 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybridVLA: Collaborative Diffusion and Autoregression in a Unified Vision-Language-Action Model
Mar 13, 2025Recent advancements in vision-language models (VLMs) for common-sense reasoning have led to the development of vision-language-action (VLA) models, enabling robots to perform generalized manipulation. Although existing autoregressive VLA methods leverage large-scale pretrained knowledge, they disrupt the continuity of actions. Meanwhile, some VLA methods incorporate an additional diffusion head to predict continuous actions, relying solely on VLM-extracted features, which limits their reasoning capabilities. In this paper, we introduce HybridVLA, a unified framework that seamlessly integrates the strengths of both autoregressive and diffusion policies within a single large language model, rather than simply connecting them. To bridge the generation gap, a collaborative training recipe is proposed that injects the diffusion modeling directly into the next-token prediction. With this recipe, we find that these two forms of action prediction not only reinforce each other but also exhibit varying performance across different tasks. Therefore, we design a collaborative action ensemble mechanism that adaptively fuses these two predictions, leading to more robust control. In experiments, HybridVLA outperforms previous state-of-the-art VLA methods across various simulation and real-world tasks, including both single-arm and dual-arm robots, while demonstrating stable manipulation in previously unseen configurations.
PiSA: A Self-Augmented Data Engine and Training Strategy for 3D Understanding with Large Models
Mar 13, 2025



3D Multimodal Large Language Models (MLLMs) have recently made substantial advancements. However, their potential remains untapped, primarily due to the limited quantity and suboptimal quality of 3D datasets. Current approaches attempt to transfer knowledge from 2D MLLMs to expand 3D instruction data, but still face modality and domain gaps. To this end, we introduce PiSA-Engine (Point-Self-Augmented-Engine), a new framework for generating instruction point-language datasets enriched with 3D spatial semantics. We observe that existing 3D MLLMs offer a comprehensive understanding of point clouds for annotation, while 2D MLLMs excel at cross-validation by providing complementary information. By integrating holistic 2D and 3D insights from off-the-shelf MLLMs, PiSA-Engine enables a continuous cycle of high-quality data generation. We select PointLLM as the baseline and adopt this co-evolution training framework to develop an enhanced 3D MLLM, termed PointLLM-PiSA. Additionally, we identify limitations in previous 3D benchmarks, which often feature coarse language captions and insufficient category diversity, resulting in inaccurate evaluations. To address this gap, we further introduce PiSA-Bench, a comprehensive 3D benchmark covering six key aspects with detailed and diverse labels. Experimental results demonstrate PointLLM-PiSA's state-of-the-art performance in zero-shot 3D object captioning and generative classification on our PiSA-Bench, achieving significant improvements of 46.45% (+8.33%) and 63.75% (+16.25%), respectively. We will release the code, datasets, and benchmark.
MME-CoT: Benchmarking Chain-of-Thought in Large Multimodal Models for Reasoning Quality, Robustness, and Efficiency
Feb 13, 2025



Answering questions with Chain-of-Thought (CoT) has significantly enhanced the reasoning capabilities of Large Language Models (LLMs), yet its impact on Large Multimodal Models (LMMs) still lacks a systematic assessment and in-depth investigation. In this paper, we introduce MME-CoT, a specialized benchmark evaluating the CoT reasoning performance of LMMs, spanning six domains: math, science, OCR, logic, space-time, and general scenes. As the first comprehensive study in this area, we propose a thorough evaluation suite incorporating three novel metrics that assess the reasoning quality, robustness, and efficiency at a fine-grained level. Leveraging curated high-quality data and a unique evaluation strategy, we conduct an in-depth analysis of state-of-the-art LMMs, uncovering several key insights: 1) Models with reflection mechanism demonstrate a superior CoT quality, with Kimi k1.5 outperforming GPT-4o and demonstrating the highest quality results; 2) CoT prompting often degrades LMM performance on perception-heavy tasks, suggesting a potentially harmful overthinking behavior; and 3) Although the CoT quality is high, LMMs with reflection exhibit significant inefficiency in both normal response and self-correction phases. We hope MME-CoT serves as a foundation for advancing multimodal reasoning in LMMs. Project Page: https://mmecot.github.io/
IMAGINE-E: Image Generation Intelligence Evaluation of State-of-the-art Text-to-Image Models
Jan 23, 2025



With the rapid development of diffusion models, text-to-image(T2I) models have made significant progress, showcasing impressive abilities in prompt following and image generation. Recently launched models such as FLUX.1 and Ideogram2.0, along with others like Dall-E3 and Stable Diffusion 3, have demonstrated exceptional performance across various complex tasks, raising questions about whether T2I models are moving towards general-purpose applicability. Beyond traditional image generation, these models exhibit capabilities across a range of fields, including controllable generation, image editing, video, audio, 3D, and motion generation, as well as computer vision tasks like semantic segmentation and depth estimation. However, current evaluation frameworks are insufficient to comprehensively assess these models' performance across expanding domains. To thoroughly evaluate these models, we developed the IMAGINE-E and tested six prominent models: FLUX.1, Ideogram2.0, Midjourney, Dall-E3, Stable Diffusion 3, and Jimeng. Our evaluation is divided into five key domains: structured output generation, realism, and physical consistency, specific domain generation, challenging scenario generation, and multi-style creation tasks. This comprehensive assessment highlights each model's strengths and limitations, particularly the outstanding performance of FLUX.1 and Ideogram2.0 in structured and specific domain tasks, underscoring the expanding applications and potential of T2I models as foundational AI tools. This study provides valuable insights into the current state and future trajectory of T2I models as they evolve towards general-purpose usability. Evaluation scripts will be released at https://github.com/jylei16/Imagine-e.
Can We Generate Images with CoT? Let's Verify and Reinforce Image Generation Step by Step
Jan 23, 2025



Chain-of-Thought (CoT) reasoning has been extensively explored in large models to tackle complex understanding tasks. However, it still remains an open question whether such strategies can be applied to verifying and reinforcing image generation scenarios. In this paper, we provide the first comprehensive investigation of the potential of CoT reasoning to enhance autoregressive image generation. We focus on three techniques: scaling test-time computation for verification, aligning model preferences with Direct Preference Optimization (DPO), and integrating these techniques for complementary effects. Our results demonstrate that these approaches can be effectively adapted and combined to significantly improve image generation performance. Furthermore, given the pivotal role of reward models in our findings, we propose the Potential Assessment Reward Model (PARM) and PARM++, specialized for autoregressive image generation. PARM adaptively assesses each generation step through a potential assessment approach, merging the strengths of existing reward models, and PARM++ further introduces a reflection mechanism to self-correct the generated unsatisfactory image. Using our investigated reasoning strategies, we enhance a baseline model, Show-o, to achieve superior results, with a significant +24% improvement on the GenEval benchmark, surpassing Stable Diffusion 3 by +15%. We hope our study provides unique insights and paves a new path for integrating CoT reasoning with autoregressive image generation. Code and models are released at https://github.com/ZiyuGuo99/Image-Generation-CoT
TAR3D: Creating High-Quality 3D Assets via Next-Part Prediction
Dec 22, 2024



We present TAR3D, a novel framework that consists of a 3D-aware Vector Quantized-Variational AutoEncoder (VQ-VAE) and a Generative Pre-trained Transformer (GPT) to generate high-quality 3D assets. The core insight of this work is to migrate the multimodal unification and promising learning capabilities of the next-token prediction paradigm to conditional 3D object generation. To achieve this, the 3D VQ-VAE first encodes a wide range of 3D shapes into a compact triplane latent space and utilizes a set of discrete representations from a trainable codebook to reconstruct fine-grained geometries under the supervision of query point occupancy. Then, the 3D GPT, equipped with a custom triplane position embedding called TriPE, predicts the codebook index sequence with prefilling prompt tokens in an autoregressive manner so that the composition of 3D geometries can be modeled part by part. Extensive experiments on ShapeNet and Objaverse demonstrate that TAR3D can achieve superior generation quality over existing methods in text-to-3D and image-to-3D tasks
Chimera: Improving Generalist Model with Domain-Specific Experts
Dec 08, 2024



Recent advancements in Large Multi-modal Models (LMMs) underscore the importance of scaling by increasing image-text paired data, achieving impressive performance on general tasks. Despite their effectiveness in broad applications, generalist models are primarily trained on web-scale datasets dominated by natural images, resulting in the sacrifice of specialized capabilities for domain-specific tasks that require extensive domain prior knowledge. Moreover, directly integrating expert models tailored for specific domains is challenging due to the representational gap and imbalanced optimization between the generalist model and experts. To address these challenges, we introduce Chimera, a scalable and low-cost multi-modal pipeline designed to boost the ability of existing LMMs with domain-specific experts. Specifically, we design a progressive training strategy to integrate features from expert models into the input of a generalist LMM. To address the imbalanced optimization caused by the well-aligned general visual encoder, we introduce a novel Generalist-Specialist Collaboration Masking (GSCM) mechanism. This results in a versatile model that excels across the chart, table, math, and document domains, achieving state-of-the-art performance on multi-modal reasoning and visual content extraction tasks, both of which are challenging tasks for assessing existing LMMs.
Lift3D Foundation Policy: Lifting 2D Large-Scale Pretrained Models for Robust 3D Robotic Manipulation
Nov 27, 2024



3D geometric information is essential for manipulation tasks, as robots need to perceive the 3D environment, reason about spatial relationships, and interact with intricate spatial configurations. Recent research has increasingly focused on the explicit extraction of 3D features, while still facing challenges such as the lack of large-scale robotic 3D data and the potential loss of spatial geometry. To address these limitations, we propose the Lift3D framework, which progressively enhances 2D foundation models with implicit and explicit 3D robotic representations to construct a robust 3D manipulation policy. Specifically, we first design a task-aware masked autoencoder that masks task-relevant affordance patches and reconstructs depth information, enhancing the 2D foundation model's implicit 3D robotic representation. After self-supervised fine-tuning, we introduce a 2D model-lifting strategy that establishes a positional mapping between the input 3D points and the positional embeddings of the 2D model. Based on the mapping, Lift3D utilizes the 2D foundation model to directly encode point cloud data, leveraging large-scale pretrained knowledge to construct explicit 3D robotic representations while minimizing spatial information loss. In experiments, Lift3D consistently outperforms previous state-of-the-art methods across several simulation benchmarks and real-world scenarios.
Point Cloud Understanding via Attention-Driven Contrastive Learning
Nov 22, 2024



Recently Transformer-based models have advanced point cloud understanding by leveraging self-attention mechanisms, however, these methods often overlook latent information in less prominent regions, leading to increased sensitivity to perturbations and limited global comprehension. To solve this issue, we introduce PointACL, an attention-driven contrastive learning framework designed to address these limitations. Our method employs an attention-driven dynamic masking strategy that guides the model to focus on under-attended regions, enhancing the understanding of global structures within the point cloud. Then we combine the original pre-training loss with a contrastive learning loss, improving feature discrimination and generalization. Extensive experiments validate the effectiveness of PointACL, as it achieves state-of-the-art performance across a variety of 3D understanding tasks, including object classification, part segmentation, and few-shot learning. Specifically, when integrated with different Transformer backbones like Point-MAE and PointGPT, PointACL demonstrates improved performance on datasets such as ScanObjectNN, ModelNet40, and ShapeNetPart. This highlights its superior capability in capturing both global and local features, as well as its enhanced robustness against perturbations and incomplete data.
Training-free Regional Prompting for Diffusion Transformers
Nov 04, 2024
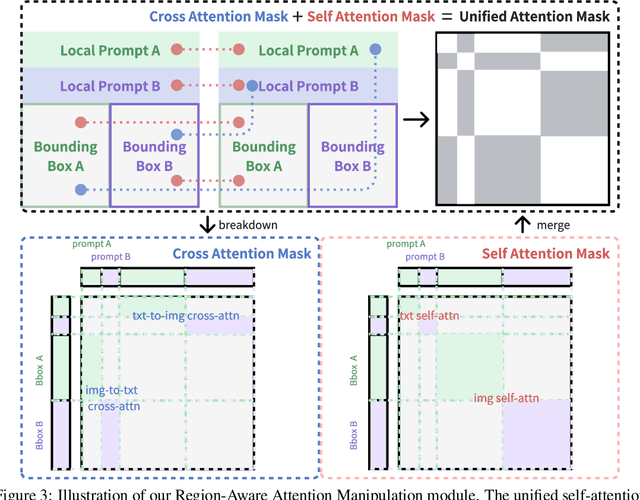
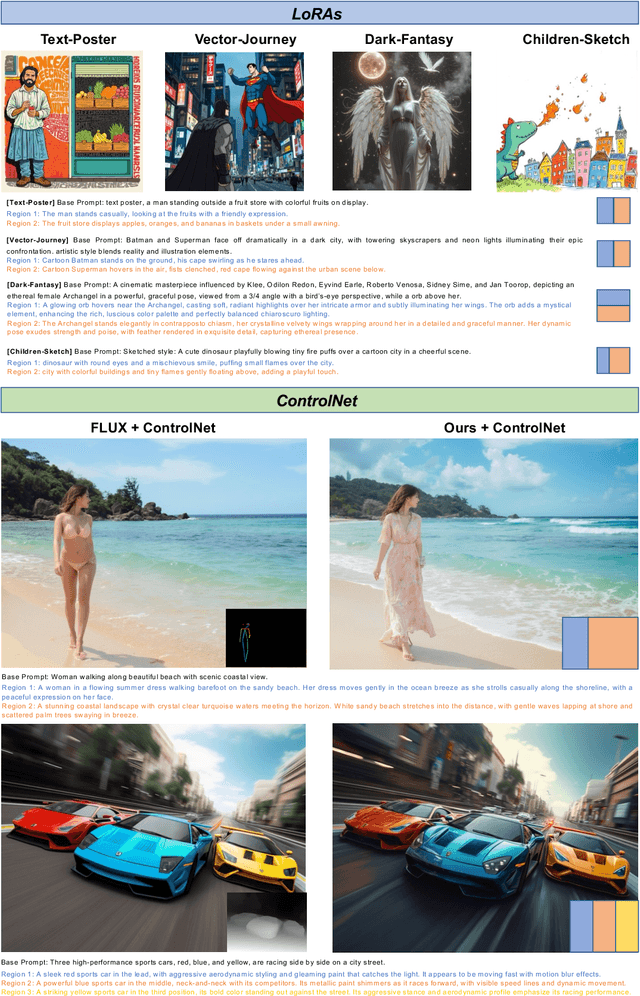

Diffusion models have demonstrated excellent capabilities in text-to-image generation. Their semantic understanding (i.e., prompt following) ability has also been greatly improved with large language models (e.g., T5, Llama). However, existing models cannot perfectly handle long and complex text prompts, especially when the text prompts contain various objects with numerous attributes and interrelated spatial relationships. While many regional prompting methods have been proposed for UNet-based models (SD1.5, SDXL), but there are still no implementations based on the recent Diffusion Transformer (DiT) architecture, such as SD3 and FLUX.1.In this report, we propose and implement regional prompting for FLUX.1 based on attention manipulation, which enables DiT with fined-grained compositional text-to-image generation capability in a training-free manner. Code is available at https://github.com/antonioo-c/Regional-Prompting-FLUX.