 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsight Miner: A Time Series Analysis Dataset for Cross-Domain Alignment with Natural Language
Dec 12, 2025

Time-series data is critical across many scientific and industrial domains, including environmental analysis, agriculture, transportation, and finance. However, mining insights from this data typically requires deep domain expertise, a process that is both time-consuming and labor-intensive. In this paper, we propose \textbf{Insight Miner}, a large-scale multimodal model (LMM) designed to generate high-quality, comprehensive time-series descriptions enriched with domain-specific knowledge. To facilitate this, we introduce \textbf{TS-Insights}\footnote{Available at \href{https://huggingface.co/datasets/zhykoties/time-series-language-alignment}{https://huggingface.co/datasets/zhykoties/time-series-language-alignment}.}, the first general-domain dataset for time series and language alignment. TS-Insights contains 100k time-series windows sampled from 20 forecasting datasets. We construct this dataset using a novel \textbf{agentic workflow}, where we use statistical tools to extract features from raw time series before synthesizing them into coherent trend descriptions with GPT-4. Following instruction tuning on TS-Insights, Insight Miner outperforms state-of-the-art multimodal models, such as LLaVA \citep{liu2023llava} and GPT-4, in generating time-series descriptions and insights. Our findings suggest a promising direction for leveraging LMMs in time series analysis, and serve as a foundational step toward enabling LLMs to interpret time series as a native input modality.
IM-RAG: Multi-Round Retrieval-Augmented Generation Through Learning Inner Monologues
May 15, 2024



Although the Retrieval-Augmented Generation (RAG) paradigms can use external knowledge to enhance and ground the outputs of Large Language Models (LLMs) to mitigate generative hallucinations and static knowledge base problems, they still suffer from limited flexibility in adopting Information Retrieval (IR) systems with varying capabilities, constrained interpretability during the multi-round retrieval process, and a lack of end-to-end optimization. To address these challenges, we propose a novel LLM-centric approach, IM-RAG, that integrates IR systems with LLMs to support multi-round RAG through learning Inner Monologues (IM, i.e., the human inner voice that narrates one's thoughts). During the IM process, the LLM serves as the core reasoning model (i.e., Reasoner) to either propose queries to collect more information via the Retriever or to provide a final answer based on the conversational context. We also introduce a Refiner that improves the outputs from the Retriever, effectively bridging the gap between the Reasoner and IR modules with varying capabilities and fostering multi-round communications. The entire IM process is optimized via Reinforcement Learning (RL) where a Progress Tracker is incorporated to provide mid-step rewards, and the answer prediction is further separately optimized via Supervised Fine-Tuning (SFT). We conduct extensive experiments with the HotPotQA dataset, a popular benchmark for retrieval-based, multi-step question-answering. The results show that our approach achieves state-of-the-art (SOTA) performance while providing high flexibility in integrating IR modules as well as strong interpretability exhibited in the learned inner monologues.
Higher Layers Need More LoRA Experts
Feb 13, 2024



Parameter-efficient tuning (PEFT) techniques like low-rank adaptation (LoRA) offer training efficiency on Large Language Models, but their impact on model performance remains limited. Recent efforts integrate LoRA and Mixture-of-Experts (MoE) to improve the performance of PEFT methods. Despite promising results, research on improving the efficiency of LoRA with MoE is still in its early stages. Recent studies have shown that experts in the MoE architecture have different strengths and also exhibit some redundancy. Does this statement also apply to parameter-efficient MoE? In this paper, we introduce a novel parameter-efficient MoE method, \textit{\textbf{M}oE-L\textbf{o}RA with \textbf{L}ayer-wise Expert \textbf{A}llocation (MoLA)} for Transformer-based models, where each model layer has the flexibility to employ a varying number of LoRA experts. We investigate several architectures with varying layer-wise expert configurations. Experiments on six well-known NLP and commonsense QA benchmarks demonstrate that MoLA achieves equal or superior performance compared to all baselines. We find that allocating more LoRA experts to higher layers further enhances the effectiveness of models with a certain number of experts in total. With much fewer parameters, this allocation strategy outperforms the setting with the same number of experts in every layer. This work can be widely used as a plug-and-play parameter-efficient tuning approach for various applications. The code is available at https://github.com/GCYZSL/MoLA.
Evaluation and Mitigation of Agnosia in Multimodal Large Language Models
Sep 07, 2023



While Multimodal Large Language Models (MLLMs) are widely used for a variety of vision-language tasks, one observation is that they sometimes misinterpret visual inputs or fail to follow textual instructions even in straightforward cases, leading to irrelevant responses, mistakes, and ungrounded claims. This observation is analogous to a phenomenon in neuropsychology known as Agnosia, an inability to correctly process sensory modalities and recognize things (e.g., objects, colors, relations). In our study, we adapt this similar concept to define "agnosia in MLLMs", and our goal is to comprehensively evaluate and mitigate such agnosia in MLLMs. Inspired by the diagnosis and treatment process in neuropsychology, we propose a novel framework EMMA (Evaluation and Mitigation of Multimodal Agnosia). In EMMA, we develop an evaluation module that automatically creates fine-grained and diverse visual question answering examples to assess the extent of agnosia in MLLMs comprehensively. We also develop a mitigation module to reduce agnosia in MLLMs through multimodal instruction tuning on fine-grained conversations. To verify the effectiveness of our framework, we evaluate and analyze agnosia in seven state-of-the-art MLLMs using 9K test samples. The results reveal that most of them exhibit agnosia across various aspects and degrees. We further develop a fine-grained instruction set and tune MLLMs to mitigate agnosia, which led to notable improvement in accuracy.
Tackling Vision Language Tasks Through Learning Inner Monologues
Aug 19, 2023



Visual language tasks require AI models to comprehend and reason with both visual and textual content. Driven by the power of Large Language Models (LLMs), two prominent methods have emerged: (1) the hybrid integration between LLMs and Vision-Language Models (VLMs), where visual inputs are firstly converted into language descriptions by VLMs, serving as inputs for LLMs to generate final answer(s); (2) visual feature alignment in language space, where visual inputs are encoded as embeddings and projected to LLMs' language space via further supervised fine-tuning. The first approach provides light training costs and interpretability but is hard to be optimized in an end-to-end fashion. The second approach presents decent performance, but feature alignment usually requires large amounts of training data and lacks interpretability. To tackle this dilemma, we propose a novel approach, Inner Monologue Multi-Modal Optimization (IMMO), to solve complex vision language problems by simulating inner monologue processes, a cognitive process in which an individual engages in silent verbal communication with themselves. We enable LLMs and VLMs to interact through natural language conversation and propose to use a two-stage training process to learn how to do the inner monologue (self-asking questions and answering questions). IMMO is evaluated on two popular tasks and the results suggest by emulating the cognitive phenomenon of internal dialogue, our approach can enhance reasoning and explanation abilities, contributing to the more effective fusion of vision and language models. More importantly, instead of using predefined human-crafted monologues, IMMO learns this process within the deep learning models, promising wider applicability to many different AI problems beyond vision language tasks.
LOWA: Localize Objects in the Wild with Attributes
May 31, 2023



We present LOWA, a novel method for localizing objects with attributes effectively in the wild. It aims to address the insufficiency of current open-vocabulary object detectors, which are limited by the lack of instance-level attribute classification and rare class names. To train LOWA, we propose a hybrid vision-language training strategy to learn object detection and recognition with class names as well as attribute information. With LOWA, users can not only detect objects with class names, but also able to localize objects by attributes. LOWA is built on top of a two-tower vision-language architecture and consists of a standard vision transformer as the image encoder and a similar transformer as the text encoder. To learn the alignment between visual and text inputs at the instance level, we train LOWA with three training steps: object-level training, attribute-aware learning, and free-text joint training of objects and attributes. This hybrid training strategy first ensures correct object detection, then incorporates instance-level attribute information, and finally balances the object class and attribute sensitivity. We evaluate our model performance of attribute classification and attribute localization on the Open-Vocabulary Attribute Detection (OVAD) benchmark and the Visual Attributes in the Wild (VAW) dataset, and experiments indicate strong zero-shot performance. Ablation studies additionally demonstrate the effectiveness of each training step of our approach.
Augmenting Vision Language Pretraining by Learning Codebook with Visual Semantics
Jul 31, 2022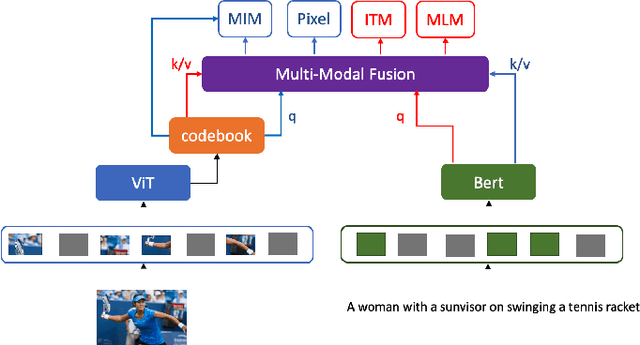



Language modality within the vision language pretraining framework is innately discretized, endowing each word in the language vocabulary a semantic meaning. In contrast, visual modality is inherently continuous and high-dimensional, which potentially prohibits the alignment as well as fusion between vision and language modalities. We therefore propose to "discretize" the visual representation by joint learning a codebook that imbues each visual token a semantic. We then utilize these discretized visual semantics as self-supervised ground-truths for building our Masked Image Modeling objective, a counterpart of Masked Language Modeling which proves successful for language models. To optimize the codebook, we extend the formulation of VQ-VAE which gives a theoretic guarantee. Experiments validate the effectiveness of our approach across common vision-language benchmarks.
OSCARS: An Outlier-Sensitive Content-Based Radiography Retrieval System
Apr 06, 2022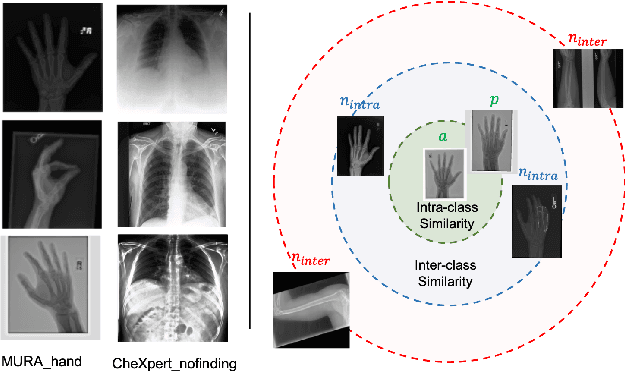

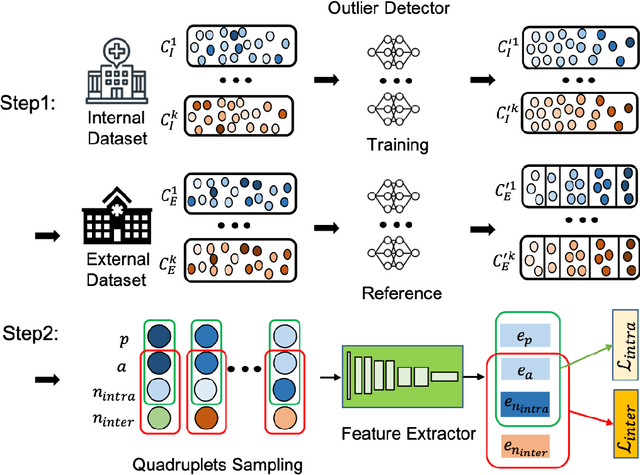

Improving the retrieval relevance on noisy datasets is an emerging need for the curation of a large-scale clean dataset in the medical domain. While existing methods can be applied for class-wise retrieval (aka. inter-class), they cannot distinguish the granularity of likeness within the same class (aka. intra-class). The problem is exacerbated on medical external datasets, where noisy samples of the same class are treated equally during training. Our goal is to identify both intra/inter-class similarities for fine-grained retrieval. To achieve this, we propose an Outlier-Sensitive Content-based rAdiologhy Retrieval System (OSCARS), consisting of two steps. First, we train an outlier detector on a clean internal dataset in an unsupervised manner. Then we use the trained detector to generate the anomaly scores on the external dataset, whose distribution will be used to bin intra-class variations. Second, we propose a quadruplet (a, p, nintra, ninter) sampling strategy, where intra-class negatives nintra are sampled from bins of the same class other than the bin anchor a belongs to, while niner are randomly sampled from inter-classes. We suggest a weighted metric learning objective to balance the intra and inter-class feature learning. We experimented on two representative public radiography datasets. Experiments show the effectiveness of our approach. The training and evaluation code can be found in https://github.com/XiaoyuanGuo/oscars.
MedShift: identifying shift data for medical dataset curation
Dec 27, 2021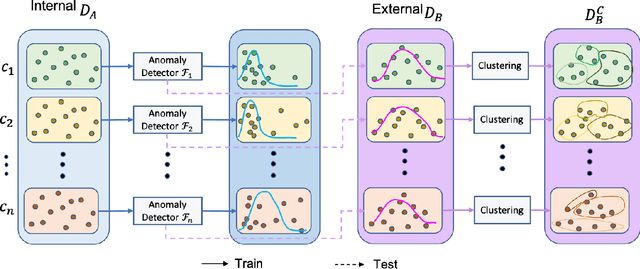
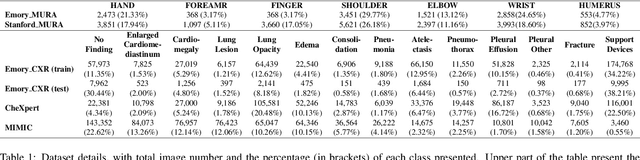
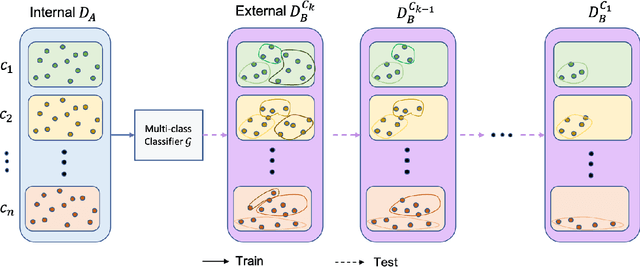
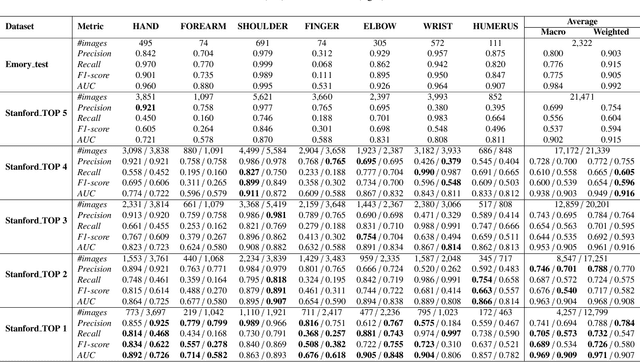
To curate a high-quality dataset, identifying data variance between the internal and external sources is a fundamental and crucial step. However, methods to detect shift or variance in data have not been significantly researched. Challenges to this are the lack of effective approaches to learn dense representation of a dataset and difficulties of sharing private data across medical institutions. To overcome the problems, we propose a unified pipeline called MedShift to detect the top-level shift samples and thus facilitate the medical curation. Given an internal dataset A as the base source, we first train anomaly detectors for each class of dataset A to learn internal distributions in an unsupervised way. Second, without exchanging data across sources, we run the trained anomaly detectors on an external dataset B for each class. The data samples with high anomaly scores are identified as shift data. To quantify the shiftness of the external dataset, we cluster B's data into groups class-wise based on the obtained scores. We then train a multi-class classifier on A and measure the shiftness with the classifier's performance variance on B by gradually dropping the group with the largest anomaly score for each class. Additionally, we adapt a dataset quality metric to help inspect the distribution differences for multiple medical sources. We verify the efficacy of MedShift with musculoskeletal radiographs (MURA) and chest X-rays datasets from more than one external source. Experiments show our proposed shift data detection pipeline can be beneficial for medical centers to curate high-quality datasets more efficiently. An interface introduction video to visualize our results is available at https://youtu.be/V3BF0P1sxQE.
CVAD: A generic medical anomaly detector based on Cascade VAE
Oct 29, 2021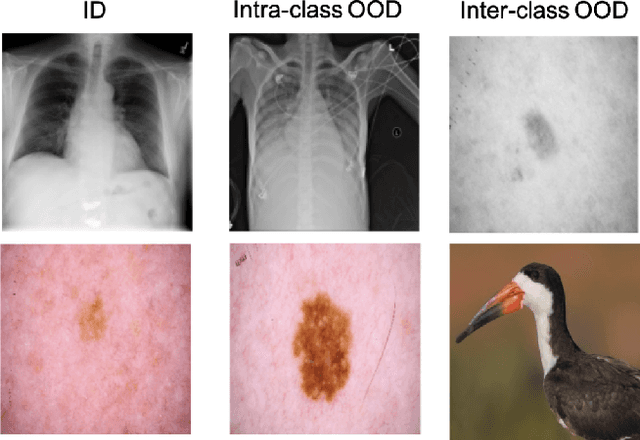

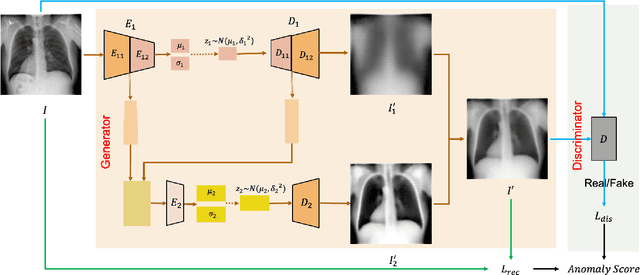
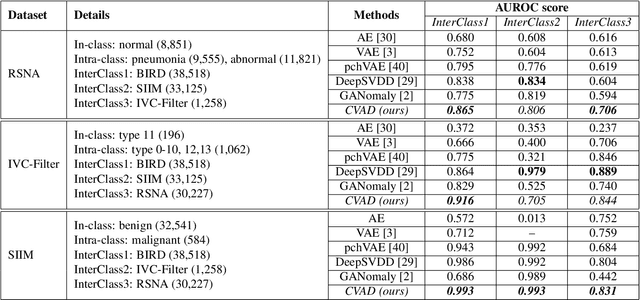
Detecting out-of-distribution (OOD) samples in medical imaging plays an important role for downstream medical diagnosis. However, existing OOD detectors are demonstrated on natural images composed of inter-classes and have difficulty generalizing to medical images. The key issue is the granularity of OOD data in the medical domain, where intra-class OOD samples are predominant. We focus on the generalizability of OOD detection for medical images and propose a self-supervised Cascade Variational autoencoder-based Anomaly Detector (CVAD). We use a variational autoencoders' cascade architecture, which combines latent representation at multiple scales, before being fed to a discriminator to distinguish the OOD data from the in-distribution (ID) data. Finally, both the reconstruction error and the OOD probability predicted by the binary discriminator are used to determine the anomalies. We compare the performance with the state-of-the-art deep learning models to demonstrate our model's efficacy on various open-access medical imaging datasets for both intra- and inter-class OOD. Further extensive results on datasets including common natural datasets show our model's effectiveness and generalizability. The code is available at https://github.com/XiaoyuanGuo/CVAD.