 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Consistent Generative Paths via Admissible Random Variational Transport
Jun 08, 2026Modern generative models often define an entire probability path from a simple prior to the data law, rather than only an endpoint map. Diffusion models follow stochastic denoising paths, flow matching learns transport fields, consistency and distillation methods compress paths into one or a few steps, adversarial models match terminal distributions, and VAEs generate through latent kernels. Existing unifying views mainly describe how such paths are constructed. We study a complementary question: when is a generated probability path self-consistent? We define a self-consistent generative path as a random fixed point of admissible local variational transport corrections. In this framework, a local correction is specified by a random variational transport operator combining a divergence or geometry term, an energy term, and a structural constraint. The framework contains random regularized optimal-transport proximal steps as a structured instance, while also allowing non-OT divergences, latent kernels, adversarial constraints, causal discrete kernels, and terminal one-step maps. The theory yields a random fixed-point path residual (R-FPR), which measures the gap between the actual generated path and an admissible local correction. We prove well-posedness, random fixed-point existence and attraction, non-contractive existence, residual-to-generation error bounds, empirical residual concentration, proxy perturbation bounds, continuous-time limits, and operator-level generalization with model-specific corollaries. The resulting theory turns endpoint matching into path self-consistency testing and provides a residual-control principle for diagnosing failures, regularizing training, and guiding adaptive sampling across diffusion, flow, one-step, VAE, GAN/WGAN, and autoregressive generators.
Conditional Random Ordered Transport Spaces
Jun 06, 2026A small Wasserstein distance does not certify that a transformation is admissible. In evidence-constrained, semantic, causal, physical, monotone, or risk-sensitive learning, one must ask not only how far two probability laws are, but whether mass has moved in a direction allowed by available information. We introduce conditional random ordered transport spaces (CROTS), a class of \(L^0\)-valued spaces of random probability measures equipped with a Wasserstein ambient metric, a closed stochastic order, hard and soft ordered transport discrepancies, and a conditional risk functional for evaluating order violation under an evidence sigma-field. The central object is an order-admissible transport geometry for random measure-valued dynamics, distinct from cone-valued metrics, ordered Kantorovich constructions, random Wasserstein spaces alone, and model-specific residuals for generative paths. We develop the foundations of CROTS as a space theory for reliable distributional learning. The results include well-posedness and duality for hard and soft ordered transport, soft-to-hard variational convergence, measurability and completeness of the random lifted space, reductions to classical Wasserstein and ordered geometries, ordered geodesics, constrained barycenters and projections, conditional risk-transport duality, and separation of order-violating distributions. The main stability theorem shows that random learning dynamics may converge in the ambient Wasserstein metric while its local admissibility leakage follows a separate conditional order-risk recursion. The resulting asymptotic order-risk floor provides a mathematical language for evidence overreach, ordered distribution shift, robustness failure, and admissible distributional dynamics.
Cone-Compatible Monge Geometry for High-Dimensional Ordered Optimal Transport
Jun 03, 2026High-dimensional optimal transport is seldom available in closed form. The one-dimensional case is exceptional because the order of the real line is compatible with convex transport costs, making monotone rearrangement optimal. This paper studies when an analogous Monge structure can be recovered in higher dimensions from a partial order. We introduce a cone-compatible Monge geometry: a closed convex cone (K) induces the order (x\preceq_K y) whenever (y-x\in K), and is compatible with a cost if ordered pairs satisfy a Monge exchange inequality. For squared Mahalanobis costs (c_M(x,y)=(x-y)^\top M(x-y)), we prove a sharp characterization: compatibility holds exactly when (K) is acute under the (M)-inner product, namely (u^\top Mv\ge0) for all (u,v\in K), equivalently (K\subseteq K_M^*). Under this condition, measures supported on cone chains admit a quantile-type closed-form optimal coupling, yielding exact transport under the original ground cost rather than after projection or metric replacement. We distinguish the resulting cone-chain Wasserstein metric on canonically ordered chain distributions from an extended directed cone transport cost on general measures, and develop feasibility, duality, stability, approximation, Gaussian recovery, statistical, and computational results. The theory is complementary to sliced and tree Wasserstein distances: it is not a universal fast surrogate, but a way to obtain interpretable, direction-valid, original-space monotone transport for ordered high-dimensional data.
Noise-Started One-Step Real-World Super-Resolution via LR-Conditioned SplitMeanFlow and GAN Refinement
May 10, 2026Pre-trained text-to-image (T2I) diffusion models have shown strong potential for real-world image super-resolution (Real-ISR), owing to their noise-started generation process that enables realistic texture synthesis and captures the one-to-many nature of super-resolution. However, diffusion-based Real-ISR methods still face a fundamental efficiency-quality trade-off. Multi-step methods generate high-quality results by iteratively denoising random Gaussian noise under LR conditioning, but suffer from slow sampling. Recent one-step methods greatly improve efficiency, yet they typically replace noise-started generation with direct LR-to-HR restoration, which weakens stochasticity and limits realistic detail synthesis. To address this issue, we propose SMFSR, a noise-started one-step Real-ISR framework via LR-conditioned SplitMeanFlow and GAN refinement. SMFSR preserves the random-noise starting point of diffusion models and learns a direct noise-to-HR mapping conditioned on the LR image. To this end, Interval Splitting Consistency distills the multi-step generative trajectory into a single average-velocity prediction, enabling efficient one-step generation. To compensate for the reduced opportunity for progressive refinement, we further introduce a GAN refinement stage, where a DINOv3-based discriminator enhances realistic texture synthesis and variational score distillation aligns the generated outputs with the natural image distribution under a frozen diffusion teacher. Extensive experiments demonstrate that SMFSR achieves state-of-the-art perceptual quality among one-step diffusion-based Real-ISR methods while retaining fast single-step inference.
ASGNet: Adaptive Spectrum Guidance Network for Automatic Polyp Segmentation
Apr 16, 2026Early identification and removal of polyps can reduce the risk of developing colorectal cancer. However, the diverse morphologies, complex backgrounds and often concealed nature of polyps make polyp segmentation in colonoscopy images highly challenging. Despite the promising performance of existing deep learning-based polyp segmentation methods, their perceptual capabilities remain biased toward local regions, mainly because of the strong spatial correlations between neighboring pixels in the spatial domain. This limitation makes it difficult to capture the complete polyp structures, ultimately leading to sub-optimal segmentation results. In this paper, we propose a novel adaptive spectrum guidance network, called ASGNet, which addresses the limitations of spatial perception by integrating spectral features with global attributes. Specifically, we first design a spectrum-guided non-local perception module that jointly aggregates local and global information, therefore enhancing the discriminability of polyp structures, and refining their boundaries. Moreover, we introduce a multi-source semantic extractor that integrates rich high-level semantic information to assist in the preliminary localization of polyps. Furthermore, we construct a dense cross-layer interaction decoder that effectively integrates diverse information from different layers and strengthens it to generate high-quality representations for accurate polyp segmentation. Extensive quantitative and qualitative results demonstrate the superiority of our ASGNet approach over 21 state-of-the-art methods across five widely-used polyp segmentation benchmarks. The code will be publicly available at: https://github.com/CSYSI/ASGNet.
Free-Range Gaussians: Non-Grid-Aligned Generative 3D Gaussian Reconstruction
Apr 06, 2026We present Free-Range Gaussians, a multi-view reconstruction method that predicts non-pixel, non-voxel-aligned 3D Gaussians from as few as four images. This is done through flow matching over Gaussian parameters. Our generative formulation of reconstruction allows the model to be supervised with non-grid-aligned 3D data, and enables it to synthesize plausible content in unobserved regions. Thus, it improves on prior methods that produce highly redundant grid-aligned Gaussians, and suffer from holes or blurry conditional means in unobserved regions. To handle the number of Gaussians needed for high-quality results, we introduce a hierarchical patching scheme to group spatially related Gaussians into joint transformer tokens, halving the sequence length while preserving structure. We further propose a timestep-weighted rendering loss during training, and photometric gradient guidance and classifier-free guidance at inference to improve fidelity. Experiments on Objaverse and Google Scanned Objects show consistent improvements over pixel and voxel-aligned methods while using significantly fewer Gaussians, with large gains when input views leave parts of the object unobserved.
LaVR: Scene Latent Conditioned Generative Video Trajectory Re-Rendering using Large 4D Reconstruction Models
Jan 21, 2026Given a monocular video, the goal of video re-rendering is to generate views of the scene from a novel camera trajectory. Existing methods face two distinct challenges. Geometrically unconditioned models lack spatial awareness, leading to drift and deformation under viewpoint changes. On the other hand, geometrically-conditioned models depend on estimated depth and explicit reconstruction, making them susceptible to depth inaccuracies and calibration errors. We propose to address these challenges by using the implicit geometric knowledge embedded in the latent space of a large 4D reconstruction model to condition the video generation process. These latents capture scene structure in a continuous space without explicit reconstruction. Therefore, they provide a flexible representation that allows the pretrained diffusion prior to regularize errors more effectively. By jointly conditioning on these latents and source camera poses, we demonstrate that our model achieves state-of-the-art results on the video re-rendering task. Project webpage is https://lavr-4d-scene-rerender.github.io/
Small but Mighty: Dynamic Wavelet Expert-Guided Fine-Tuning of Large-Scale Models for Optical Remote Sensing Object Segmentation
Jan 14, 2026Accurately localizing and segmenting relevant objects from optical remote sensing images (ORSIs) is critical for advancing remote sensing applications. Existing methods are typically built upon moderate-scale pre-trained models and employ diverse optimization strategies to achieve promising performance under full-parameter fine-tuning. In fact, deeper and larger-scale foundation models can provide stronger support for performance improvement. However, due to their massive number of parameters, directly adopting full-parameter fine-tuning leads to pronounced training difficulties, such as excessive GPU memory consumption and high computational costs, which result in extremely limited exploration of large-scale models in existing works. In this paper, we propose a novel dynamic wavelet expert-guided fine-tuning paradigm with fewer trainable parameters, dubbed WEFT, which efficiently adapts large-scale foundation models to ORSIs segmentation tasks by leveraging the guidance of wavelet experts. Specifically, we introduce a task-specific wavelet expert extractor to model wavelet experts from different perspectives and dynamically regulate their outputs, thereby generating trainable features enriched with task-specific information for subsequent fine-tuning. Furthermore, we construct an expert-guided conditional adapter that first enhances the fine-grained perception of frozen features for specific tasks by injecting trainable features, and then iteratively updates the information of both types of feature, allowing for efficient fine-tuning. Extensive experiments show that our WEFT not only outperforms 21 state-of-the-art (SOTA) methods on three ORSIs datasets, but also achieves optimal results in camouflage, natural, and medical scenarios. The source code is available at: https://github.com/CSYSI/WEFT.
A General Anchor-Based Framework for Scalable Fair Clustering
Nov 13, 2025Fair clustering is crucial for mitigating bias in unsupervised learning, yet existing algorithms often suffer from quadratic or super-quadratic computational complexity, rendering them impractical for large-scale datasets. To bridge this gap, we introduce the Anchor-based Fair Clustering Framework (AFCF), a novel, general, and plug-and-play framework that empowers arbitrary fair clustering algorithms with linear-time scalability. Our approach first selects a small but representative set of anchors using a novel fair sampling strategy. Then, any off-the-shelf fair clustering algorithm can be applied to this small anchor set. The core of our framework lies in a novel anchor graph construction module, where we formulate an optimization problem to propagate labels while preserving fairness. This is achieved through a carefully designed group-label joint constraint, which we prove theoretically ensures that the fairness of the final clustering on the entire dataset matches that of the anchor clustering. We solve this optimization efficiently using an ADMM-based algorithm. Extensive experiments on multiple large-scale benchmarks demonstrate that AFCF drastically accelerates state-of-the-art methods, which reduces computational time by orders of magnitude while maintaining strong clustering performance and fairness guarantees.
QoE Optimization for Semantic Self-Correcting Video Transmission in Multi-UAV Networks
Jul 09, 2025
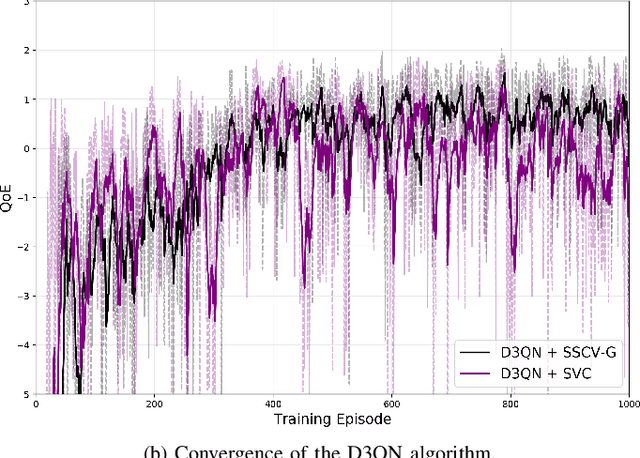
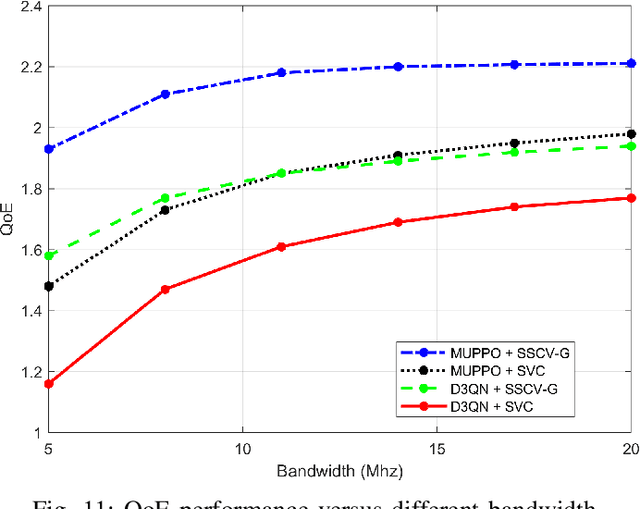
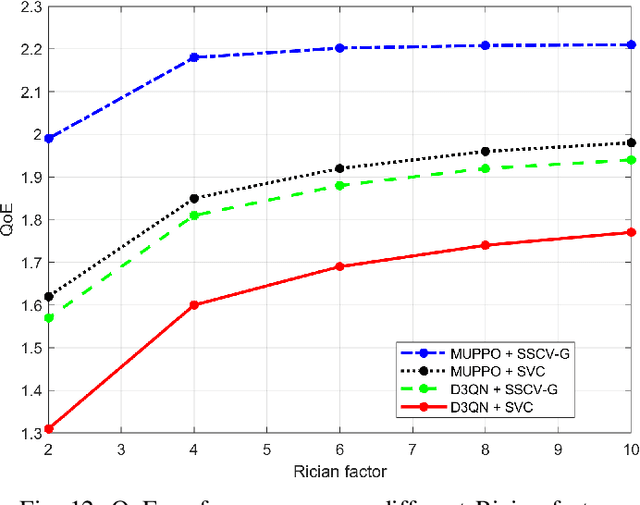
Real-time unmanned aerial vehicle (UAV) video streaming is essential for time-sensitive applications, including remote surveillance, emergency response, and environmental monitoring. However, it faces challenges such as limited bandwidth, latency fluctuations, and high packet loss. To address these issues, we propose a novel semantic self-correcting video transmission framework with ultra-fine bitrate granularity (SSCV-G). In SSCV-G, video frames are encoded into a compact semantic codebook space, and the transmitter adaptively sends a subset of semantic indices based on bandwidth availability, enabling fine-grained bitrate control for improved bandwidth efficiency. At the receiver, a spatio-temporal vision transformer (ST-ViT) performs multi-frame joint decoding to reconstruct dropped semantic indices by modeling intra- and inter-frame dependencies. To further improve performance under dynamic network conditions, we integrate a multi-user proximal policy optimization (MUPPO) reinforcement learning scheme that jointly optimizes communication resource allocation and semantic bitrate selection to maximize user Quality of Experience (QoE). Extensive experiments demonstrate that the proposed SSCV-G significantly outperforms state-of-the-art video codecs in coding efficiency, bandwidth adaptability, and packet loss robustness. Moreover, the proposed MUPPO-based QoE optimization consistently surpasses existing benchmarks.