 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsight Miner: A Time Series Analysis Dataset for Cross-Domain Alignment with Natural Language
Dec 12, 2025

Time-series data is critical across many scientific and industrial domains, including environmental analysis, agriculture, transportation, and finance. However, mining insights from this data typically requires deep domain expertise, a process that is both time-consuming and labor-intensive. In this paper, we propose \textbf{Insight Miner}, a large-scale multimodal model (LMM) designed to generate high-quality, comprehensive time-series descriptions enriched with domain-specific knowledge. To facilitate this, we introduce \textbf{TS-Insights}\footnote{Available at \href{https://huggingface.co/datasets/zhykoties/time-series-language-alignment}{https://huggingface.co/datasets/zhykoties/time-series-language-alignment}.}, the first general-domain dataset for time series and language alignment. TS-Insights contains 100k time-series windows sampled from 20 forecasting datasets. We construct this dataset using a novel \textbf{agentic workflow}, where we use statistical tools to extract features from raw time series before synthesizing them into coherent trend descriptions with GPT-4. Following instruction tuning on TS-Insights, Insight Miner outperforms state-of-the-art multimodal models, such as LLaVA \citep{liu2023llava} and GPT-4, in generating time-series descriptions and insights. Our findings suggest a promising direction for leveraging LMMs in time series analysis, and serve as a foundational step toward enabling LLMs to interpret time series as a native input modality.
Deep non-parametric logistic model with case-control data and external summary information
Sep 03, 2024The case-control sampling design serves as a pivotal strategy in mitigating the imbalanced structure observed in binary data. We consider the estimation of a non-parametric logistic model with the case-control data supplemented by external summary information. The incorporation of external summary information ensures the identifiability of the model. We propose a two-step estimation procedure. In the first step, the external information is utilized to estimate the marginal case proportion. In the second step, the estimated proportion is used to construct a weighted objective function for parameter training. A deep neural network architecture is employed for functional approximation. We further derive the non-asymptotic error bound of the proposed estimator. Following this the convergence rate is obtained and is shown to reach the optimal speed of the non-parametric regression estimation. Simulation studies are conducted to evaluate the theoretical findings of the proposed method. A real data example is analyzed for illustration.
Statistical inference for case-control logistic regression via integrating external summary data
May 31, 2024Case-control sampling is a commonly used retrospective sampling design to alleviate imbalanced structure of binary data. When fitting the logistic regression model with case-control data, although the slope parameter of the model can be consistently estimated, the intercept parameter is not identifiable, and the marginal case proportion is not estimatable, either. We consider the situations in which besides the case-control data from the main study, called internal study, there also exists summary-level information from related external studies. An empirical likelihood based approach is proposed to make inference for the logistic model by incorporating the internal case-control data and external information. We show that the intercept parameter is identifiable with the help of external information, and then all the regression parameters as well as the marginal case proportion can be estimated consistently. The proposed method also accounts for the possible variability in external studies. The resultant estimators are shown to be asymptotically normally distributed. The asymptotic variance-covariance matrix can be consistently estimated by the case-control data. The optimal way to utilized external information is discussed. Simulation studies are conducted to verify the theoretical findings. A real data set is analyzed for illustration.
SEMRes-DDPM: Residual Network Based Diffusion Modelling Applied to Imbalanced Data
Mar 12, 2024



In the field of data mining and machine learning, commonly used classification models cannot effectively learn in unbalanced data. In order to balance the data distribution before model training, oversampling methods are often used to generate data for a small number of classes to solve the problem of classifying unbalanced data. Most of the classical oversampling methods are based on the SMOTE technique, which only focuses on the local information of the data, and therefore the generated data may have the problem of not being realistic enough. In the current oversampling methods based on generative networks, the methods based on GANs can capture the true distribution of data, but there is the problem of pattern collapse and training instability in training; in the oversampling methods based on denoising diffusion probability models, the neural network of the inverse diffusion process using the U-Net is not applicable to tabular data, and although the MLP can be used to replace the U-Net, the problem exists due to the simplicity of the structure and the poor effect of removing noise. problem of poor noise removal. In order to overcome the above problems, we propose a novel oversampling method SEMRes-DDPM.In the SEMRes-DDPM backward diffusion process, a new neural network structure SEMST-ResNet is used, which is suitable for tabular data and has good noise removal effect, and it can generate tabular data with higher quality. Experiments show that the SEMResNet network removes noise better than MLP; SEMRes-DDPM generates data distributions that are closer to the real data distributions than TabDDPM with CWGAN-GP; on 20 real unbalanced tabular datasets with 9 classification models, SEMRes-DDPM improves the quality of the generated tabular data in terms of three evaluation metrics (F1, G-mean, AUC) with better classification performance than other SOTA oversampling methods.
Neural Frailty Machine: Beyond proportional hazard assumption in neural survival regressions
Mar 18, 2023We present neural frailty machine (NFM), a powerful and flexible neural modeling framework for survival regressions. The NFM framework utilizes the classical idea of multiplicative frailty in survival analysis to capture unobserved heterogeneity among individuals, at the same time being able to leverage the strong approximation power of neural architectures for handling nonlinear covariate dependence. Two concrete models are derived under the framework that extends neural proportional hazard models and nonparametric hazard regression models. Both models allow efficient training under the likelihood objective. Theoretically, for both proposed models, we establish statistical guarantees of neural function approximation with respect to nonparametric components via characterizing their rate of convergence. Empirically, we provide synthetic experiments that verify our theoretical statements. We also conduct experimental evaluations over $6$ benchmark datasets of different scales, showing that the proposed NFM models outperform state-of-the-art survival models in terms of predictive performance. Our code is publicly availabel at https://github.com/Rorschach1989/nfm
Artificial neural networks condensation: A strategy to facilitate adaption of machine learning in medical settings by reducing computational burden
Dec 23, 2018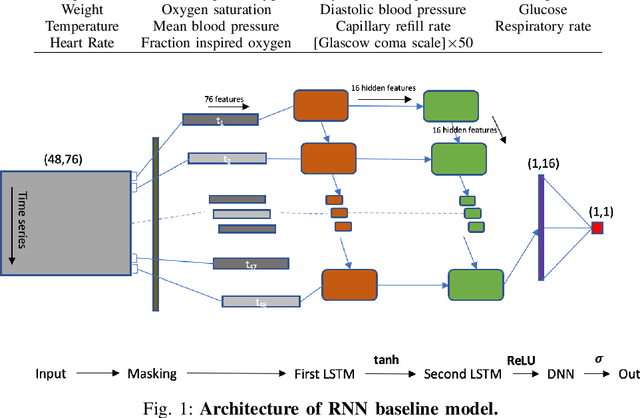
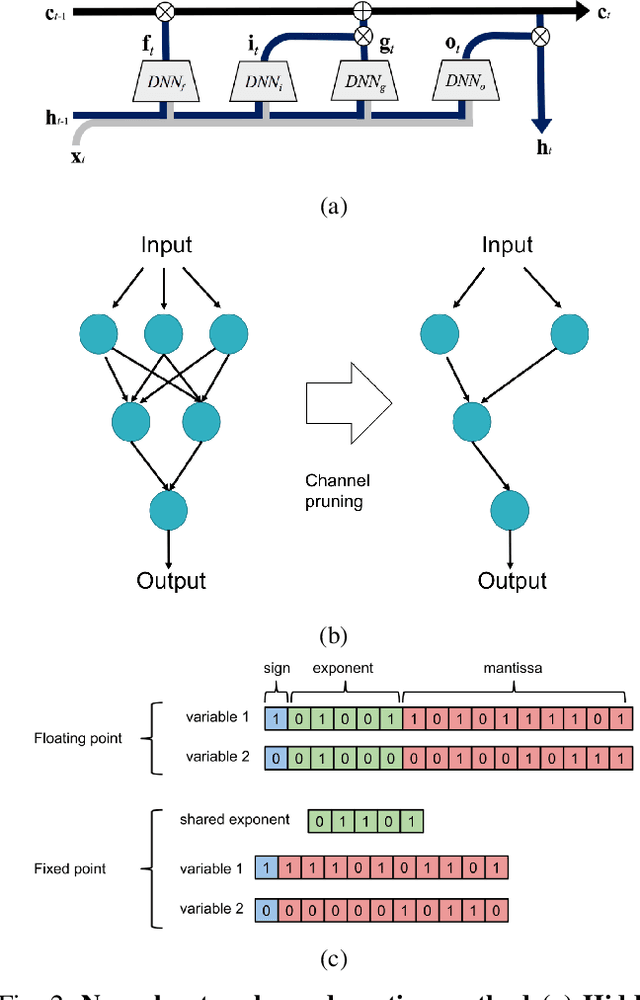
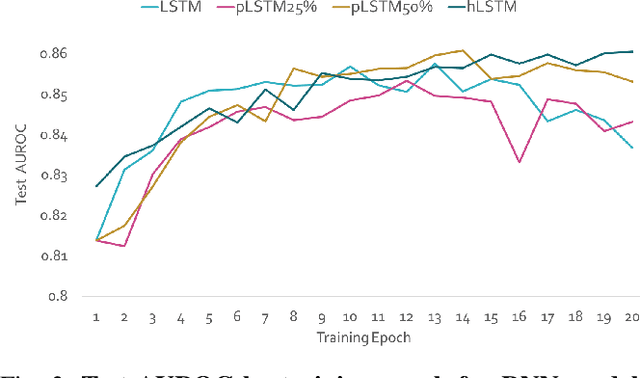
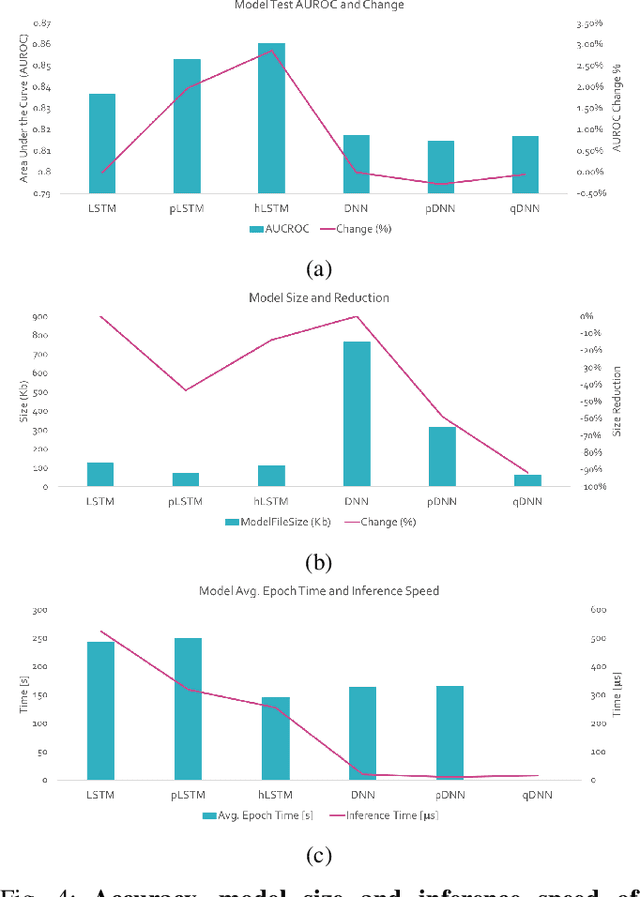
Machine Learning (ML) applications on healthcare can have a great impact on people's lives helping deliver better and timely treatment to those in need. At the same time, medical data is usually big and sparse requiring important computational resources. Although it might not be a problem for wide-adoption of ML tools in developed nations, availability of computational resource can very well be limited in third-world nations. This can prevent the less favored people from benefiting of the advancement in ML applications for healthcare. In this project we explored methods to increase computational efficiency of ML algorithms, in particular Artificial Neural Nets (NN), while not compromising the accuracy of the predicted results. We used in-hospital mortality prediction as our case analysis based on the MIMIC III publicly available dataset. We explored three methods on two different NN architectures. We reduced the size of recurrent neural net (RNN) and dense neural net (DNN) by applying pruning of "unused" neurons. Additionally, we modified the RNN structure by adding a hidden-layer to the LSTM cell allowing to use less recurrent layers for the model. Finally, we implemented quantization on DNN forcing the weights to be 8-bits instead of 32-bits. We found that all our methods increased computational efficiency without compromising accuracy and some of them even achieved higher accuracy than the pre-condensed baseline models.