 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Feb 09, 2026Large Language Model (LLM) agents have shown stunning results in complex tasks, yet they often operate in isolation, failing to learn from past experiences. Existing memory-based methods primarily store raw trajectories, which are often redundant and noise-heavy. This prevents agents from extracting high-level, reusable behavioral patterns that are essential for generalization. In this paper, we propose SkillRL, a framework that bridges the gap between raw experience and policy improvement through automatic skill discovery and recursive evolution. Our approach introduces an experience-based distillation mechanism to build a hierarchical skill library SkillBank, an adaptive retrieval strategy for general and task-specific heuristics, and a recursive evolution mechanism that allows the skill library to co-evolve with the agent's policy during reinforcement learning. These innovations significantly reduce the token footprint while enhancing reasoning utility. Experimental results on ALFWorld, WebShop and seven search-augmented tasks demonstrate that SkillRL achieves state-of-the-art performance, outperforming strong baselines over 15.3% and maintaining robustness as task complexity increases. Code is available at this https://github.com/aiming-lab/SkillRL.
Spiral RoPE: Rotate Your Rotary Positional Embeddings in the 2D Plane
Feb 03, 2026Rotary Position Embedding (RoPE) is the de facto positional encoding in large language models due to its ability to encode relative positions and support length extrapolation. When adapted to vision transformers, the standard axial formulation decomposes two-dimensional spatial positions into horizontal and vertical components, implicitly restricting positional encoding to axis-aligned directions. We identify this directional constraint as a fundamental limitation of the standard axial 2D RoPE, which hinders the modeling of oblique spatial relationships that naturally exist in natural images. To overcome this limitation, we propose Spiral RoPE, a simple yet effective extension that enables multi-directional positional encoding by partitioning embedding channels into multiple groups associated with uniformly distributed directions. Each group is rotated according to the projection of the patch position onto its corresponding direction, allowing spatial relationships to be encoded beyond the horizontal and vertical axes. Across a wide range of vision tasks including classification, segmentation, and generation, Spiral RoPE consistently improves performance. Qualitative analysis of attention maps further show that Spiral RoPE exhibits more concentrated activations on semantically relevant objects and better respects local object boundaries, highlighting the importance of multi-directional positional encoding in vision transformers.
OpenVision 3: A Family of Unified Visual Encoder for Both Understanding and Generation
Jan 21, 2026This paper presents a family of advanced vision encoder, named OpenVision 3, that learns a single, unified visual representation that can serve both image understanding and image generation. Our core architecture is simple: we feed VAE-compressed image latents to a ViT encoder and train its output to support two complementary roles. First, the encoder output is passed to the ViT-VAE decoder to reconstruct the original image, encouraging the representation to capture generative structure. Second, the same representation is optimized with contrastive learning and image-captioning objectives, strengthening semantic features. By jointly optimizing reconstruction- and semantics-driven signals in a shared latent space, the encoder learns representations that synergize and generalize well across both regimes. We validate this unified design through extensive downstream evaluations with the encoder frozen. For multimodal understanding, we plug the encoder into the LLaVA-1.5 framework: it performs comparably with a standard CLIP vision encoder (e.g., 62.4 vs 62.2 on SeedBench, and 83.7 vs 82.9 on POPE). For generation, we test it under the RAE framework: ours substantially surpasses the standard CLIP-based encoder (e.g., gFID: 1.89 vs 2.54 on ImageNet). We hope this work can spur future research on unified modeling.
MagicGUI-RMS: A Multi-Agent Reward Model System for Self-Evolving GUI Agents via Automated Feedback Reflux
Jan 19, 2026Graphical user interface (GUI) agents are rapidly progressing toward autonomous interaction and reliable task execution across diverse applications. However, two central challenges remain unresolved: automating the evaluation of agent trajectories and generating high-quality training data at scale to enable continual improvement. Existing approaches often depend on manual annotation or static rule-based verification, which restricts scalability and limits adaptability in dynamic environments. We present MagicGUI-RMS, a multi-agent reward model system that delivers adaptive trajectory evaluation, corrective feedback, and self-evolving learning capabilities. MagicGUI-RMS integrates a Domain-Specific Reward Model (DS-RM) with a General-Purpose Reward Model (GP-RM), enabling fine-grained action assessment and robust generalization across heterogeneous GUI tasks. To support reward learning at scale, we design a structured data construction pipeline that automatically produces balanced and diverse reward datasets, effectively reducing annotation costs while maintaining sample fidelity. During execution, the reward model system identifies erroneous actions, proposes refined alternatives, and continuously enhances agent behavior through an automated data-reflux mechanism. Extensive experiments demonstrate that MagicGUI-RMS yields substantial gains in task accuracy, behavioral robustness. These results establish MagicGUI-RMS as a principled and effective foundation for building self-improving GUI agents driven by reward-based adaptation.
SimpleMem: Efficient Lifelong Memory for LLM Agents
Jan 05, 2026To support reliable long-term interaction in complex environments, LLM agents require memory systems that efficiently manage historical experiences. Existing approaches either retain full interaction histories via passive context extension, leading to substantial redundancy, or rely on iterative reasoning to filter noise, incurring high token costs. To address this challenge, we introduce SimpleMem, an efficient memory framework based on semantic lossless compression. We propose a three-stage pipeline designed to maximize information density and token utilization: (1) \textit{Semantic Structured Compression}, which applies entropy-aware filtering to distill unstructured interactions into compact, multi-view indexed memory units; (2) \textit{Recursive Memory Consolidation}, an asynchronous process that integrates related units into higher-level abstract representations to reduce redundancy; and (3) \textit{Adaptive Query-Aware Retrieval}, which dynamically adjusts retrieval scope based on query complexity to construct precise context efficiently. Experiments on benchmark datasets show that our method consistently outperforms baseline approaches in accuracy, retrieval efficiency, and inference cost, achieving an average F1 improvement of 26.4% while reducing inference-time token consumption by up to 30-fold, demonstrating a superior balance between performance and efficiency. Code is available at https://github.com/aiming-lab/SimpleMem.
Seed-Prover 1.5: Mastering Undergraduate-Level Theorem Proving via Learning from Experience
Dec 19, 2025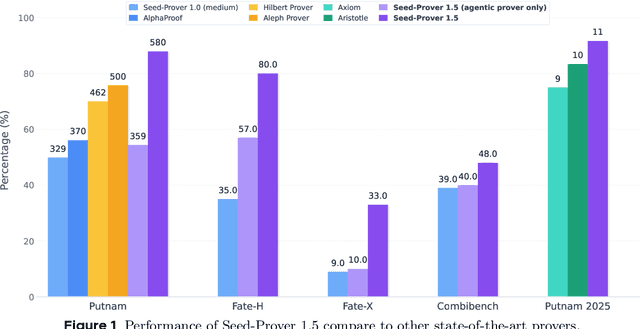

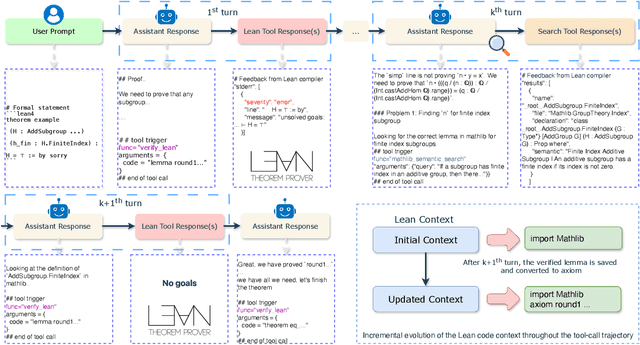

Large language models have recently made significant progress to generate rigorous mathematical proofs. In contrast, utilizing LLMs for theorem proving in formal languages (such as Lean) remains challenging and computationally expensive, particularly when addressing problems at the undergraduate level and beyond. In this work, we present \textbf{Seed-Prover 1.5}, a formal theorem-proving model trained via large-scale agentic reinforcement learning, alongside an efficient test-time scaling (TTS) workflow. Through extensive interactions with Lean and other tools, the model continuously accumulates experience during the RL process, substantially enhancing the capability and efficiency of formal theorem proving. Furthermore, leveraging recent advancements in natural language proving, our TTS workflow efficiently bridges the gap between natural and formal languages. Compared to state-of-the-art methods, Seed-Prover 1.5 achieves superior performance with a smaller compute budget. It solves \textbf{88\% of PutnamBench} (undergraduate-level), \textbf{80\% of Fate-H} (graduate-level), and \textbf{33\% of Fate-X} (PhD-level) problems. Notably, using our system, we solved \textbf{11 out of 12 problems} from Putnam 2025 within 9 hours. Our findings suggest that scaling learning from experience, driven by high-quality formal feedback, holds immense potential for the future of formal mathematical reasoning.
Insight Miner: A Time Series Analysis Dataset for Cross-Domain Alignment with Natural Language
Dec 12, 2025

Time-series data is critical across many scientific and industrial domains, including environmental analysis, agriculture, transportation, and finance. However, mining insights from this data typically requires deep domain expertise, a process that is both time-consuming and labor-intensive. In this paper, we propose \textbf{Insight Miner}, a large-scale multimodal model (LMM) designed to generate high-quality, comprehensive time-series descriptions enriched with domain-specific knowledge. To facilitate this, we introduce \textbf{TS-Insights}\footnote{Available at \href{https://huggingface.co/datasets/zhykoties/time-series-language-alignment}{https://huggingface.co/datasets/zhykoties/time-series-language-alignment}.}, the first general-domain dataset for time series and language alignment. TS-Insights contains 100k time-series windows sampled from 20 forecasting datasets. We construct this dataset using a novel \textbf{agentic workflow}, where we use statistical tools to extract features from raw time series before synthesizing them into coherent trend descriptions with GPT-4. Following instruction tuning on TS-Insights, Insight Miner outperforms state-of-the-art multimodal models, such as LLaVA \citep{liu2023llava} and GPT-4, in generating time-series descriptions and insights. Our findings suggest a promising direction for leveraging LMMs in time series analysis, and serve as a foundational step toward enabling LLMs to interpret time series as a native input modality.
Don't Waste It: Guiding Generative Recommenders with Structured Human Priors via Multi-head Decoding
Nov 16, 2025Optimizing recommender systems for objectives beyond accuracy, such as diversity, novelty, and personalization, is crucial for long-term user satisfaction. To this end, industrial practitioners have accumulated vast amounts of structured domain knowledge, which we term human priors (e.g., item taxonomies, temporal patterns). This knowledge is typically applied through post-hoc adjustments during ranking or post-ranking. However, this approach remains decoupled from the core model learning, which is particularly undesirable as the industry shifts to end-to-end generative recommendation foundation models. On the other hand, many methods targeting these beyond-accuracy objectives often require architecture-specific modifications and discard these valuable human priors by learning user intent in a fully unsupervised manner. Instead of discarding the human priors accumulated over years of practice, we introduce a backbone-agnostic framework that seamlessly integrates these human priors directly into the end-to-end training of generative recommenders. With lightweight, prior-conditioned adapter heads inspired by efficient LLM decoding strategies, our approach guides the model to disentangle user intent along human-understandable axes (e.g., interaction types, long- vs. short-term interests). We also introduce a hierarchical composition strategy for modeling complex interactions across different prior types. Extensive experiments on three large-scale datasets demonstrate that our method significantly enhances both accuracy and beyond-accuracy objectives. We also show that human priors allow the backbone model to more effectively leverage longer context lengths and larger model sizes.
An Energy-Efficient Edge Coprocessor for Neural Rendering with Explicit Data Reuse Strategies
Oct 09, 2025
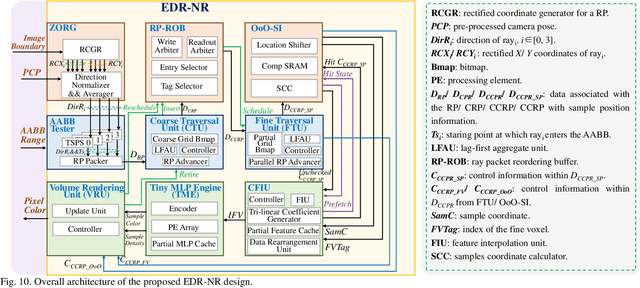
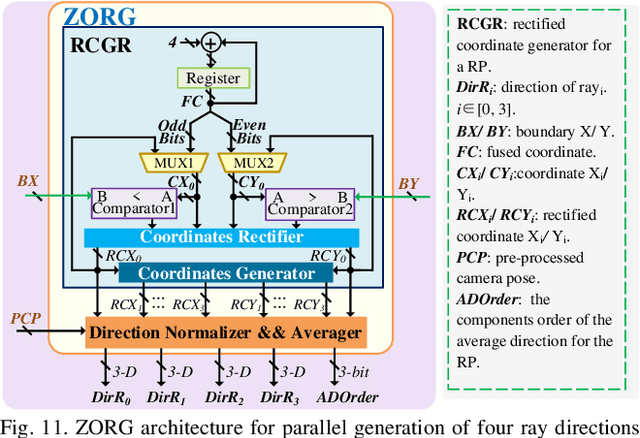
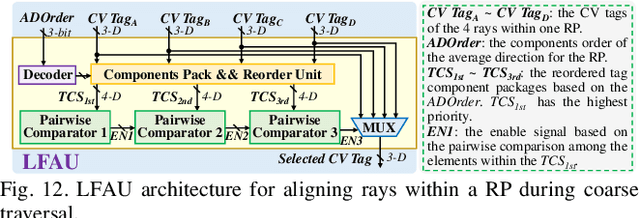
Neural radiance fields (NeRF) have transformed 3D reconstruction and rendering, facilitating photorealistic image synthesis from sparse viewpoints. This work introduces an explicit data reuse neural rendering (EDR-NR) architecture, which reduces frequent external memory accesses (EMAs) and cache misses by exploiting the spatial locality from three phases, including rays, ray packets (RPs), and samples. The EDR-NR architecture features a four-stage scheduler that clusters rays on the basis of Z-order, prioritize lagging rays when ray divergence happens, reorders RPs based on spatial proximity, and issues samples out-of-orderly (OoO) according to the availability of on-chip feature data. In addition, a four-tier hierarchical RP marching (HRM) technique is integrated with an axis-aligned bounding box (AABB) to facilitate spatial skipping (SS), reducing redundant computations and improving throughput. Moreover, a balanced allocation strategy for feature storage is proposed to mitigate SRAM bank conflicts. Fabricated using a 40 nm process with a die area of 10.5 mmX, the EDR-NR chip demonstrates a 2.41X enhancement in normalized energy efficiency, a 1.21X improvement in normalized area efficiency, a 1.20X increase in normalized throughput, and a 53.42% reduction in on-chip SRAM consumption compared to state-of-the-art accelerators.
A Survey of Process Reward Models: From Outcome Signals to Process Supervisions for Large Language Models
Oct 09, 2025


Although Large Language Models (LLMs) exhibit advanced reasoning ability, conventional alignment remains largely dominated by outcome reward models (ORMs) that judge only final answers. Process Reward Models(PRMs) address this gap by evaluating and guiding reasoning at the step or trajectory level. This survey provides a systematic overview of PRMs through the full loop: how to generate process data, build PRMs, and use PRMs for test-time scaling and reinforcement learning. We summarize applications across math, code, text, multimodal reasoning, robotics, and agents, and review emerging benchmarks. Our goal is to clarify design spaces, reveal open challenges, and guide future research toward fine-grained, robust reasoning alignment.