 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboVerse: Towards a Unified Platform, Dataset and Benchmark for Scalable and Generalizable Robot Learning
Apr 26, 2025



Data scaling and standardized evaluation benchmarks have driven significant advances in natural language processing and computer vision. However, robotics faces unique challenges in scaling data and establishing evaluation protocols. Collecting real-world data is resource-intensive and inefficient, while benchmarking in real-world scenarios remains highly complex. Synthetic data and simulation offer promising alternatives, yet existing efforts often fall short in data quality, diversity, and benchmark standardization. To address these challenges, we introduce RoboVerse, a comprehensive framework comprising a simulation platform, a synthetic dataset, and unified benchmarks. Our simulation platform supports multiple simulators and robotic embodiments, enabling seamless transitions between different environments. The synthetic dataset, featuring high-fidelity physics and photorealistic rendering, is constructed through multiple approaches. Additionally, we propose unified benchmarks for imitation learning and reinforcement learning, enabling evaluation across different levels of generalization. At the core of the simulation platform is MetaSim, an infrastructure that abstracts diverse simulation environments into a universal interface. It restructures existing simulation environments into a simulator-agnostic configuration system, as well as an API aligning different simulator functionalities, such as launching simulation environments, loading assets with initial states, stepping the physics engine, etc. This abstraction ensures interoperability and extensibility. Comprehensive experiments demonstrate that RoboVerse enhances the performance of imitation learning, reinforcement learning, world model learning, and sim-to-real transfer. These results validate the reliability of our dataset and benchmarks, establishing RoboVerse as a robust solution for advancing robot learning.
Robo-GS: A Physics Consistent Spatial-Temporal Model for Robotic Arm with Hybrid Representation
Aug 27, 2024Real2Sim2Real plays a critical role in robotic arm control and reinforcement learning, yet bridging this gap remains a significant challenge due to the complex physical properties of robots and the objects they manipulate. Existing methods lack a comprehensive solution to accurately reconstruct real-world objects with spatial representations and their associated physics attributes. We propose a Real2Sim pipeline with a hybrid representation model that integrates mesh geometry, 3D Gaussian kernels, and physics attributes to enhance the digital asset representation of robotic arms. This hybrid representation is implemented through a Gaussian-Mesh-Pixel binding technique, which establishes an isomorphic mapping between mesh vertices and Gaussian models. This enables a fully differentiable rendering pipeline that can be optimized through numerical solvers, achieves high-fidelity rendering via Gaussian Splatting, and facilitates physically plausible simulation of the robotic arm's interaction with its environment using mesh-based methods. The code,full presentation and datasets will be made publicly available at our website https://robostudioapp.com
UniDoorManip: Learning Universal Door Manipulation Policy Over Large-scale and Diverse Door Manipulation Environments
Mar 12, 2024Learning a universal manipulation policy encompassing doors with diverse categories, geometries and mechanisms, is crucial for future embodied agents to effectively work in complex and broad real-world scenarios. Due to the limited datasets and unrealistic simulation environments, previous works fail to achieve good performance across various doors. In this work, we build a novel door manipulation environment reflecting different realistic door manipulation mechanisms, and further equip this environment with a large-scale door dataset covering 6 door categories with hundreds of door bodies and handles, making up thousands of different door instances. Additionally, to better emulate real-world scenarios, we introduce a mobile robot as the agent and use the partial and occluded point cloud as the observation, which are not considered in previous works while possessing significance for real-world implementations. To learn a universal policy over diverse doors, we propose a novel framework disentangling the whole manipulation process into three stages, and integrating them by training in the reversed order of inference. Extensive experiments validate the effectiveness of our designs and demonstrate our framework's strong performance. Code, data and videos are avaible on https://unidoormanip.github.io/.
ManipLLM: Embodied Multimodal Large Language Model for Object-Centric Robotic Manipulation
Dec 24, 2023



Robot manipulation relies on accurately predicting contact points and end-effector directions to ensure successful operation. However, learning-based robot manipulation, trained on a limited category within a simulator, often struggles to achieve generalizability, especially when confronted with extensive categories. Therefore, we introduce an innovative approach for robot manipulation that leverages the robust reasoning capabilities of Multimodal Large Language Models (MLLMs) to enhance the stability and generalization of manipulation. By fine-tuning the injected adapters, we preserve the inherent common sense and reasoning ability of the MLLMs while equipping them with the ability for manipulation. The fundamental insight lies in the introduced fine-tuning paradigm, encompassing object category understanding, affordance prior reasoning, and object-centric pose prediction to stimulate the reasoning ability of MLLM in manipulation. During inference, our approach utilizes an RGB image and text prompt to predict the end effector's pose in chain of thoughts. After the initial contact is established, an active impedance adaptation policy is introduced to plan the upcoming waypoints in a closed-loop manner. Moreover, in real world, we design a test-time adaptation (TTA) strategy for manipulation to enable the model better adapt to the current real-world scene configuration. Experiments in simulator and real-world show the promising performance of ManipLLM. More details and demonstrations can be found at https://sites.google.com/view/manipllm.
Grasp Multiple Objects with One Hand
Oct 24, 2023



The human hand's complex kinematics allow for simultaneous grasping and manipulation of multiple objects, essential for tasks like object transfer and in-hand manipulation. Despite its importance, robotic multi-object grasping remains underexplored and presents challenges in kinematics, dynamics, and object configurations. This paper introduces MultiGrasp, a two-stage method for multi-object grasping on a tabletop with a multi-finger dexterous hand. It involves (i) generating pre-grasp proposals and (ii) executing the grasp and lifting the objects. Experimental results primarily focus on dual-object grasping and report a 44.13% success rate, showcasing adaptability to unseen object configurations and imprecise grasps. The framework also demonstrates the capability to grasp more than two objects, albeit at a reduced inference speed.
Safety-Gymnasium: A Unified Safe Reinforcement Learning Benchmark
Oct 19, 2023



Artificial intelligence (AI) systems possess significant potential to drive societal progress. However, their deployment often faces obstacles due to substantial safety concerns. Safe reinforcement learning (SafeRL) emerges as a solution to optimize policies while simultaneously adhering to multiple constraints, thereby addressing the challenge of integrating reinforcement learning in safety-critical scenarios. In this paper, we present an environment suite called Safety-Gymnasium, which encompasses safety-critical tasks in both single and multi-agent scenarios, accepting vector and vision-only input. Additionally, we offer a library of algorithms named Safe Policy Optimization (SafePO), comprising 16 state-of-the-art SafeRL algorithms. This comprehensive library can serve as a validation tool for the research community. By introducing this benchmark, we aim to facilitate the evaluation and comparison of safety performance, thus fostering the development of reinforcement learning for safer, more reliable, and responsible real-world applications. The website of this project can be accessed at https://sites.google.com/view/safety-gymnasium.
RGBManip: Monocular Image-based Robotic Manipulation through Active Object Pose Estimation
Oct 05, 2023



Robotic manipulation requires accurate perception of the environment, which poses a significant challenge due to its inherent complexity and constantly changing nature. In this context, RGB image and point-cloud observations are two commonly used modalities in visual-based robotic manipulation, but each of these modalities have their own limitations. Commercial point-cloud observations often suffer from issues like sparse sampling and noisy output due to the limits of the emission-reception imaging principle. On the other hand, RGB images, while rich in texture information, lack essential depth and 3D information crucial for robotic manipulation. To mitigate these challenges, we propose an image-only robotic manipulation framework that leverages an eye-on-hand monocular camera installed on the robot's parallel gripper. By moving with the robot gripper, this camera gains the ability to actively perceive object from multiple perspectives during the manipulation process. This enables the estimation of 6D object poses, which can be utilized for manipulation. While, obtaining images from more and diverse viewpoints typically improves pose estimation, it also increases the manipulation time. To address this trade-off, we employ a reinforcement learning policy to synchronize the manipulation strategy with active perception, achieving a balance between 6D pose accuracy and manipulation efficiency. Our experimental results in both simulated and real-world environments showcase the state-of-the-art effectiveness of our approach. %, which, to the best of our knowledge, is the first to achieve robust real-world robotic manipulation through active pose estimation. We believe that our method will inspire further research on real-world-oriented robotic manipulation.
OmniSafe: An Infrastructure for Accelerating Safe Reinforcement Learning Research
May 16, 2023



AI systems empowered by reinforcement learning (RL) algorithms harbor the immense potential to catalyze societal advancement, yet their deployment is often impeded by significant safety concerns. Particularly in safety-critical applications, researchers have raised concerns about unintended harms or unsafe behaviors of unaligned RL agents. The philosophy of safe reinforcement learning (SafeRL) is to align RL agents with harmless intentions and safe behavioral patterns. In SafeRL, agents learn to develop optimal policies by receiving feedback from the environment, while also fulfilling the requirement of minimizing the risk of unintended harm or unsafe behavior. However, due to the intricate nature of SafeRL algorithm implementation, combining methodologies across various domains presents a formidable challenge. This had led to an absence of a cohesive and efficacious learning framework within the contemporary SafeRL research milieu. In this work, we introduce a foundational framework designed to expedite SafeRL research endeavors. Our comprehensive framework encompasses an array of algorithms spanning different RL domains and places heavy emphasis on safety elements. Our efforts are to make the SafeRL-related research process more streamlined and efficient, therefore facilitating further research in AI safety. Our project is released at: https://github.com/PKU-Alignment/omnisafe.
PartManip: Learning Cross-Category Generalizable Part Manipulation Policy from Point Cloud Observations
Mar 29, 2023



Learning a generalizable object manipulation policy is vital for an embodied agent to work in complex real-world scenes. Parts, as the shared components in different object categories, have the potential to increase the generalization ability of the manipulation policy and achieve cross-category object manipulation. In this work, we build the first large-scale, part-based cross-category object manipulation benchmark, PartManip, which is composed of 11 object categories, 494 objects, and 1432 tasks in 6 task classes. Compared to previous work, our benchmark is also more diverse and realistic, i.e., having more objects and using sparse-view point cloud as input without oracle information like part segmentation. To tackle the difficulties of vision-based policy learning, we first train a state-based expert with our proposed part-based canonicalization and part-aware rewards, and then distill the knowledge to a vision-based student. We also find an expressive backbone is essential to overcome the large diversity of different objects. For cross-category generalization, we introduce domain adversarial learning for domain-invariant feature extraction. Extensive experiments in simulation show that our learned policy can outperform other methods by a large margin, especially on unseen object categories. We also demonstrate our method can successfully manipulate novel objects in the real world.
GraspNeRF: Multiview-based 6-DoF Grasp Detection for Transparent and Specular Objects Using Generalizable NeRF
Oct 12, 2022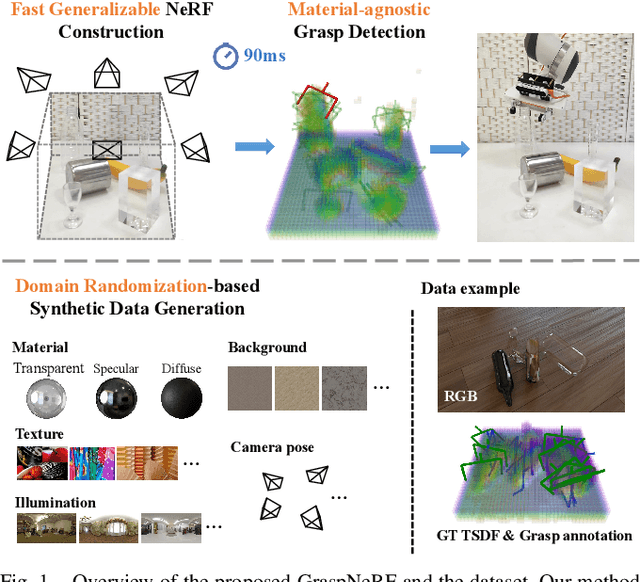
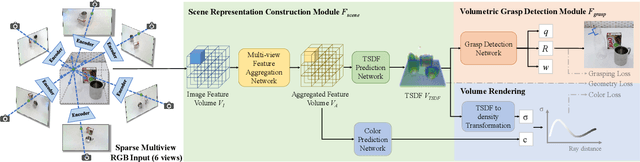
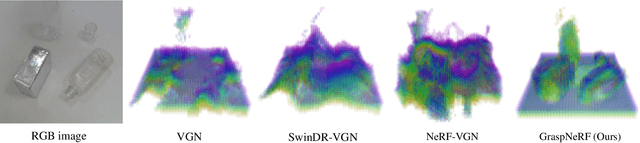
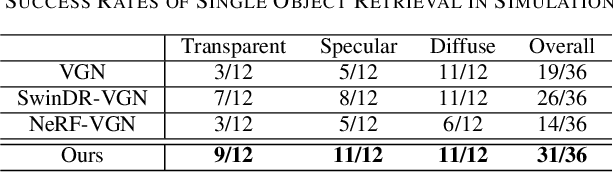
In this work, we tackle 6-DoF grasp detection for transparent and specular objects, which is an important yet challenging problem in vision-based robotic systems, due to the failure of depth cameras in sensing their geometry. We, for the first time, propose a multiview RGB-based 6-DoF grasp detection network, GraspNeRF, that leverages the generalizable neural radiance field (NeRF) to achieve material-agnostic object grasping in clutter. Compared to the existing NeRF-based 3-DoF grasp detection methods that rely on densely captured input images and time-consuming per-scene optimization, our system can perform zero-shot NeRF construction with sparse RGB inputs and reliably detect 6-DoF grasps, both in real-time. The proposed framework jointly learns generalizable NeRF and grasp detection in an end-to-end manner, optimizing the scene representation construction for the grasping. For training data, we generate a large-scale photorealistic domain-randomized synthetic dataset of grasping in cluttered tabletop scenes that enables direct transfer to the real world. Our extensive experiments in synthetic and real-world environments demonstrate that our method significantly outperforms all the baselines in all the experiments while remaining in real-time.