 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Spatial Intelligence from a Generative Perspective
Apr 22, 2026Spatial intelligence is essential for multimodal large language models, yet current benchmarks largely assess it only from an understanding perspective. We ask whether modern generative or unified multimodal models also possess generative spatial intelligence (GSI), the ability to respect and manipulate 3D spatial constraints during image generation, and whether such capability can be measured or improved. We introduce GSI-Bench, the first benchmark designed to quantify GSI through spatially grounded image editing. It consists of two complementary components: GSI-Real, a high-quality real-world dataset built via a 3D-prior-guided generation and filtering pipeline, and GSI-Syn, a large-scale synthetic benchmark with controllable spatial operations and fully automated labeling. Together with a unified evaluation protocol, GSI-Bench enables scalable, model-agnostic assessment of spatial compliance and editing fidelity. Experiments show that fine-tuning unified multimodal models on GSI-Syn yields substantial gains on both synthetic and real tasks and, strikingly, also improves downstream spatial understanding. This provides the first clear evidence that generative training can tangibly strengthen spatial reasoning, establishing a new pathway for advancing spatial intelligence in multimodal models.
Preserving Source Video Realism: High-Fidelity Face Swapping for Cinematic Quality
Dec 08, 2025Video face swapping is crucial in film and entertainment production, where achieving high fidelity and temporal consistency over long and complex video sequences remains a significant challenge. Inspired by recent advances in reference-guided image editing, we explore whether rich visual attributes from source videos can be similarly leveraged to enhance both fidelity and temporal coherence in video face swapping. Building on this insight, this work presents LivingSwap, the first video reference guided face swapping model. Our approach employs keyframes as conditioning signals to inject the target identity, enabling flexible and controllable editing. By combining keyframe conditioning with video reference guidance, the model performs temporal stitching to ensure stable identity preservation and high-fidelity reconstruction across long video sequences. To address the scarcity of data for reference-guided training, we construct a paired face-swapping dataset, Face2Face, and further reverse the data pairs to ensure reliable ground-truth supervision. Extensive experiments demonstrate that our method achieves state-of-the-art results, seamlessly integrating the target identity with the source video's expressions, lighting, and motion, while significantly reducing manual effort in production workflows. Project webpage: https://aim-uofa.github.io/LivingSwap
GCA-3D: Towards Generalized and Consistent Domain Adaptation of 3D Generators
Dec 20, 2024Recently, 3D generative domain adaptation has emerged to adapt the pre-trained generator to other domains without collecting massive datasets and camera pose distributions. Typically, they leverage large-scale pre-trained text-to-image diffusion models to synthesize images for the target domain and then fine-tune the 3D model. However, they suffer from the tedious pipeline of data generation, which inevitably introduces pose bias between the source domain and synthetic dataset. Furthermore, they are not generalized to support one-shot image-guided domain adaptation, which is more challenging due to the more severe pose bias and additional identity bias introduced by the single image reference. To address these issues, we propose GCA-3D, a generalized and consistent 3D domain adaptation method without the intricate pipeline of data generation. Different from previous pipeline methods, we introduce multi-modal depth-aware score distillation sampling loss to efficiently adapt 3D generative models in a non-adversarial manner. This multi-modal loss enables GCA-3D in both text prompt and one-shot image prompt adaptation. Besides, it leverages per-instance depth maps from the volume rendering module to mitigate the overfitting problem and retain the diversity of results. To enhance the pose and identity consistency, we further propose a hierarchical spatial consistency loss to align the spatial structure between the generated images in the source and target domain. Experiments demonstrate that GCA-3D outperforms previous methods in terms of efficiency, generalization, pose accuracy, and identity consistency.
Unleashing the Potential of the Diffusion Model in Few-shot Semantic Segmentation
Oct 03, 2024



The Diffusion Model has not only garnered noteworthy achievements in the realm of image generation but has also demonstrated its potential as an effective pretraining method utilizing unlabeled data. Drawing from the extensive potential unveiled by the Diffusion Model in both semantic correspondence and open vocabulary segmentation, our work initiates an investigation into employing the Latent Diffusion Model for Few-shot Semantic Segmentation. Recently, inspired by the in-context learning ability of large language models, Few-shot Semantic Segmentation has evolved into In-context Segmentation tasks, morphing into a crucial element in assessing generalist segmentation models. In this context, we concentrate on Few-shot Semantic Segmentation, establishing a solid foundation for the future development of a Diffusion-based generalist model for segmentation. Our initial focus lies in understanding how to facilitate interaction between the query image and the support image, resulting in the proposal of a KV fusion method within the self-attention framework. Subsequently, we delve deeper into optimizing the infusion of information from the support mask and simultaneously re-evaluating how to provide reasonable supervision from the query mask. Based on our analysis, we establish a simple and effective framework named DiffewS, maximally retaining the original Latent Diffusion Model's generative framework and effectively utilizing the pre-training prior. Experimental results demonstrate that our method significantly outperforms the previous SOTA models in multiple settings.
Local Conditional Controlling for Text-to-Image Diffusion Models
Dec 14, 2023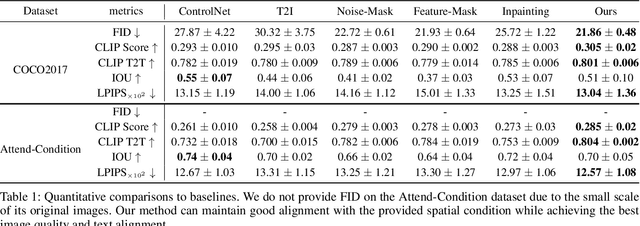

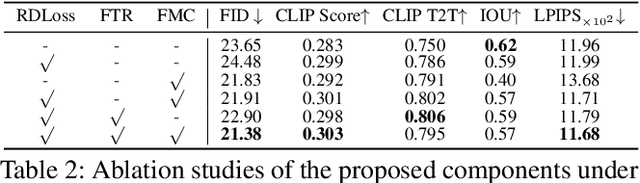

Diffusion models have exhibited impressive prowess in the text-to-image task. Recent methods add image-level controls, e.g., edge and depth maps, to manipulate the generation process together with text prompts to obtain desired images. This controlling process is globally operated on the entire image, which limits the flexibility of control regions. In this paper, we introduce a new simple yet practical task setting: local control. It focuses on controlling specific local areas according to user-defined image conditions, where the rest areas are only conditioned by the original text prompt. This manner allows the users to flexibly control the image generation in a fine-grained way. However, it is non-trivial to achieve this goal. The naive manner of directly adding local conditions may lead to the local control dominance problem. To mitigate this problem, we propose a training-free method that leverages the updates of noised latents and parameters in the cross-attention map during the denosing process to promote concept generation in non-control areas. Moreover, we use feature mask constraints to mitigate the degradation of synthesized image quality caused by information differences inside and outside the local control area. Extensive experiments demonstrate that our method can synthesize high-quality images to the prompt under local control conditions. Code is available at https://github.com/YibooZhao/Local-Control.