 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed-Prover 1.5: Mastering Undergraduate-Level Theorem Proving via Learning from Experience
Dec 19, 2025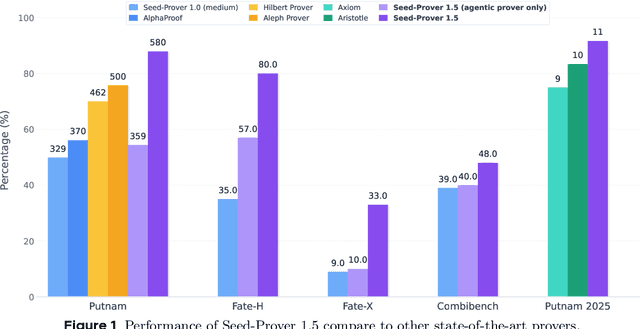

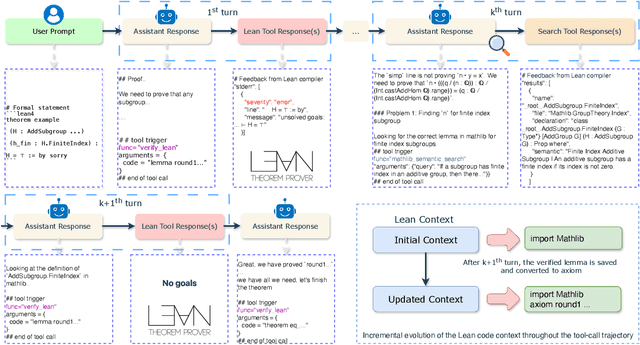

Large language models have recently made significant progress to generate rigorous mathematical proofs. In contrast, utilizing LLMs for theorem proving in formal languages (such as Lean) remains challenging and computationally expensive, particularly when addressing problems at the undergraduate level and beyond. In this work, we present \textbf{Seed-Prover 1.5}, a formal theorem-proving model trained via large-scale agentic reinforcement learning, alongside an efficient test-time scaling (TTS) workflow. Through extensive interactions with Lean and other tools, the model continuously accumulates experience during the RL process, substantially enhancing the capability and efficiency of formal theorem proving. Furthermore, leveraging recent advancements in natural language proving, our TTS workflow efficiently bridges the gap between natural and formal languages. Compared to state-of-the-art methods, Seed-Prover 1.5 achieves superior performance with a smaller compute budget. It solves \textbf{88\% of PutnamBench} (undergraduate-level), \textbf{80\% of Fate-H} (graduate-level), and \textbf{33\% of Fate-X} (PhD-level) problems. Notably, using our system, we solved \textbf{11 out of 12 problems} from Putnam 2025 within 9 hours. Our findings suggest that scaling learning from experience, driven by high-quality formal feedback, holds immense potential for the future of formal mathematical reasoning.
Seed-Prover: Deep and Broad Reasoning for Automated Theorem Proving
Aug 01, 2025LLMs have demonstrated strong mathematical reasoning abilities by leveraging reinforcement learning with long chain-of-thought, yet they continue to struggle with theorem proving due to the lack of clear supervision signals when solely using natural language. Dedicated domain-specific languages like Lean provide clear supervision via formal verification of proofs, enabling effective training through reinforcement learning. In this work, we propose \textbf{Seed-Prover}, a lemma-style whole-proof reasoning model. Seed-Prover can iteratively refine its proof based on Lean feedback, proved lemmas, and self-summarization. To solve IMO-level contest problems, we design three test-time inference strategies that enable both deep and broad reasoning. Seed-Prover proves $78.1\%$ of formalized past IMO problems, saturates MiniF2F, and achieves over 50\% on PutnamBench, outperforming the previous state-of-the-art by a large margin. To address the lack of geometry support in Lean, we introduce a geometry reasoning engine \textbf{Seed-Geometry}, which outperforms previous formal geometry engines. We use these two systems to participate in IMO 2025 and fully prove 5 out of 6 problems. This work represents a significant advancement in automated mathematical reasoning, demonstrating the effectiveness of formal verification with long chain-of-thought reasoning.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
Unveiling Downstream Performance Scaling of LLMs: A Clustering-Based Perspective
Feb 24, 2025The rapid advancements in computing dramatically increase the scale and cost of training Large Language Models (LLMs). Accurately predicting downstream task performance prior to model training is crucial for efficient resource allocation, yet remains challenging due to two primary constraints: (1) the "emergence phenomenon", wherein downstream performance metrics become meaningful only after extensive training, which limits the ability to use smaller models for prediction; (2) Uneven task difficulty distributions and the absence of consistent scaling laws, resulting in substantial metric variability. Existing performance prediction methods suffer from limited accuracy and reliability, thereby impeding the assessment of potential LLM capabilities. To address these challenges, we propose a Clustering-On-Difficulty (COD) downstream performance prediction framework. COD first constructs a predictable support subset by clustering tasks based on difficulty features, strategically excluding non-emergent and non-scalable clusters. The scores on the selected subset serve as effective intermediate predictors of downstream performance on the full evaluation set. With theoretical support, we derive a mapping function that transforms performance metrics from the predictable subset to the full evaluation set, thereby ensuring accurate extrapolation of LLM downstream performance. The proposed method has been applied to predict performance scaling for a 70B LLM, providing actionable insights for training resource allocation and assisting in monitoring the training process. Notably, COD achieves remarkable predictive accuracy on the 70B LLM by leveraging an ensemble of small models, demonstrating an absolute mean deviation of 1.36% across eight important LLM evaluation benchmarks.
MAGA: MAssive Genre-Audience Reformulation to Pretraining Corpus Expansion
Feb 06, 2025



Despite the remarkable capabilities of large language models across various tasks, their continued scaling faces a critical challenge: the scarcity of high-quality pretraining data. While model architectures continue to evolve, the natural language data struggles to scale up. To tackle this bottleneck, we propose \textbf{MA}ssive \textbf{G}enre-\textbf{A}udience~(MAGA) reformulation method, which systematic synthesizes diverse, contextually-rich pretraining data from existing corpus. This work makes three main contributions: (1) We propose MAGA reformulation method, a lightweight and scalable approach for pretraining corpus expansion, and build a 770B tokens MAGACorpus. (2) We evaluate MAGACorpus with different data budget scaling strategies, demonstrating consistent improvements across various model sizes (134M-13B), establishing the necessity for next-generation large-scale synthetic pretraining language models. (3) Through comprehensive analysis, we investigate prompt engineering's impact on synthetic training collapse and reveal limitations in conventional collapse detection metrics using validation losses. Our work shows that MAGA can substantially expand training datasets while maintaining quality, offering a reliably pathway for scaling models beyond data limitations.