermore, we employ a hierarchical storage mechanism in which a subset of representative heads monitors attention shift, and trigger an asynchronous, on-demand retrieval of contexts from the CPU, effectively hiding I/O latency. Finally, experiments demonstrate that HeteroCache achieves state-of-the-art performance on multiple long-context benchmarks and accelerates decoding by up to $3\times$ compared to the original model in the 224K context. Our code will be open-source.
HEAPr: Hessian-based Efficient Atomic Expert Pruning in Output Space
Sep 26, 2025Mixture-of-Experts (MoE) architectures in large language models (LLMs) deliver exceptional performance and reduced inference costs compared to dense LLMs. However, their large parameter counts result in prohibitive memory requirements, limiting practical deployment. While existing pruning methods primarily focus on expert-level pruning, this coarse granularity often leads to substantial accuracy degradation. In this work, we introduce HEAPr, a novel pruning algorithm that decomposes experts into smaller, indivisible atomic experts, enabling more precise and flexible atomic expert pruning. To measure the importance of each atomic expert, we leverage second-order information based on principles similar to Optimal Brain Surgeon (OBS) theory. To address the computational and storage challenges posed by second-order information, HEAPr exploits the inherent properties of atomic experts to transform the second-order information from expert parameters into that of atomic expert parameters, and further simplifies it to the second-order information of atomic expert outputs. This approach reduces the space complexity from $O(d^4)$, where d is the model's dimensionality, to $O(d^2)$. HEAPr requires only two forward passes and one backward pass on a small calibration set to compute the importance of atomic experts. Extensive experiments on MoE models, including DeepSeek MoE and Qwen MoE family, demonstrate that HEAPr outperforms existing expert-level pruning methods across a wide range of compression ratios and benchmarks. Specifically, HEAPr achieves nearly lossless compression at compression ratios of 20% ~ 25% in most models, while also reducing FLOPs nearly by 20%. The code can be found at \href{https://github.com/LLIKKE/HEAPr}{https://github.com/LLIKKE/HEAPr}.
Maestro: Joint Graph & Config Optimization for Reliable AI Agents
Sep 04, 2025Building reliable LLM agents requires decisions at two levels: the graph (which modules exist and how information flows) and the configuration of each node (models, prompts, tools, control knobs). Most existing optimizers tune configurations while holding the graph fixed, leaving structural failure modes unaddressed. We introduce Maestro, a framework-agnostic holistic optimizer for LLM agents that jointly searches over graphs and configurations to maximize agent quality, subject to explicit rollout/token budgets. Beyond numeric metrics, Maestro leverages reflective textual feedback from traces to prioritize edits, improving sample efficiency and targeting specific failure modes. On the IFBench and HotpotQA benchmarks, Maestro consistently surpasses leading prompt optimizers--MIPROv2, GEPA, and GEPA+Merge--by an average of 12%, 4.9%, and 4.86%, respectively; even when restricted to prompt-only optimization, it still leads by 9.65%, 2.37%, and 2.41%. Maestro achieves these results with far fewer rollouts than GEPA. We further show large gains on two applications (interviewer & RAG agents), highlighting that joint graph & configuration search addresses structural failure modes that prompt tuning alone cannot fix.
GeoCAD: Local Geometry-Controllable CAD Generation
Jun 12, 2025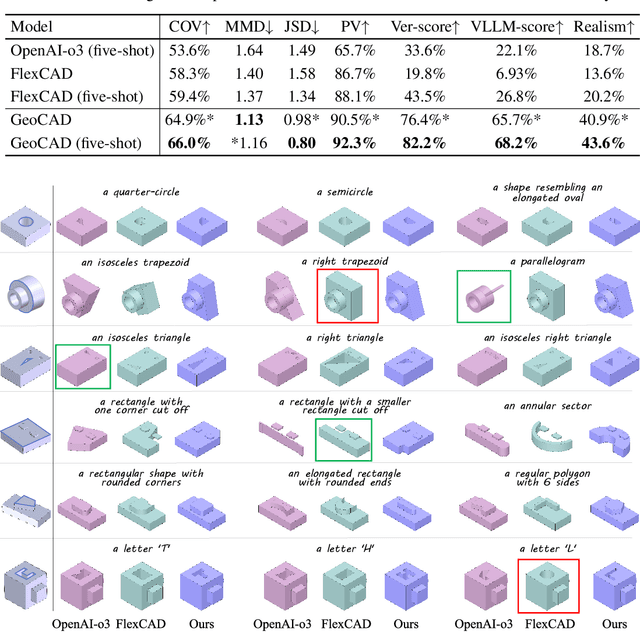
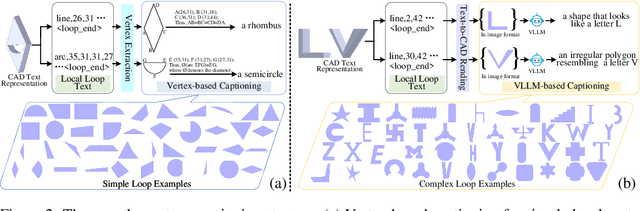
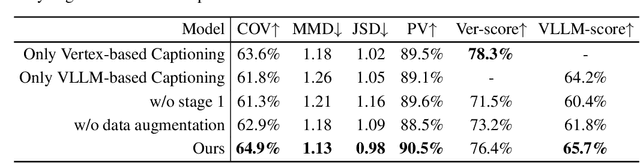

Local geometry-controllable computer-aided design (CAD) generation aims to modify local parts of CAD models automatically, enhancing design efficiency. It also ensures that the shapes of newly generated local parts follow user-specific geometric instructions (e.g., an isosceles right triangle or a rectangle with one corner cut off). However, existing methods encounter challenges in achieving this goal. Specifically, they either lack the ability to follow textual instructions or are unable to focus on the local parts. To address this limitation, we introduce GeoCAD, a user-friendly and local geometry-controllable CAD generation method. Specifically, we first propose a complementary captioning strategy to generate geometric instructions for local parts. This strategy involves vertex-based and VLLM-based captioning for systematically annotating simple and complex parts, respectively. In this way, we caption $\sim$221k different local parts in total. In the training stage, given a CAD model, we randomly mask a local part. Then, using its geometric instruction and the remaining parts as input, we prompt large language models (LLMs) to predict the masked part. During inference, users can specify any local part for modification while adhering to a variety of predefined geometric instructions. Extensive experiments demonstrate the effectiveness of GeoCAD in generation quality, validity and text-to-CAD consistency. Code will be available at https://github.com/Zhanwei-Z/GeoCAD.
HieraEdgeNet: A Multi-Scale Edge-Enhanced Framework for Automated Pollen Recognition
Jun 09, 2025Automated pollen recognition is vital to paleoclimatology, biodiversity monitoring, and public health, yet conventional methods are hampered by inefficiency and subjectivity. Existing deep learning models often struggle to achieve the requisite localization accuracy for microscopic targets like pollen, which are characterized by their minute size, indistinct edges, and complex backgrounds. To overcome this limitation, we introduce HieraEdgeNet, a multi-scale edge-enhancement framework. The framework's core innovation is the introduction of three synergistic modules: the Hierarchical Edge Module (HEM), which explicitly extracts a multi-scale pyramid of edge features that corresponds to the semantic hierarchy at early network stages; the Synergistic Edge Fusion (SEF) module, for deeply fusing these edge priors with semantic information at each respective scale; and the Cross Stage Partial Omni-Kernel Module (CSPOKM), which maximally refines the most detail-rich feature layers using an Omni-Kernel operator - comprising anisotropic large-kernel convolutions and mixed-domain attention - all within a computationally efficient Cross-Stage Partial (CSP) framework. On a large-scale dataset comprising 120 pollen classes, HieraEdgeNet achieves a mean Average Precision (mAP@.5) of 0.9501, significantly outperforming state-of-the-art baseline models such as YOLOv12n and RT-DETR. Furthermore, qualitative analysis confirms that our approach generates feature representations that are more precisely focused on object boundaries. By systematically integrating edge information, HieraEdgeNet provides a robust and powerful solution for high-precision, high-efficiency automated detection of microscopic objects.
DyePack: Provably Flagging Test Set Contamination in LLMs Using Backdoors
May 29, 2025Open benchmarks are essential for evaluating and advancing large language models, offering reproducibility and transparency. However, their accessibility makes them likely targets of test set contamination. In this work, we introduce DyePack, a framework that leverages backdoor attacks to identify models that used benchmark test sets during training, without requiring access to the loss, logits, or any internal details of the model. Like how banks mix dye packs with their money to mark robbers, DyePack mixes backdoor samples with the test data to flag models that trained on it. We propose a principled design incorporating multiple backdoors with stochastic targets, enabling exact false positive rate (FPR) computation when flagging every model. This provably prevents false accusations while providing strong evidence for every detected case of contamination. We evaluate DyePack on five models across three datasets, covering both multiple-choice and open-ended generation tasks. For multiple-choice questions, it successfully detects all contaminated models with guaranteed FPRs as low as 0.000073% on MMLU-Pro and 0.000017% on Big-Bench-Hard using eight backdoors. For open-ended generation tasks, it generalizes well and identifies all contaminated models on Alpaca with a guaranteed false positive rate of just 0.127% using six backdoors.
Gaming Tool Preferences in Agentic LLMs
May 23, 2025Large language models (LLMs) can now access a wide range of external tools, thanks to the Model Context Protocol (MCP). This greatly expands their abilities as various agents. However, LLMs rely entirely on the text descriptions of tools to decide which ones to use--a process that is surprisingly fragile. In this work, we expose a vulnerability in prevalent tool/function-calling protocols by investigating a series of edits to tool descriptions, some of which can drastically increase a tool's usage from LLMs when competing with alternatives. Through controlled experiments, we show that tools with properly edited descriptions receive over 10 times more usage from GPT-4.1 and Qwen2.5-7B than tools with original descriptions. We further evaluate how various edits to tool descriptions perform when competing directly with one another and how these trends generalize or differ across a broader set of 10 different models. These phenomenons, while giving developers a powerful way to promote their tools, underscore the need for a more reliable foundation for agentic LLMs to select and utilize tools and resources.
Chain-of-Defensive-Thought: Structured Reasoning Elicits Robustness in Large Language Models against Reference Corruption
Apr 29, 2025Chain-of-thought prompting has demonstrated great success in facilitating the reasoning abilities of large language models. In this work, we explore how these enhanced reasoning abilities can be exploited to improve the robustness of large language models in tasks that are not necessarily reasoning-focused. In particular, we show how a wide range of large language models exhibit significantly improved robustness against reference corruption using a simple method called chain-of-defensive-thought, where only a few exemplars with structured and defensive reasoning are provided as demonstrations. Empirically, the improvements can be astounding, especially given the simplicity and applicability of the method. For example, in the Natural Questions task, the accuracy of GPT-4o degrades from 60% to as low as 3% with standard prompting when 1 out of 10 references provided is corrupted with prompt injection attacks. In contrast, GPT-4o using chain-of-defensive-thought prompting maintains an accuracy of 50%.