 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiPACE: Bisimulation-Guided Policy Optimization with Action Counterfactual Estimation for LLM Agents
Jun 24, 2026Stepwise group-based RL is an attractive way to train long-horizon LLM agents without a learned critic: it reuses multiple sampled rollouts to estimate local advantages. Its weakness is less visible but more fundamental: every group-relative estimator assumes that the steps it compares are equivalent for credit assignment. We show that current agentic variants violate this assumption through a state-action credit mismatch. The observation-hash partition is overly fine on the state side, creating singleton groups with zero step-level signal, while a single within-group mean is too coarse on the action side, mixing state-value estimation with action-specific credit. We introduce BiPACE (Bisimulation-Guided Policy Optimization with Action Counterfactual Estimation), a drop-in advantage estimator that fixes both sides without adding a critic, auxiliary loss, or extra rollouts. BiGPO clusters steps by cosine distance in the actor's own hidden-state geometry, an empirical policy-induced proxy for bisimulation that substantially lowers the singleton rate left by observation hashing. PACE then recenters returns within each behavioral cluster using action-conditioned peer baselines; its Q-style instance estimates a local Q(s,a)-V(s) nonparametrically. On ALFWorld/Qwen2.5-7B, BiPACE_Q raises overall validation success from GiGPO's 90.8 to $97.1\pm0.9$ over three seeds, and crosses the 95% threshold on every seed, which GiGPO never does within the same budget. On Qwen2.5-1.5B it reaches $93.5\pm1.2$ versus GiGPO's 86.7, and on WebShop and TextCraft it improves over GRPO and GiGPO at both model scales. The measured BiPACE-specific overhead is 11.3% of a single training-step wall time. Yet it changes the estimator's comparison unit from surface identity to approximate behavioral equivalence plus action-side counterfactuals. The code is available at https://github.com/TianxiangZhao/BiPACE.
MBench: A Comprehensive Benchmark on Memory Capability for Video World Models
May 30, 2026Recent advancements in video-based world models have demonstrated an unprecedented ability to synthesize high-fidelity visual sequences. However, a fundamental gap persists between visually plausible video generation and the functional requirements of a world model, particularly in maintaining a stable and reasonable internal state over extended temporal horizons. While existing benchmarks primarily emphasize visual quality, motion coherence, and text-video alignment, they largely overlook memory, the core capability of a world model to preserve consistency across long-term horizons and complex interactions. To address this gap, we present \textbf{MBench}, a comprehensive benchmark dedicated to quantifying and evaluating the memory capability of video world models. We systematically decompose the memory capability of video world models into three hierarchical and complementary core dimensions: entity consistency, environment consistency, and causal consistency, which are further refined into 12 quantifiable sub-dimensions for comprehensive characterization of long-term memory. Our benchmark is built upon rigorously curated real-captured long videos, and evaluated by rule-based quantitative matrices and VLM to enable objective and comprehensive consistency assessment. Extensive evaluations of mainstream state-of-the-art video world models reveal critical systemic limitations of existing methods in long-term state retention, providing a standardized benchmark and clear research direction to advance the field.
DeMaVLA: A Vision-Language-Action Foundation Model for Generalizable Deformable Manipulation
May 29, 2026Real-world household robots require Vision-Language-Action (VLA) foundation models that can acquire reusable manipulation skills across diverse objects, task conditions, and household environments. Deformable-object folding is a representative challenge, requiring robots to handle clothing items from random initial states across varying categories, geometries, materials, and scenes. However, existing VLA systems commonly train separate policies for different object categories, while naively mixed multi-task training often suffers from task interference and degraded performance. To move beyond category-specific folding policies, we introduce DeMaVLA, a VLA foundation model for generalizable Deformable Manipulation. DeMaVLA adopts a VLM backbone with an action expert and formulates continuous action generation using flow matching. To improve efficiency, the action expert is constructed by pruning every other transformer layer while preserving layer-wise alignment with the VLM backbone, reducing training and inference cost. DeMaVLA is first pre-trained on approximately 5,000 hours of selected real-world dual-arm demonstrations to acquire general manipulation priors. It is then post-trained on mixed folding data that aggregates self-collected demonstrations and corrective trajectories from real-robot failures across multiple folding tasks through a human-in-the-loop Data Aggregation~(DAgger) pipeline. Experiments show that DeMaVLA achieves competitive performance on RoboTwin and strong real-world results on our household folding benchmark. These results highlight the value of scalable real-world data, efficient action generation, and corrective learning for general-purpose VLA policies in deformable-object manipulation.
The Detection-Extraction Gap: Models Know the Answer Before They Can Say It
Apr 09, 2026Modern reasoning models continue generating long after the answer is already determined. Across five model configurations, two families, and three benchmarks, we find that 52--88% of chain-of-thought tokens are produced after the answer is recoverable from a partial prefix. This post-commitment generation reveals a structural phenomenon: the detection-extraction gap. Free continuations from early prefixes recover the correct answer even at 10% of the trace, while forced extraction fails on 42% of these cases. The answer is recoverable from the model state, yet prompt-conditioned decoding fails to extract it. We formalize this mismatch via a total-variation bound between free and forced continuation distributions, yielding quantitative estimates of suffix-induced shift. Exploiting this asymmetry, we propose Black-box Adaptive Early Exit (BAEE), which uses free continuations for both detection and extraction, truncating 70--78% of serial generation while improving accuracy by 1--5pp across all models. For thinking-mode models, early exit prevents post-commitment overwriting, yielding gains of up to 5.8pp; a cost-optimized variant achieves 68--73% reduction at a median of 9 API calls. Code is available at https://github.com/EdWangLoDaSc/know2say.
CFG-Ctrl: Control-Based Classifier-Free Diffusion Guidance
Mar 03, 2026Classifier-Free Guidance (CFG) has emerged as a central approach for enhancing semantic alignment in flow-based diffusion models. In this paper, we explore a unified framework called CFG-Ctrl, which reinterprets CFG as a control applied to the first-order continuous-time generative flow, using the conditional-unconditional discrepancy as an error signal to adjust the velocity field. From this perspective, we summarize vanilla CFG as a proportional controller (P-control) with fixed gain, and typical follow-up variants develop extended control-law designs derived from it. However, existing methods mainly rely on linear control, inherently leading to instability, overshooting, and degraded semantic fidelity especially on large guidance scales. To address this, we introduce Sliding Mode Control CFG (SMC-CFG), which enforces the generative flow toward a rapidly convergent sliding manifold. Specifically, we define an exponential sliding mode surface over the semantic prediction error and introduce a switching control term to establish nonlinear feedback-guided correction. Moreover, we provide a Lyapunov stability analysis to theoretically support finite-time convergence. Experiments across text-to-image generation models including Stable Diffusion 3.5, Flux, and Qwen-Image demonstrate that SMC-CFG outperforms standard CFG in semantic alignment and enhances robustness across a wide range of guidance scales. Project Page: https://hanyang-21.github.io/CFG-Ctrl
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Feb 09, 2026Large Language Model (LLM) agents have shown stunning results in complex tasks, yet they often operate in isolation, failing to learn from past experiences. Existing memory-based methods primarily store raw trajectories, which are often redundant and noise-heavy. This prevents agents from extracting high-level, reusable behavioral patterns that are essential for generalization. In this paper, we propose SkillRL, a framework that bridges the gap between raw experience and policy improvement through automatic skill discovery and recursive evolution. Our approach introduces an experience-based distillation mechanism to build a hierarchical skill library SkillBank, an adaptive retrieval strategy for general and task-specific heuristics, and a recursive evolution mechanism that allows the skill library to co-evolve with the agent's policy during reinforcement learning. These innovations significantly reduce the token footprint while enhancing reasoning utility. Experimental results on ALFWorld, WebShop and seven search-augmented tasks demonstrate that SkillRL achieves state-of-the-art performance, outperforming strong baselines over 15.3% and maintaining robustness as task complexity increases. Code is available at this https://github.com/aiming-lab/SkillRL.
Unsupervised Multi-Attention Meta Transformer for Rotating Machinery Fault Diagnosis
Sep 11, 2025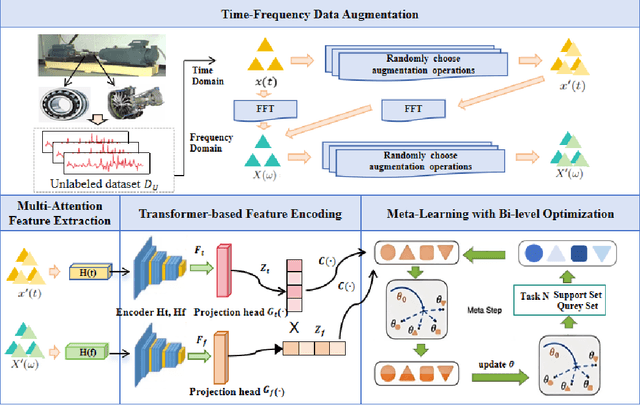

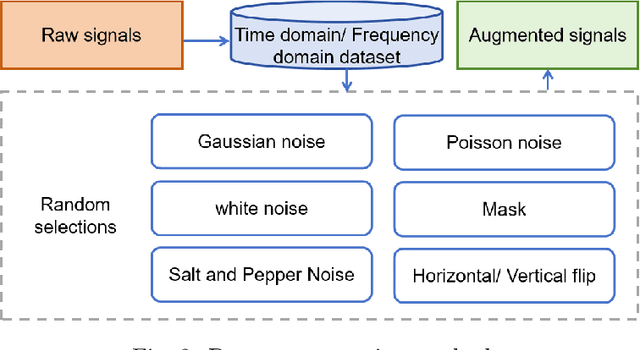
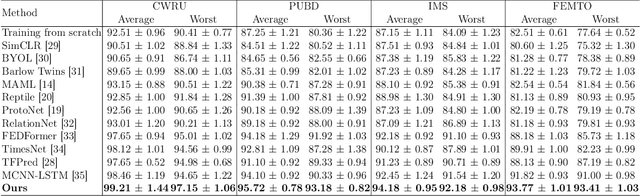
The intelligent fault diagnosis of rotating mechanical equipment usually requires a large amount of labeled sample data. However, in practical industrial applications, acquiring enough data is both challenging and expensive in terms of time and cost. Moreover, different types of rotating mechanical equipment with different unique mechanical properties, require separate training of diagnostic models for each case. To address the challenges of limited fault samples and the lack of generalizability in prediction models for practical engineering applications, we propose a Multi-Attention Meta Transformer method for few-shot unsupervised rotating machinery fault diagnosis (MMT-FD). This framework extracts potential fault representations from unlabeled data and demonstrates strong generalization capabilities, making it suitable for diagnosing faults across various types of mechanical equipment. The MMT-FD framework integrates a time-frequency domain encoder and a meta-learning generalization model. The time-frequency domain encoder predicts status representations generated through random augmentations in the time-frequency domain. These enhanced data are then fed into a meta-learning network for classification and generalization training, followed by fine-tuning using a limited amount of labeled data. The model is iteratively optimized using a small number of contrastive learning iterations, resulting in high efficiency. To validate the framework, we conducted experiments on a bearing fault dataset and rotor test bench data. The results demonstrate that the MMT-FD model achieves 99\% fault diagnosis accuracy with only 1\% of labeled sample data, exhibiting robust generalization capabilities.
LangScene-X: Reconstruct Generalizable 3D Language-Embedded Scenes with TriMap Video Diffusion
Jul 03, 2025



Recovering 3D structures with open-vocabulary scene understanding from 2D images is a fundamental but daunting task. Recent developments have achieved this by performing per-scene optimization with embedded language information. However, they heavily rely on the calibrated dense-view reconstruction paradigm, thereby suffering from severe rendering artifacts and implausible semantic synthesis when limited views are available. In this paper, we introduce a novel generative framework, coined LangScene-X, to unify and generate 3D consistent multi-modality information for reconstruction and understanding. Powered by the generative capability of creating more consistent novel observations, we can build generalizable 3D language-embedded scenes from only sparse views. Specifically, we first train a TriMap video diffusion model that can generate appearance (RGBs), geometry (normals), and semantics (segmentation maps) from sparse inputs through progressive knowledge integration. Furthermore, we propose a Language Quantized Compressor (LQC), trained on large-scale image datasets, to efficiently encode language embeddings, enabling cross-scene generalization without per-scene retraining. Finally, we reconstruct the language surface fields by aligning language information onto the surface of 3D scenes, enabling open-ended language queries. Extensive experiments on real-world data demonstrate the superiority of our LangScene-X over state-of-the-art methods in terms of quality and generalizability. Project Page: https://liuff19.github.io/LangScene-X.
Text2Grad: Reinforcement Learning from Natural Language Feedback
May 28, 2025Traditional RLHF optimizes language models with coarse, scalar rewards that mask the fine-grained reasons behind success or failure, leading to slow and opaque learning. Recent work augments RL with textual critiques through prompting or reflection, improving interpretability but leaving model parameters untouched. We introduce Text2Grad, a reinforcement-learning paradigm that turns free-form textual feedback into span-level gradients. Given human (or programmatic) critiques, Text2Grad aligns each feedback phrase with the relevant token spans, converts these alignments into differentiable reward signals, and performs gradient updates that directly refine the offending portions of the model's policy. This yields precise, feedback-conditioned adjustments instead of global nudges. Text2Grad is realized through three components: (1) a high-quality feedback-annotation pipeline that pairs critiques with token spans; (2) a fine-grained reward model that predicts span-level reward on answer while generating explanatory critiques; and (3) a span-level policy optimizer that back-propagates natural-language gradients. Across summarization, code generation, and question answering, Text2Grad consistently surpasses scalar-reward RL and prompt-only baselines, providing both higher task metrics and richer interpretability. Our results demonstrate that natural-language feedback, when converted to gradients, is a powerful signal for fine-grained policy optimization. The code for our method is available at https://github.com/microsoft/Text2Grad
VideoScene: Distilling Video Diffusion Model to Generate 3D Scenes in One Step
Apr 03, 2025



Recovering 3D scenes from sparse views is a challenging task due to its inherent ill-posed problem. Conventional methods have developed specialized solutions (e.g., geometry regularization or feed-forward deterministic model) to mitigate the issue. However, they still suffer from performance degradation by minimal overlap across input views with insufficient visual information. Fortunately, recent video generative models show promise in addressing this challenge as they are capable of generating video clips with plausible 3D structures. Powered by large pretrained video diffusion models, some pioneering research start to explore the potential of video generative prior and create 3D scenes from sparse views. Despite impressive improvements, they are limited by slow inference time and the lack of 3D constraint, leading to inefficiencies and reconstruction artifacts that do not align with real-world geometry structure. In this paper, we propose VideoScene to distill the video diffusion model to generate 3D scenes in one step, aiming to build an efficient and effective tool to bridge the gap from video to 3D. Specifically, we design a 3D-aware leap flow distillation strategy to leap over time-consuming redundant information and train a dynamic denoising policy network to adaptively determine the optimal leap timestep during inference. Extensive experiments demonstrate that our VideoScene achieves faster and superior 3D scene generation results than previous video diffusion models, highlighting its potential as an efficient tool for future video to 3D applications. Project Page: https://hanyang-21.github.io/VideoScene