 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Journalist Agent: Transforming Data into Verifiable Multimodal Stories
Jun 09, 2026Data tells stories that shape society; the data journalist's job is to turn raw information into stories non-experts can trust. A high-quality news feature takes a newsroom team weeks: hunting for context, running statistics, choosing an angle, and designing visuals. Recent agents handle individual steps well: data-science agents close the analysis loop, while design agents synthesize beautiful websites. But can an agent serve as a data journalist end to end? We introduce Data Journalist Agent (Data2Story), a multi-agent framework that orchestrates specialized roles into a single virtual newsroom. Data2Story contributes two innovations. (i) Claims are evidence-grounded: an Inspector links every number, angle, and asset back to data, code, or an external reference. (ii) Articles are multimodally generative: rather than defaulting to plain text and static charts, Data2Story reasons about what readers will want to see, then deploys multimodal tools, such as interactive maps for geography and audio for music. We evaluate Data2Story on 18 articles, each paired with the originally published expert piece, along four axes: (a) human-agent angle coverage; (b) rubric evaluation with 53 participants across five dimensions; (c) computer-use agents as judges, a cost-saving proxy for how readers navigate interactive articles; and (d) verifiability, where a coding verifier re-executes statements against the data and checks claims against references. Data2Story produces competitive, evidence-traceable multimedia stories, with particular strength in transparency and auditability. Human articles retain an edge in editorial angle, creative design, and presentation. We position Data2Story as a collaborator for journalists, enabling more evidence-based, transparent, and verifiable reporting. Code and demos are available at https://data2story.github.io.
Agents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
Forecasting Scientific Progress with Artificial Intelligence
May 21, 2026Artificial intelligence (AI) is increasingly embedded in scientific discovery, yet whether it can anticipate scientific progress remains unclear. To study this question, we introduce a temporally grounded evaluation framework for forecasting scientific progress under controlled knowledge constraints. We present CUSP (Cutoff-conditioned Unseen Scientific Progress), a multi-disciplinary and event-level benchmark that evaluates scientific forecasting in AI systems through feasibility assessment, mechanistic reasoning, generative solution design, and temporal prediction. Across 4,760 scientific events, we observe systematic and domain-dependent limitations in current frontier models. While models can identify plausible research directions from competing candidates, they fail to reliably predict whether scientific advances will be realized and systematically misestimate when they will occur. Performance is highly heterogeneous across domains, with the timing of AI progress more predictable than advances in biology, chemistry, and physics. Performance is largely insensitive to whether events occur before or after the training cutoff, suggesting these limitations cannot be explained solely by knowledge exposure in training data. Under controlled information access, additional pre-cutoff knowledge improves performance but does not close the gap to full-information settings, which becomes more pronounced for high-citation advances. Models also exhibit systematic overconfidence and strong response biases, indicating unreliable uncertainty estimation. Taken together, current AI systems fall short as predictive tools for scientific progress. Access to prior knowledge does not translate into reliable forecasting, and performance benefits more from post-event information than from forward-looking prediction.
Code as Agent Harness
May 18, 2026Recent large language models (LLMs) have demonstrated strong capabilities in understanding and generating code, from competitive programming to repository-level software engineering. In emerging agentic systems, code is no longer only a target output. It increasingly serves as an operational substrate for agent reasoning, acting, environment modeling, and execution-based verification. We frame this shift through the lens of agent harnesses and introduce code as agent harness: a unified view that centers code as the basis for agent infrastructure. To systematically study this perspective, we organize the survey around three connected layers. First, we study the harness interface, where code connects agents to reasoning, action, and environment modeling. Second, we examine harness mechanisms: planning, memory, and tool use for long-horizon execution, together with feedback-driven control and optimization that make harness reliable and adaptive. Third, we discuss scaling the harness from single-agent systems to multi-agent settings, where shared code artifacts support multi-agent coordination, review, and verification. Across these layers, we summarize representative methods and practical applications of code as agent harness, spanning coding assistants, GUI/OS automation, embodied agents, scientific discovery, personalization and recommendation, DevOps, and enterprise workflows. We further outline open challenges for harness engineering, including evaluation beyond final task success, verification under incomplete feedback, regression-free harness improvement, consistent shared state across multiple agents, human oversight for safety-critical actions, and extensions to multimodal environments. By centering code as the harness of agentic AI, this survey provides a unified roadmap toward executable, verifiable, and stateful AI agent systems.
Recursive Multi-Agent Systems
Apr 28, 2026Recursive or looped language models have recently emerged as a new scaling axis by iteratively refining the same model computation over latent states to deepen reasoning. We extend such scaling principle from a single model to multi-agent systems, and ask: Can agent collaboration itself be scaled through recursion? To this end, we introduce RecursiveMAS, a recursive multi-agent framework that casts the entire system as a unified latent-space recursive computation. RecursiveMAS connects heterogeneous agents as a collaboration loop through the lightweight RecursiveLink module, enabling in-distribution latent thoughts generation and cross-agent latent state transfer. To optimize our framework, we develop an inner-outer loop learning algorithm for iterative whole-system co-optimization through shared gradient-based credit assignment across recursion rounds. Theoretical analyses of runtime complexity and learning dynamics establish that RecursiveMAS is more efficient than standard text-based MAS and maintains stable gradients during recursive training. Empirically, we instantiate RecursiveMAS under 4 representative agent collaboration patterns and evaluate across 9 benchmarks spanning mathematics, science, medicine, search, and code generation. In comparison with advanced single/multi-agent and recursive computation baselines, RecursiveMAS consistently delivers an average accuracy improvement of 8.3%, together with 1.2$\times$-2.4$\times$ end-to-end inference speedup, and 34.6%-75.6% token usage reduction. Code and Data are provided in https://recursivemas.github.io.
Estimating the Impact of COVID-19 on Travel Demand in Houston Area Using Deep Learning and Satellite Imagery
Mar 29, 2026Considering recent advances in remote sensing satellite systems and computer vision algorithms, many satellite sensing platforms and sensors have been used to monitor the condition and usage of transportation infrastructure systems. The level of details that can be detected increases significantly with the increase of ground sample distance (GSD), which is around 15 cm - 30 cm for high-resolution satellite images. In this study, we analyzed data acquired from high-resolution satellite imagery to provide insights, predictive signals, and trend for travel demand estimation. More specifically, we estimate the impact of COVID-19 in the metropolitan area of Houston using satellite imagery from Google Earth Engine datasets. We developed a car-counting model through Detectron2 and Faster R-CNN to monitor the presence of cars within different locations (i.e., university, shopping mall, community plaza, restaurant, supermarket) before and during the COVID-19. The results show that the number of cars detected at these selected locations reduced on average 30% in 2020 compared with the previous year 2019. The results also show that satellite imagery provides rich information for travel demand and economic activity estimation. Together with advanced computer vision and deep learning algorithms, it can generate reliable and accurate information for transportation agency decision makers.
iSight: Towards expert-AI co-assessment for improved immunohistochemistry staining interpretation
Feb 03, 2026Immunohistochemistry (IHC) provides information on protein expression in tissue sections and is commonly used to support pathology diagnosis and disease triage. While AI models for H\&E-stained slides show promise, their applicability to IHC is limited due to domain-specific variations. Here we introduce HPA10M, a dataset that contains 10,495,672 IHC images from the Human Protein Atlas with comprehensive metadata included, and encompasses 45 normal tissue types and 20 major cancer types. Based on HPA10M, we trained iSight, a multi-task learning framework for automated IHC staining assessment. iSight combines visual features from whole-slide images with tissue metadata through a token-level attention mechanism, simultaneously predicting staining intensity, location, quantity, tissue type, and malignancy status. On held-out data, iSight achieved 85.5\% accuracy for location, 76.6\% for intensity, and 75.7\% for quantity, outperforming fine-tuned foundation models (PLIP, CONCH) by 2.5--10.2\%. In addition, iSight demonstrates well-calibrated predictions with expected calibration errors of 0.0150-0.0408. Furthermore, in a user study with eight pathologists evaluating 200 images from two datasets, iSight outperformed initial pathologist assessments on the held-out HPA dataset (79\% vs 68\% for location, 70\% vs 57\% for intensity, 68\% vs 52\% for quantity). Inter-pathologist agreement also improved after AI assistance in both held-out HPA (Cohen's $κ$ increased from 0.63 to 0.70) and Stanford TMAD datasets (from 0.74 to 0.76), suggesting expert--AI co-assessment can improve IHC interpretation. This work establishes a foundation for AI systems that can improve IHC diagnostic accuracy and highlights the potential for integrating iSight into clinical workflows to enhance the consistency and reliability of IHC assessment.
Adaptation of Agentic AI
Dec 22, 2025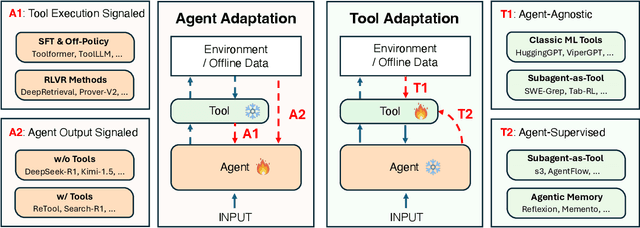
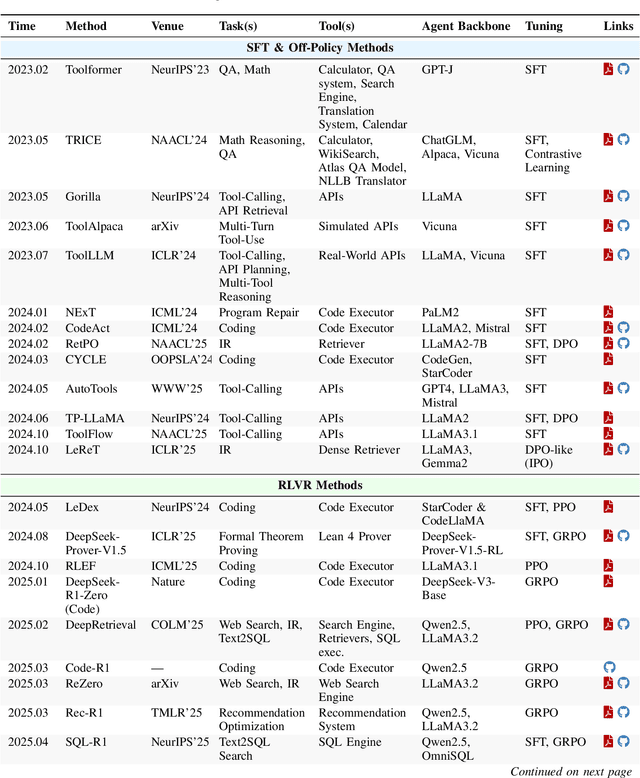
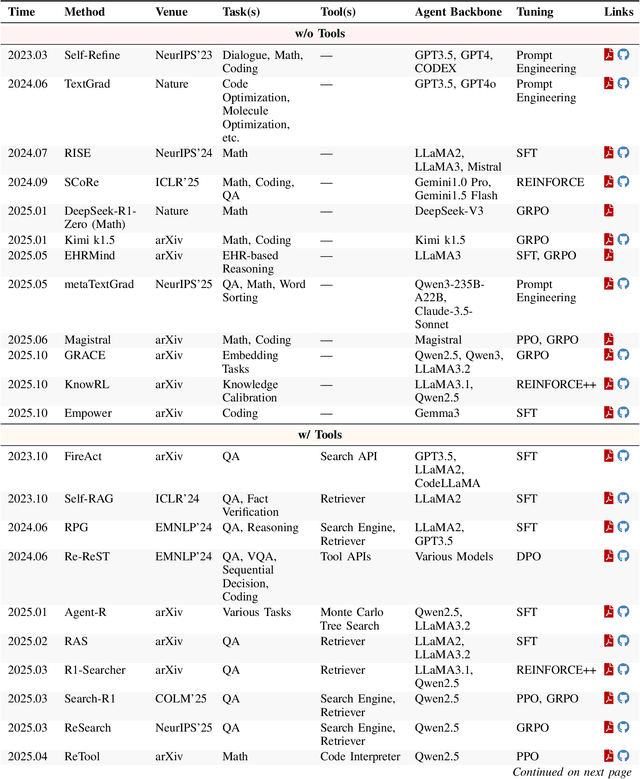
Cutting-edge agentic AI systems are built on foundation models that can be adapted to plan, reason, and interact with external tools to perform increasingly complex and specialized tasks. As these systems grow in capability and scope, adaptation becomes a central mechanism for improving performance, reliability, and generalization. In this paper, we unify the rapidly expanding research landscape into a systematic framework that spans both agent adaptations and tool adaptations. We further decompose these into tool-execution-signaled and agent-output-signaled forms of agent adaptation, as well as agent-agnostic and agent-supervised forms of tool adaptation. We demonstrate that this framework helps clarify the design space of adaptation strategies in agentic AI, makes their trade-offs explicit, and provides practical guidance for selecting or switching among strategies during system design. We then review the representative approaches in each category, analyze their strengths and limitations, and highlight key open challenges and future opportunities. Overall, this paper aims to offer a conceptual foundation and practical roadmap for researchers and practitioners seeking to build more capable, efficient, and reliable agentic AI systems.
Learning Human-Perceived Fakeness in AI-Generated Videos via Multimodal LLMs
Sep 26, 2025Can humans identify AI-generated (fake) videos and provide grounded reasons? While video generation models have advanced rapidly, a critical dimension -- whether humans can detect deepfake traces within a generated video, i.e., spatiotemporal grounded visual artifacts that reveal a video as machine generated -- has been largely overlooked. We introduce DeeptraceReward, the first fine-grained, spatially- and temporally- aware benchmark that annotates human-perceived fake traces for video generation reward. The dataset comprises 4.3K detailed annotations across 3.3K high-quality generated videos. Each annotation provides a natural-language explanation, pinpoints a bounding-box region containing the perceived trace, and marks precise onset and offset timestamps. We consolidate these annotations into 9 major categories of deepfake traces that lead humans to identify a video as AI-generated, and train multimodal language models (LMs) as reward models to mimic human judgments and localizations. On DeeptraceReward, our 7B reward model outperforms GPT-5 by 34.7% on average across fake clue identification, grounding, and explanation. Interestingly, we observe a consistent difficulty gradient: binary fake v.s. real classification is substantially easier than fine-grained deepfake trace detection; within the latter, performance degrades from natural language explanations (easiest), to spatial grounding, to temporal labeling (hardest). By foregrounding human-perceived deepfake traces, DeeptraceReward provides a rigorous testbed and training signal for socially aware and trustworthy video generation.
Solving Inequality Proofs with Large Language Models
Jun 09, 2025Inequality proving, crucial across diverse scientific and mathematical fields, tests advanced reasoning skills such as discovering tight bounds and strategic theorem application. This makes it a distinct, demanding frontier for large language models (LLMs), offering insights beyond general mathematical problem-solving. Progress in this area is hampered by existing datasets that are often scarce, synthetic, or rigidly formal. We address this by proposing an informal yet verifiable task formulation, recasting inequality proving into two automatically checkable subtasks: bound estimation and relation prediction. Building on this, we release IneqMath, an expert-curated dataset of Olympiad-level inequalities, including a test set and training corpus enriched with step-wise solutions and theorem annotations. We also develop a novel LLM-as-judge evaluation framework, combining a final-answer judge with four step-wise judges designed to detect common reasoning flaws. A systematic evaluation of 29 leading LLMs on IneqMath reveals a surprising reality: even top models like o1 achieve less than 10% overall accuracy under step-wise scrutiny; this is a drop of up to 65.5% from their accuracy considering only final answer equivalence. This discrepancy exposes fragile deductive chains and a critical gap for current LLMs between merely finding an answer and constructing a rigorous proof. Scaling model size and increasing test-time computation yield limited gains in overall proof correctness. Instead, our findings highlight promising research directions such as theorem-guided reasoning and self-refinement. Code and data are available at https://ineqmath.github.io/.