 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActFER: Agentic Facial Expression Recognition via Active Tool-Augmented Visual Reasoning
Apr 10, 2026Recent advances in Multimodal Large Language Models (MLLMs) have created new opportunities for facial expression recognition (FER), moving it beyond pure label prediction toward reasoning-based affect understanding. However, existing MLLM-based FER methods still follow a passive paradigm: they rely on externally prepared facial inputs and perform single-pass reasoning over fixed visual evidence, without the capability for active facial perception. To address this limitation, we propose ActFER, an agentic framework that reformulates FER as active visual evidence acquisition followed by multimodal reasoning. Specifically, ActFER dynamically invokes tools for face detection and alignment, selectively zooms into informative local regions, and reasons over facial Action Units (AUs) and emotions through a visual Chain-of-Thought. To realize such behavior, we further develop Utility-Calibrated GRPO (UC-GRPO), a reinforcement learning algorithm tailored to agentic FER. UC-GRPO uses AU-grounded multi-level verifiable rewards to densify supervision, query-conditional contrastive utility estimation to enable sample-aware dynamic credit assignment for local inspection, and emotion-aware EMA calibration to reduce noisy utility estimates while capturing emotion-wise inspection tendencies. This algorithm enables ActFER to learn both when local inspection is beneficial and how to reason over the acquired evidence. Comprehensive experiments show that ActFER trained with UC-GRPO consistently outperforms passive MLLM-based FER baselines and substantially improves AU prediction accuracy.
MELLM: Exploring LLM-Powered Micro-Expression Understanding Enhanced by Subtle Motion Perception
May 11, 2025


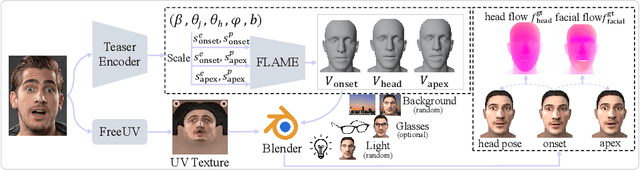
Micro-expressions (MEs) are crucial psychological responses with significant potential for affective computing. However, current automatic micro-expression recognition (MER) research primarily focuses on discrete emotion classification, neglecting a convincing analysis of the subtle dynamic movements and inherent emotional cues. The rapid progress in multimodal large language models (MLLMs), known for their strong multimodal comprehension and language generation abilities, offers new possibilities. MLLMs have shown success in various vision-language tasks, indicating their potential to understand MEs comprehensively, including both fine-grained motion patterns and underlying emotional semantics. Nevertheless, challenges remain due to the subtle intensity and short duration of MEs, as existing MLLMs are not designed to capture such delicate frame-level facial dynamics. In this paper, we propose a novel Micro-Expression Large Language Model (MELLM), which incorporates a subtle facial motion perception strategy with the strong inference capabilities of MLLMs, representing the first exploration of MLLMs in the domain of ME analysis. Specifically, to explicitly guide the MLLM toward motion-sensitive regions, we construct an interpretable motion-enhanced color map by fusing onset-apex optical flow dynamics with the corresponding grayscale onset frame as the model input. Additionally, specialized fine-tuning strategies are incorporated to further enhance the model's visual perception of MEs. Furthermore, we construct an instruction-description dataset based on Facial Action Coding System (FACS) annotations and emotion labels to train our MELLM. Comprehensive evaluations across multiple benchmark datasets demonstrate that our model exhibits superior robustness and generalization capabilities in ME understanding (MEU). Code is available at https://github.com/zyzhangUstc/MELLM.
A Challenger to GPT-4V? Early Explorations of Gemini in Visual Expertise
Dec 20, 2023



The surge of interest towards Multi-modal Large Language Models (MLLMs), e.g., GPT-4V(ision) from OpenAI, has marked a significant trend in both academia and industry. They endow Large Language Models (LLMs) with powerful capabilities in visual understanding, enabling them to tackle diverse multi-modal tasks. Very recently, Google released Gemini, its newest and most capable MLLM built from the ground up for multi-modality. In light of the superior reasoning capabilities, can Gemini challenge GPT-4V's leading position in multi-modal learning? In this paper, we present a preliminary exploration of Gemini Pro's visual understanding proficiency, which comprehensively covers four domains: fundamental perception, advanced cognition, challenging vision tasks, and various expert capacities. We compare Gemini Pro with the state-of-the-art GPT-4V to evaluate its upper limits, along with the latest open-sourced MLLM, Sphinx, which reveals the gap between manual efforts and black-box systems. The qualitative samples indicate that, while GPT-4V and Gemini showcase different answering styles and preferences, they can exhibit comparable visual reasoning capabilities, and Sphinx still trails behind them concerning domain generalizability. Specifically, GPT-4V tends to elaborate detailed explanations and intermediate steps, and Gemini prefers to output a direct and concise answer. The quantitative evaluation on the popular MME benchmark also demonstrates the potential of Gemini to be a strong challenger to GPT-4V. Our early investigation of Gemini also observes some common issues of MLLMs, indicating that there still remains a considerable distance towards artificial general intelligence. Our project for tracking the progress of MLLM is released at https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models.