 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundIR-v2: Optimizing Pre-Training Data Mixtures for Image Restoration Foundation Model
Dec 10, 2025



Recent studies have witnessed significant advances in image restoration foundation models driven by improvements in the scale and quality of pre-training data. In this work, we find that the data mixture proportions from different restoration tasks are also a critical factor directly determining the overall performance of all-in-one image restoration models. To this end, we propose a high-capacity diffusion-based image restoration foundation model, FoundIR-v2, which adopts a data equilibrium scheduling paradigm to dynamically optimize the proportions of mixed training datasets from different tasks. By leveraging the data mixing law, our method ensures a balanced dataset composition, enabling the model to achieve consistent generalization and comprehensive performance across diverse tasks. Furthermore, we introduce an effective Mixture-of-Experts (MoE)-driven scheduler into generative pre-training to flexibly allocate task-adaptive diffusion priors for each restoration task, accounting for the distinct degradation forms and levels exhibited by different tasks. Extensive experiments demonstrate that our method can address over 50 sub-tasks across a broader scope of real-world scenarios and achieves favorable performance against state-of-the-art approaches.
Generative Point Cloud Registration
Dec 10, 2025In this paper, we propose a novel 3D registration paradigm, Generative Point Cloud Registration, which bridges advanced 2D generative models with 3D matching tasks to enhance registration performance. Our key idea is to generate cross-view consistent image pairs that are well-aligned with the source and target point clouds, enabling geometry-color feature fusion to facilitate robust matching. To ensure high-quality matching, the generated image pair should feature both 2D-3D geometric consistency and cross-view texture consistency. To achieve this, we introduce Match-ControlNet, a matching-specific, controllable 2D generative model. Specifically, it leverages the depth-conditioned generation capability of ControlNet to produce images that are geometrically aligned with depth maps derived from point clouds, ensuring 2D-3D geometric consistency. Additionally, by incorporating a coupled conditional denoising scheme and coupled prompt guidance, Match-ControlNet further promotes cross-view feature interaction, guiding texture consistency generation. Our generative 3D registration paradigm is general and could be seamlessly integrated into various registration methods to enhance their performance. Extensive experiments on 3DMatch and ScanNet datasets verify the effectiveness of our approach.
FUSER: Feed-Forward MUltiview 3D Registration Transformer and SE(3)$^N$ Diffusion Refinement
Dec 10, 2025Registration of multiview point clouds conventionally relies on extensive pairwise matching to build a pose graph for global synchronization, which is computationally expensive and inherently ill-posed without holistic geometric constraints. This paper proposes FUSER, the first feed-forward multiview registration transformer that jointly processes all scans in a unified, compact latent space to directly predict global poses without any pairwise estimation. To maintain tractability, FUSER encodes each scan into low-resolution superpoint features via a sparse 3D CNN that preserves absolute translation cues, and performs efficient intra- and inter-scan reasoning through a Geometric Alternating Attention module. Particularly, we transfer 2D attention priors from off-the-shelf foundation models to enhance 3D feature interaction and geometric consistency. Building upon FUSER, we further introduce FUSER-DF, an SE(3)$^N$ diffusion refinement framework to correct FUSER's estimates via denoising in the joint SE(3)$^N$ space. FUSER acts as a surrogate multiview registration model to construct the denoiser, and a prior-conditioned SE(3)$^N$ variational lower bound is derived for denoising supervision. Extensive experiments on 3DMatch, ScanNet and ArkitScenes demonstrate that our approach achieves the superior registration accuracy and outstanding computational efficiency.
From Parameter to Representation: A Closed-Form Approach for Controllable Model Merging
Nov 14, 2025



Model merging combines expert models for multitask performance but faces challenges from parameter interference. This has sparked recent interest in controllable model merging, giving users the ability to explicitly balance performance trade-offs. Existing approaches employ a compile-then-query paradigm, performing a costly offline multi-objective optimization to enable fast, preference-aware model generation. This offline stage typically involves iterative search or dedicated training, with complexity that grows exponentially with the number of tasks. To overcome these limitations, we shift the perspective from parameter-space optimization to a direct correction of the model's final representation. Our approach models this correction as an optimal linear transformation, yielding a closed-form solution that replaces the entire offline optimization process with a single-step, architecture-agnostic computation. This solution directly incorporates user preferences, allowing a Pareto-optimal model to be generated on-the-fly with complexity that scales linearly with the number of tasks. Experimental results show our method generates a superior Pareto front with more precise preference alignment and drastically reduced computational cost.
MVU-Eval: Towards Multi-Video Understanding Evaluation for Multimodal LLMs
Nov 13, 2025



The advent of Multimodal Large Language Models (MLLMs) has expanded AI capabilities to visual modalities, yet existing evaluation benchmarks remain limited to single-video understanding, overlooking the critical need for multi-video understanding in real-world scenarios (e.g., sports analytics and autonomous driving). To address this significant gap, we introduce MVU-Eval, the first comprehensive benchmark for evaluating Multi-Video Understanding for MLLMs. Specifically, our MVU-Eval mainly assesses eight core competencies through 1,824 meticulously curated question-answer pairs spanning 4,959 videos from diverse domains, addressing both fundamental perception tasks and high-order reasoning tasks. These capabilities are rigorously aligned with real-world applications such as multi-sensor synthesis in autonomous systems and cross-angle sports analytics. Through extensive evaluation of state-of-the-art open-source and closed-source models, we reveal significant performance discrepancies and limitations in current MLLMs' ability to perform understanding across multiple videos. The benchmark will be made publicly available to foster future research.
Scale-Aware Relay and Scale-Adaptive Loss for Tiny Object Detection in Aerial Images
Nov 13, 2025



Recently, despite the remarkable advancements in object detection, modern detectors still struggle to detect tiny objects in aerial images. One key reason is that tiny objects carry limited features that are inevitably degraded or lost during long-distance network propagation. Another is that smaller objects receive disproportionately greater regression penalties than larger ones during training. To tackle these issues, we propose a Scale-Aware Relay Layer (SARL) and a Scale-Adaptive Loss (SAL) for tiny object detection, both of which are seamlessly compatible with the top-performing frameworks. Specifically, SARL employs a cross-scale spatial-channel attention to progressively enrich the meaningful features of each layer and strengthen the cross-layer feature sharing. SAL reshapes the vanilla IoU-based losses so as to dynamically assign lower weights to larger objects. This loss is able to focus training on tiny objects while reducing the influence on large objects. Extensive experiments are conducted on three benchmarks (\textit{i.e.,} AI-TOD, DOTA-v2.0 and VisDrone2019), and the results demonstrate that the proposed method boosts the generalization ability by 5.5\% Average Precision (AP) when embedded in YOLOv5 (anchor-based) and YOLOx (anchor-free) baselines. Moreover, it also promotes the robust performance with 29.0\% AP on the real-world noisy dataset (\textit{i.e.,} AI-TOD-v2.0).
Beyond Randomness: Understand the Order of the Noise in Diffusion
Nov 11, 2025
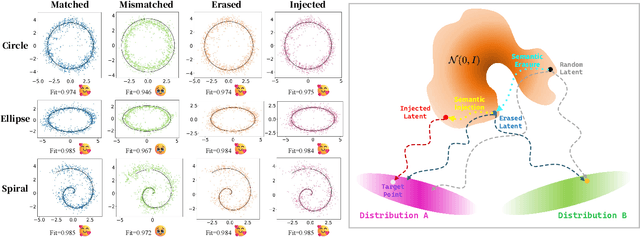


In text-driven content generation (T2C) diffusion model, semantic of generated content is mostly attributed to the process of text embedding and attention mechanism interaction. The initial noise of the generation process is typically characterized as a random element that contributes to the diversity of the generated content. Contrary to this view, this paper reveals that beneath the random surface of noise lies strong analyzable patterns. Specifically, this paper first conducts a comprehensive analysis of the impact of random noise on the model's generation. We found that noise not only contains rich semantic information, but also allows for the erasure of unwanted semantics from it in an extremely simple way based on information theory, and using the equivalence between the generation process of diffusion model and semantic injection to inject semantics into the cleaned noise. Then, we mathematically decipher these observations and propose a simple but efficient training-free and universal two-step "Semantic Erasure-Injection" process to modulate the initial noise in T2C diffusion model. Experimental results demonstrate that our method is consistently effective across various T2C models based on both DiT and UNet architectures and presents a novel perspective for optimizing the generation of diffusion model, providing a universal tool for consistent generation.
FreeControl: Efficient, Training-Free Structural Control via One-Step Attention Extraction
Nov 07, 2025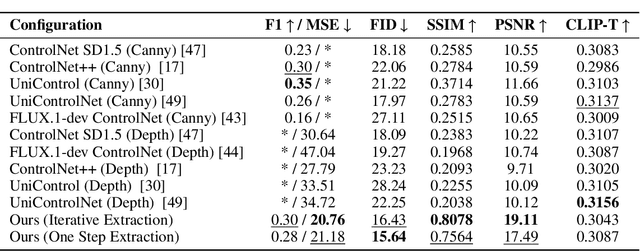
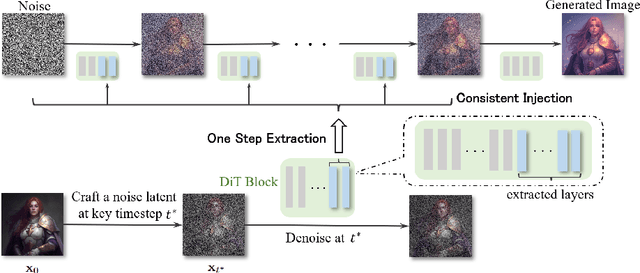
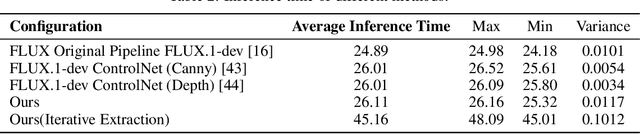

Controlling the spatial and semantic structure of diffusion-generated images remains a challenge. Existing methods like ControlNet rely on handcrafted condition maps and retraining, limiting flexibility and generalization. Inversion-based approaches offer stronger alignment but incur high inference cost due to dual-path denoising. We present FreeControl, a training-free framework for semantic structural control in diffusion models. Unlike prior methods that extract attention across multiple timesteps, FreeControl performs one-step attention extraction from a single, optimally chosen key timestep and reuses it throughout denoising. This enables efficient structural guidance without inversion or retraining. To further improve quality and stability, we introduce Latent-Condition Decoupling (LCD): a principled separation of the key timestep and the noised latent used in attention extraction. LCD provides finer control over attention quality and eliminates structural artifacts. FreeControl also supports compositional control via reference images assembled from multiple sources - enabling intuitive scene layout design and stronger prompt alignment. FreeControl introduces a new paradigm for test-time control, enabling structurally and semantically aligned, visually coherent generation directly from raw images, with the flexibility for intuitive compositional design and compatibility with modern diffusion models at approximately 5 percent additional cost.
Scaling Latent Reasoning via Looped Language Models
Oct 29, 2025



Modern LLMs are trained to "think" primarily via explicit text generation, such as chain-of-thought (CoT), which defers reasoning to post-training and under-leverages pre-training data. We present and open-source Ouro, named after the recursive Ouroboros, a family of pre-trained Looped Language Models (LoopLM) that instead build reasoning into the pre-training phase through (i) iterative computation in latent space, (ii) an entropy-regularized objective for learned depth allocation, and (iii) scaling to 7.7T tokens. Ouro 1.4B and 2.6B models enjoy superior performance that match the results of up to 12B SOTA LLMs across a wide range of benchmarks. Through controlled experiments, we show this advantage stems not from increased knowledge capacity, but from superior knowledge manipulation capabilities. We also show that LoopLM yields reasoning traces more aligned with final outputs than explicit CoT. We hope our results show the potential of LoopLM as a novel scaling direction in the reasoning era. Our model could be found in: http://ouro-llm.github.io.
Restore Text First, Enhance Image Later: Two-Stage Scene Text Image Super-Resolution with Glyph Structure Guidance
Oct 24, 2025



Current generative super-resolution methods show strong performance on natural images but distort text, creating a fundamental trade-off between image quality and textual readability. To address this, we introduce \textbf{TIGER} (\textbf{T}ext-\textbf{I}mage \textbf{G}uided sup\textbf{E}r-\textbf{R}esolution), a novel two-stage framework that breaks this trade-off through a \textit{"text-first, image-later"} paradigm. \textbf{TIGER} explicitly decouples glyph restoration from image enhancement: it first reconstructs precise text structures and then uses them to guide subsequent full-image super-resolution. This glyph-to-image guidance ensures both high fidelity and visual consistency. To support comprehensive training and evaluation, we also contribute the \textbf{UltraZoom-ST} (UltraZoom-Scene Text), the first scene text dataset with extreme zoom (\textbf{$\times$14.29}). Extensive experiments show that \textbf{TIGER} achieves \textbf{state-of-the-art} performance, enhancing readability while preserving overall image quality.