 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Semantic Token Selection and Prompt Optimization for Interpretable Prompt Learning
May 06, 2026Vision-language models such as CLIP achieve strong visual-textual alignment, but often suffer from overfitting and limited interpretability when adapted through continuous prompt learning. While discrete prompt optimization improves interpretability, it usually depends on large external models, leading to high computational costs and limited scalability. In this paper, we propose Interpretable Prompt Learning (IPL), a hybrid framework that alternates between discrete semantic token selection and continuous prompt optimization. Specifically, IPL formulates semantic token selection as an approximate submodular optimization problem, encouraging tokens that are both human-understandable and semantically diverse. It further adopts an alternating optimization strategy to integrate discrete token selection with continuous prompt tuning, improving interpretability while preserving adaptability to downstream tasks. Our framework is plug-and-play, allowing seamless integration with existing prompt learning methods. Extensive experiments on multiple benchmarks show that IPL consistently improves both interpretability and accuracy across five representative prompt learning methods, providing an effective and scalable extension to existing frameworks.
Distributed Multi-Layer Editing for Rule-Level Knowledge in Large Language Models
Apr 09, 2026Large language models store not only isolated facts but also rules that support reasoning across symbolic expressions, natural language explanations, and concrete instances. Yet most model editing methods are built for fact-level knowledge, assuming that a target edit can be achieved through a localized intervention. This assumption does not hold for rule-level knowledge, where a single rule must remain consistent across multiple interdependent forms. We investigate this problem through a mechanistic study of rule-level knowledge editing. To support this study, we extend the RuleEdit benchmark from 80 to 200 manually verified rules spanning mathematics and physics. Fine-grained causal tracing reveals a form-specific organization of rule knowledge in transformer layers: formulas and descriptions are concentrated in earlier layers, while instances are more associated with middle layers. These results suggest that rule knowledge is not uniformly localized, and therefore cannot be reliably edited by a single-layer or contiguous-block intervention. Based on this insight, we propose Distributed Multi-Layer Editing (DMLE), which applies a shared early-layer update to formulas and descriptions and a separate middle-layer update to instances. While remaining competitive on standard editing metrics, DMLE achieves substantially stronger rule-level editing performance. On average, it improves instance portability and rule understanding by 13.91 and 50.19 percentage points, respectively, over the strongest baseline across GPT-J-6B, Qwen2.5-7B, Qwen2-7B, and LLaMA-3-8B. The code is available at https://github.com/Pepper66/DMLE.
SCOT: Multi-Source Cross-City Transfer with Optimal-Transport Soft-Correspondence Objective
Apr 08, 2026Cross-city transfer improves prediction in label-scarce cities by leveraging labeled data from other cities, but it becomes challenging when cities adopt incompatible partitions and no ground-truth region correspondences exist. Existing approaches either rely on heuristic region matching, which is often sensitive to anchor choices, or perform distribution-level alignment that leaves correspondences implicit and can be unstable under strong heterogeneity. We propose SCOT, a cross-city representation learning framework that learns explicit soft correspondences between unequal region sets via Sinkhorn-based entropic optimal transport. SCOT further sharpens transferable structure with an OT-weighted contrastive objective and stabilizes optimization through a cycle-style reconstruction regularizer. For multi-source transfer, SCOT aligns each source and the target to a shared prototype hub using balanced entropic transport guided by a target-induced prototype prior. Across real-world cities and tasks, SCOT consistently improves transfer accuracy and robustness, while the learned transport couplings and hub assignments provide interpretable diagnostics of alignment quality.
Holistic Optimal Label Selection for Robust Prompt Learning under Partial Labels
Apr 08, 2026Prompt learning has gained significant attention as a parameter-efficient approach for adapting large pre-trained vision-language models to downstream tasks. However, when only partial labels are available, its performance is often limited by label ambiguity and insufficient supervisory information. To address this issue, we propose Holistic Optimal Label Selection (HopS), leveraging the generalization ability of pre-trained feature encoders through two complementary strategies. First, we design a local density-based filter that selects the top frequent labels from the nearest neighbors' candidate sets and uses the softmax scores to identify the most plausible label, capturing structural regularities in the feature space. Second, we introduce a global selection objective based on optimal transport that maps the uniform sampling distribution to the candidate label distributions across a batch. By minimizing the expected transport cost, it can determine the most likely label assignments. These two strategies work together to provide robust label selection from both local and global perspectives. Extensive experiments on eight benchmark datasets show that HopS consistently improves performance under partial supervision and outperforms all baselines. Those results highlight the merit of holistic label selection and offer a practical solution for prompt learning in weakly supervised settings.
EFF-Grasp: Energy-Field Flow Matching for Physics-Aware Dexterous Grasp Generation
Mar 17, 2026Denoising generative models have recently become the dominant paradigm for dexterous grasp generation, owing to their ability to model complex grasp distributions from large-scale data. However, existing diffusion-based methods typically formulate generation as a stochastic differential equation (SDE), which often requires many sequential denoising steps and introduces trajectory instability that can lead to physically infeasible grasps. In this paper, we propose EFF-Grasp, a novel Flow-Matching-based framework for physics-aware dexterous grasp generation. Specifically, we reformulate grasp synthesis as a deterministic ordinary differential equation (ODE) process, which enables efficient and stable generation through smooth probability flows. To further enforce physical feasibility, we introduce a training-free physics-aware energy guidance strategy. Our method defines an energy-guided target distribution using adapted explicit physical energy functions that capture key grasp constraints, and estimates the corresponding guidance term via a local Monte Carlo approximation during inference. In this way, EFF-Grasp dynamically steers the generation trajectory toward physically feasible regions without requiring additional physics-based training or simulation feedback. Extensive experiments on five benchmark datasets show that EFF-Grasp achieves superior performance in grasp quality and physical feasibility, while requiring substantially fewer sampling steps than diffusion-based baselines.
From Text to Forecasts: Bridging Modality Gap with Temporal Evolution Semantic Space
Mar 16, 2026Incorporating textual information into time-series forecasting holds promise for addressing event-driven non-stationarity; however, a fundamental modality gap hinders effective fusion: textual descriptions express temporal impacts implicitly and qualitatively, whereas forecasting models rely on explicit and quantitative signals. Through controlled semi-synthetic experiments, we show that existing methods over-attend to redundant tokens and struggle to reliably translate textual semantics into usable numerical cues. To bridge this gap, we propose TESS, which introduces a Temporal Evolution Semantic Space as an intermediate bottleneck between modalities. This space consists of interpretable, numerically grounded temporal primitives (mean shift, volatility, shape, and lag) extracted from text by an LLM via structured prompting and filtered through confidence-aware gating. Experiments on four real-world datasets demonstrate up to a 29 percent reduction in forecasting error compared to state-of-the-art unimodal and multimodal baselines. The code will be released after acceptance.
Riemannian MeanFlow for One-Step Generation on Manifolds
Mar 11, 2026Flow Matching enables simulation-free training of generative models on Riemannian manifolds, yet sampling typically still relies on numerically integrating a probability-flow ODE. We propose Riemannian MeanFlow (RMF), extending MeanFlow to manifold-valued generation where velocities lie in location-dependent tangent spaces. RMF defines an average-velocity field via parallel transport and derives a Riemannian MeanFlow identity that links average and instantaneous velocities for intrinsic supervision. We make this identity practical in a log-map tangent representation, avoiding trajectory simulation and heavy geometric computations. For stable optimization, we decompose the RMF objective into two terms and apply conflict-aware multi-task learning to mitigate gradient interference. RMF also supports conditional generation via classifier-free guidance. Experiments on spheres, tori, and SO(3) demonstrate competitive one-step sampling with improved quality-efficiency trade-offs and substantially reduced sampling cost.
What Papers Don't Tell You: Recovering Tacit Knowledge for Automated Paper Reproduction
Mar 02, 2026Automated paper reproduction -- generating executable code from academic papers -- is bottlenecked not by information retrieval but by the tacit knowledge that papers inevitably leave implicit. We formalize this challenge as the progressive recovery of three types of tacit knowledge -- relational, somatic, and collective -- and propose \method, a graph-based agent framework with a dedicated mechanism for each: node-level relation-aware aggregation recovers relational knowledge by analyzing implementation-unit-level reuse and adaptation relationships between the target paper and its citation neighbors; execution-feedback refinement recovers somatic knowledge through iterative debugging driven by runtime signals; and graph-level knowledge induction distills collective knowledge from clusters of papers sharing similar implementations. On an extended ReproduceBench spanning 3 domains, 10 tasks, and 40 recent papers, \method{} achieves an average performance gap of 10.04\% against official implementations, improving over the strongest baseline by 24.68\%. The code will be publicly released upon acceptance; the repository link will be provided in the final version.
Channel-Independent Federated Traffic Prediction
Aug 06, 2025

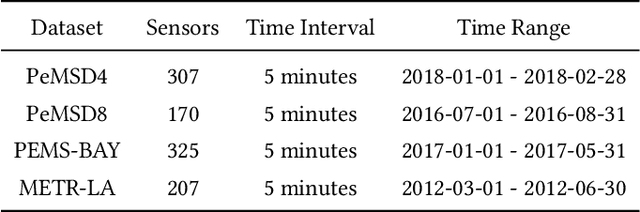

In recent years, traffic prediction has achieved remarkable success and has become an integral component of intelligent transportation systems. However, traffic data is typically distributed among multiple data owners, and privacy constraints prevent the direct utilization of these isolated datasets for traffic prediction. Most existing federated traffic prediction methods focus on designing communication mechanisms that allow models to leverage information from other clients in order to improve prediction accuracy. Unfortunately, such approaches often incur substantial communication overhead, and the resulting transmission delays significantly slow down the training process. As the volume of traffic data continues to grow, this issue becomes increasingly critical, making the resource consumption of current methods unsustainable. To address this challenge, we propose a novel variable relationship modeling paradigm for federated traffic prediction, termed the Channel-Independent Paradigm(CIP). Unlike traditional approaches, CIP eliminates the need for inter-client communication by enabling each node to perform efficient and accurate predictions using only local information. Based on the CIP, we further develop Fed-CI, an efficient federated learning framework, allowing each client to process its own data independently while effectively mitigating the information loss caused by the lack of direct data sharing among clients. Fed-CI significantly reduces communication overhead, accelerates the training process, and achieves state-of-the-art performance while complying with privacy regulations. Extensive experiments on multiple real-world datasets demonstrate that Fed-CI consistently outperforms existing methods across all datasets and federated settings. It achieves improvements of 8%, 14%, and 16% in RMSE, MAE, and MAPE, respectively, while also substantially reducing communication costs.
Self-Supervised and Generalizable Tokenization for CLIP-Based 3D Understanding
May 24, 2025



Vision-language models like CLIP can offer a promising foundation for 3D scene understanding when extended with 3D tokenizers. However, standard approaches, such as k-nearest neighbor or radius-based tokenization, struggle with cross-domain generalization due to sensitivity to dataset-specific spatial scales. We present a universal 3D tokenizer designed for scale-invariant representation learning with a frozen CLIP backbone. We show that combining superpoint-based grouping with coordinate scale normalization consistently outperforms conventional methods through extensive experimental analysis. Specifically, we introduce S4Token, a tokenization pipeline that produces semantically-informed tokens regardless of scene scale. Our tokenizer is trained without annotations using masked point modeling and clustering-based objectives, along with cross-modal distillation to align 3D tokens with 2D multi-view image features. For dense prediction tasks, we propose a superpoint-level feature propagation module to recover point-level detail from sparse tokens.