 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIRDS: Interpretable RLVR Data Selection via Verifier-Coupled Sparse Autoencoder Coverage
May 27, 2026Reinforcement learning with verifiable rewards (RLVR) has become a key technique for en- hancing LLM reasoning, yet its data ineffi- ciency remains a major bottleneck. Existing methods address this problem only partially, each missing at least one of subset-level cov- erage, verifier signal use, or interpretability. To address this gap, we present IRDS (Inter- pretable RLVR Data Selection), which selects RLVR training instances on a sparse autoen- coder (SAE) cluster basis so the selection itself is auditable on recognizable problem motifs. To select instances the model both fails on and can still learn from, we introduce a verifier- coupled coverage objective on the SAE basis and solve it by greedy log-determinant max- imization. Experiments on three instruction- tuned models and six math reasoning bench- marks show that IRDS achieves the highest overall accuracy, exceeding the strongest base- line by +3.9/+4.0 pp on the two Qwen models and by +0.5 pp on Llama-3.1-8B, while run- ning an order of magnitude cheaper than the trajectory-based baseline.
SAE-FD: Sparse Autoencoder Feature Distillation for Continual Learning of Large Language Models
May 25, 2026Continual learning enables large language models to adapt to evolving tasks without retraining from scratch, yet catastrophic forgetting remains a central obstacle. Among continual learning methods, regularization-based approaches are widely used to constrain model updates and reduce forgetting, operating in weight space, gradient space, or output space. However, these dense representation spaces suffer from feature superposition, where multiple concepts are encoded in overlapping dimensions, making it difficult to selectively protect previously learned knowledge without impeding new-task learning. To address this issue, we propose \method (Sparse Autoencoder Feature Distillation), which anchors model representations in the sparse feature space of a pre-trained Sparse Autoencoder, where dense activations are decomposed into a sparse overcomplete basis that reduces representational entanglement, enabling more targeted regularization with less interference to new-task learning. Experiments on two continual learning benchmarks across three model architectures show that \method consistently outperforms existing regularization-based methods, achieving up to 52.70% average accuracy with only -0.46 backward transfer.
SLIM: Sparse Latent Steering for Interpretable and Property-Directed LLM-Based Molecular Editing
May 11, 2026Large language models possess strong chemical reasoning capabilities, making them effective molecular editors. However, property-relevant information is implicitly entangled across their dense hidden states, providing no explicit handle for property control: a substantial fraction of edits fail to improve or even degrade target properties. To address these issues, we propose SLIM (Sparse Latent Interpretable Molecular editing), a plug-and-play framework that decomposes the editor's hidden states into sparse, property-aligned features via a Sparse Autoencoder with learnable importance gates. Steering in this sparse feature space precisely activates property-relevant dimensions, improving editing success rate without modifying model parameters. The same sparse basis further supports interpretable analysis of editing behavior. Experiments on the MolEditRL benchmark across four model architectures and eight molecular properties show consistent gains over baselines, with improvements of up to 42.4 points.
Discrete Preference Learning for Personalized Multimodal Generation
Apr 22, 2026The emergence of generative models enables the creation of texts and images tailored to users' preferences. Existing personalized generative models have two critical limitations: lacking a dedicated paradigm for accurate preference modeling, and generating unimodal content despite real-world multimodal-driven user interactions. Therefore, we propose personalized multimodal generation, which captures modal-specific preferences via a dedicated preference model from multimodal interactions, and then feeds them into downstream generators for personalized multimodal content. However, this task presents two challenges: (1) Gap between continuous preferences from dedicated modeling and discrete token inputs intrinsic to generator architectures; (2) Potential inconsistency between generated images and texts. To tackle these, we present a two-stage framework called Discrete Preference learning for Personalized Multimodal Generation (DPPMG). In the first stage, to accurately learn discrete modal-specific preferences, we introduce a modal-specific graph neural network (a dedicated preference model) to learn users' modal-specific preferences, which preferences are then quantized into discrete preference tokens. In the second stage, the discrete modal-specific preference tokens are injected into downstream text and image generators. To further enhance cross-modal consistency while preserving personalization, we design a cross-modal consistent and personalized reward to fine-tune token-associated parameters. Extensive experiments on two real-world datasets demonstrate the effectiveness of our model in generating personalized and consistent multimodal content.
CoTZero: Annotation-Free Human-Like Vision Reasoning via Hierarchical Synthetic CoT
Feb 09, 2026Recent advances in vision-language models (VLMs) have markedly improved image-text alignment, yet they still fall short of human-like visual reasoning. A key limitation is that many VLMs rely on surface correlations rather than building logically coherent structured representations, which often leads to missed higher-level semantic structure and non-causal relational understanding, hindering compositional and verifiable reasoning. To address these limitations by introducing human models into the reasoning process, we propose CoTZero, an annotation-free paradigm with two components: (i) a dual-stage data synthesis approach and (ii) a cognition-aligned training method. In the first component, we draw inspiration from neurocognitive accounts of compositional productivity and global-to-local analysis. In the bottom-up stage, CoTZero extracts atomic visual primitives and incrementally composes them into diverse, structured question-reasoning forms. In the top-down stage, it enforces hierarchical reasoning by using coarse global structure to guide the interpretation of local details and causal relations. In the cognition-aligned training component, built on the synthesized CoT data, we introduce Cognitively Coherent Verifiable Rewards (CCVR) in Reinforcement Fine-Tuning (RFT) to further strengthen VLMs' hierarchical reasoning and generalization, providing stepwise feedback on reasoning coherence and factual correctness. Experiments show that CoTZero achieves an F1 score of 83.33 percent on our multi-level semantic inconsistency benchmark with lexical-perturbation negatives, across both in-domain and out-of-domain settings. Ablations confirm that each component contributes to more interpretable and human-aligned visual reasoning.
Rethinking Popularity Bias in Collaborative Filtering via Analytical Vector Decomposition
Dec 24, 2025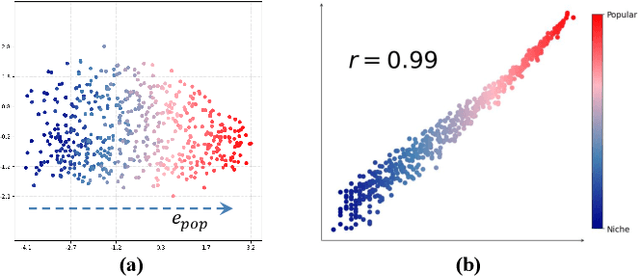
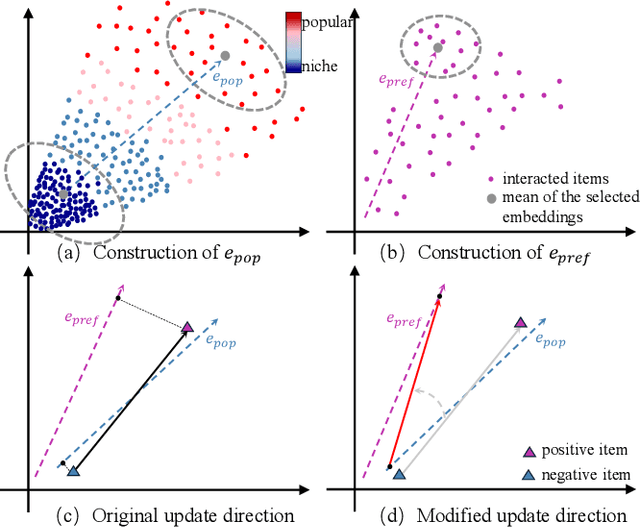
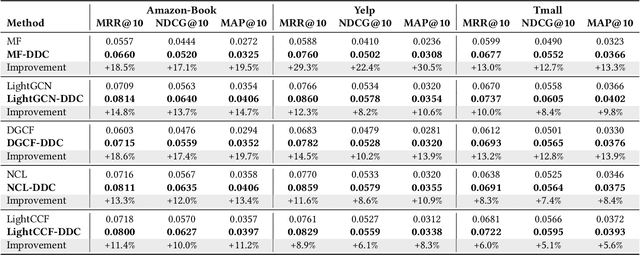
Popularity bias fundamentally undermines the personalization capabilities of collaborative filtering (CF) models, causing them to disproportionately recommend popular items while neglecting users' genuine preferences for niche content. While existing approaches treat this as an external confounding factor, we reveal that popularity bias is an intrinsic geometric artifact of Bayesian Pairwise Ranking (BPR) optimization in CF models. Through rigorous mathematical analysis, we prove that BPR systematically organizes item embeddings along a dominant "popularity direction" where embedding magnitudes directly correlate with interaction frequency. This geometric distortion forces user embeddings to simultaneously handle two conflicting tasks-expressing genuine preference and calibrating against global popularity-trapping them in suboptimal configurations that favor popular items regardless of individual tastes. We propose Directional Decomposition and Correction (DDC), a universally applicable framework that surgically corrects this embedding geometry through asymmetric directional updates. DDC guides positive interactions along personalized preference directions while steering negative interactions away from the global popularity direction, disentangling preference from popularity at the geometric source. Extensive experiments across multiple BPR-based architectures demonstrate that DDC significantly outperforms state-of-the-art debiasing methods, reducing training loss to less than 5% of heavily-tuned baselines while achieving superior recommendation quality and fairness. Code is available in https://github.com/LingFeng-Liu-AI/DDC.
ChemATP: A Training-Free Chemical Reasoning Framework for Large Language Models
Dec 22, 2025Large Language Models (LLMs) exhibit strong general reasoning but struggle in molecular science due to the lack of explicit chemical priors in standard string representations. Current solutions face a fundamental dilemma. Training-based methods inject priors into parameters, but this static coupling hinders rapid knowledge updates and often compromises the model's general reasoning capabilities. Conversely, existing training-free methods avoid these issues but rely on surface-level prompting, failing to provide the fine-grained atom-level priors essential for precise chemical reasoning. To address this issue, we introduce ChemATP, a framework that decouples chemical knowledge from the reasoning engine. By constructing the first atom-level textual knowledge base, ChemATP enables frozen LLMs to explicitly retrieve and reason over this information dynamically. This architecture ensures interpretability and adaptability while preserving the LLM's intrinsic general intelligence. Experiments show that ChemATP significantly outperforms training-free baselines and rivals state-of-the-art training-based models, demonstrating that explicit prior injection is a competitive alternative to implicit parameter updates.
Enhancing Conversational Recommender Systems with Tree-Structured Knowledge and Pretrained Language Models
Nov 16, 2025



Recent advances in pretrained language models (PLMs) have significantly improved conversational recommender systems (CRS), enabling more fluent and context-aware interactions. To further enhance accuracy and mitigate hallucination, many methods integrate PLMs with knowledge graphs (KGs), but face key challenges: failing to fully exploit PLM reasoning over graph relationships, indiscriminately incorporating retrieved knowledge without context filtering, and neglecting collaborative preferences in multi-turn dialogues. To this end, we propose PCRS-TKA, a prompt-based framework employing retrieval-augmented generation to integrate PLMs with KGs. PCRS-TKA constructs dialogue-specific knowledge trees from KGs and serializes them into texts, enabling structure-aware reasoning while capturing rich entity semantics. Our approach selectively filters context-relevant knowledge and explicitly models collaborative preferences using specialized supervision signals. A semantic alignment module harmonizes heterogeneous inputs, reducing noise and enhancing accuracy. Extensive experiments demonstrate that PCRS-TKA consistently outperforms all baselines in both recommendation and conversational quality.
NGTM: Substructure-based Neural Graph Topic Model for Interpretable Graph Generation
Jul 17, 2025Graph generation plays a pivotal role across numerous domains, including molecular design and knowledge graph construction. Although existing methods achieve considerable success in generating realistic graphs, their interpretability remains limited, often obscuring the rationale behind structural decisions. To address this challenge, we propose the Neural Graph Topic Model (NGTM), a novel generative framework inspired by topic modeling in natural language processing. NGTM represents graphs as mixtures of latent topics, each defining a distribution over semantically meaningful substructures, which facilitates explicit interpretability at both local and global scales. The generation process transparently integrates these topic distributions with a global structural variable, enabling clear semantic tracing of each generated graph. Experiments demonstrate that NGTM achieves competitive generation quality while uniquely enabling fine-grained control and interpretability, allowing users to tune structural features or induce biological properties through topic-level adjustments.
MolEditRL: Structure-Preserving Molecular Editing via Discrete Diffusion and Reinforcement Learning
May 26, 2025Molecular editing aims to modify a given molecule to optimize desired chemical properties while preserving structural similarity. However, current approaches typically rely on string-based or continuous representations, which fail to adequately capture the discrete, graph-structured nature of molecules, resulting in limited structural fidelity and poor controllability. In this paper, we propose MolEditRL, a molecular editing framework that explicitly integrates structural constraints with precise property optimization. Specifically, MolEditRL consists of two stages: (1) a discrete graph diffusion model pretrained to reconstruct target molecules conditioned on source structures and natural language instructions; (2) an editing-aware reinforcement learning fine-tuning stage that further enhances property alignment and structural preservation by explicitly optimizing editing decisions under graph constraints. For comprehensive evaluation, we construct MolEdit-Instruct, the largest and most property-rich molecular editing dataset, comprising 3 million diverse examples spanning single- and multi-property tasks across 10 chemical attributes. Experimental results demonstrate that MolEditRL significantly outperforms state-of-the-art methods in both property optimization accuracy and structural fidelity, achieving a 74\% improvement in editing success rate while using 98\% fewer parameters.