 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIVE: Scaling Diversity in Agentic Task Synthesis for Generalizable Tool Use
Mar 10, 2026Recent work synthesizes agentic tasks for post-training tool-using LLMs, yet robust generalization under shifts in tasks and toolsets remains an open challenge. We trace this brittleness to insufficient diversity in synthesized tasks. Scaling diversity is difficult because training requires tasks to remain executable and verifiable, while generalization demands coverage of diverse tool types, toolset combinations, and heterogeneous tool-use patterns. We propose DIVE, an evidence-driven recipe that inverts synthesis order, executing diverse, real-world tools first and reverse-deriving tasks strictly entailed by the resulting traces, thereby providing grounding by construction. DIVE scales structural diversity along two controllable axes, tool-pool coverage and per-task toolset variety, and an Evidence Collection--Task Derivation loop further induces rich multi-step tool-use patterns across 373 tools in five domains. Training Qwen3-8B on DIVE data (48k SFT + 3.2k RL) improves by +22 average points across 9 OOD benchmarks and outperforms the strongest 8B baseline by +68. Remarkably, controlled scaling analysis reveals that diversity scaling consistently outperforms quantity scaling for OOD generalization, even with 4x less data.
Seed-Prover 1.5: Mastering Undergraduate-Level Theorem Proving via Learning from Experience
Dec 19, 2025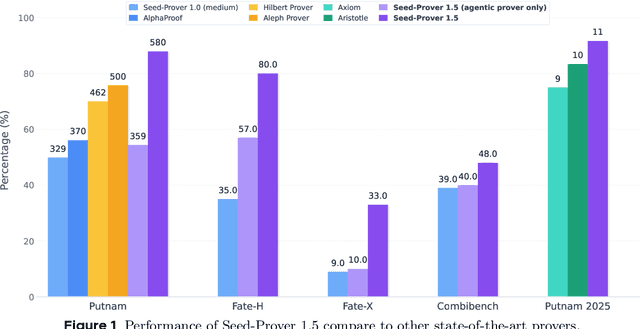

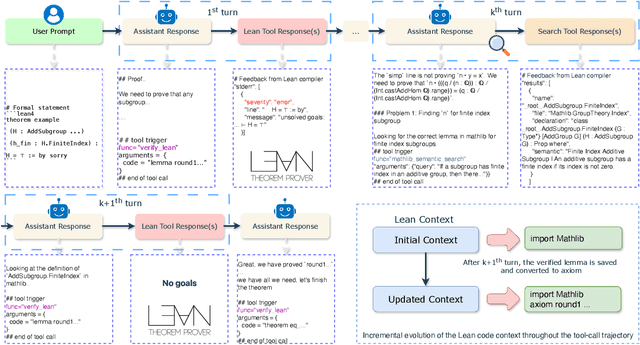

Large language models have recently made significant progress to generate rigorous mathematical proofs. In contrast, utilizing LLMs for theorem proving in formal languages (such as Lean) remains challenging and computationally expensive, particularly when addressing problems at the undergraduate level and beyond. In this work, we present \textbf{Seed-Prover 1.5}, a formal theorem-proving model trained via large-scale agentic reinforcement learning, alongside an efficient test-time scaling (TTS) workflow. Through extensive interactions with Lean and other tools, the model continuously accumulates experience during the RL process, substantially enhancing the capability and efficiency of formal theorem proving. Furthermore, leveraging recent advancements in natural language proving, our TTS workflow efficiently bridges the gap between natural and formal languages. Compared to state-of-the-art methods, Seed-Prover 1.5 achieves superior performance with a smaller compute budget. It solves \textbf{88\% of PutnamBench} (undergraduate-level), \textbf{80\% of Fate-H} (graduate-level), and \textbf{33\% of Fate-X} (PhD-level) problems. Notably, using our system, we solved \textbf{11 out of 12 problems} from Putnam 2025 within 9 hours. Our findings suggest that scaling learning from experience, driven by high-quality formal feedback, holds immense potential for the future of formal mathematical reasoning.
FLEX: Continuous Agent Evolution via Forward Learning from Experience
Nov 09, 2025Autonomous agents driven by Large Language Models (LLMs) have revolutionized reasoning and problem-solving but remain static after training, unable to grow with experience as intelligent beings do during deployment. We introduce Forward Learning with EXperience (FLEX), a gradient-free learning paradigm that enables LLM agents to continuously evolve through accumulated experience. Specifically, FLEX cultivates scalable and inheritable evolution by constructing a structured experience library through continual reflection on successes and failures during interaction with the environment. FLEX delivers substantial improvements on mathematical reasoning, chemical retrosynthesis, and protein fitness prediction (up to 23% on AIME25, 10% on USPTO50k, and 14% on ProteinGym). We further identify a clear scaling law of experiential growth and the phenomenon of experience inheritance across agents, marking a step toward scalable and inheritable continuous agent evolution. Project Page: https://flex-gensi-thuair.github.io.
Curse of Knowledge: When Complex Evaluation Context Benefits yet Biases LLM Judges
Sep 03, 2025As large language models (LLMs) grow more capable, they face increasingly diverse and complex tasks, making reliable evaluation challenging. The paradigm of LLMs as judges has emerged as a scalable solution, yet prior work primarily focuses on simple settings. Their reliability in complex tasks--where multi-faceted rubrics, unstructured reference answers, and nuanced criteria are critical--remains understudied. In this paper, we constructed ComplexEval, a challenge benchmark designed to systematically expose and quantify Auxiliary Information Induced Biases. We systematically investigated and validated 6 previously unexplored biases across 12 basic and 3 advanced scenarios. Key findings reveal: (1) all evaluated models exhibit significant susceptibility to these biases, with bias magnitude scaling with task complexity; (2) notably, Large Reasoning Models (LRMs) show paradoxical vulnerability. Our in-depth analysis offers crucial insights for improving the accuracy and verifiability of evaluation signals, paving the way for more general and robust evaluation models.
ThinkDial: An Open Recipe for Controlling Reasoning Effort in Large Language Models
Aug 26, 2025



Large language models (LLMs) with chain-of-thought reasoning have demonstrated remarkable problem-solving capabilities, but controlling their computational effort remains a significant challenge for practical deployment. Recent proprietary systems like OpenAI's gpt-oss series have introduced discrete operational modes for intuitive reasoning control, but the open-source community has largely failed to achieve such capabilities. In this paper, we introduce ThinkDial, the first open-recipe end-to-end framework that successfully implements gpt-oss-style controllable reasoning through discrete operational modes. Our system enables seamless switching between three distinct reasoning regimes: High mode (full reasoning capability), Medium mode (50 percent token reduction with <10 percent performance degradation), and Low mode (75 percent token reduction with <15 percent performance degradation). We achieve this through an end-to-end training paradigm that integrates budget-mode control throughout the entire pipeline: budget-mode supervised fine-tuning that embeds controllable reasoning capabilities directly into the learning process, and two-phase budget-aware reinforcement learning with adaptive reward shaping. Extensive experiments demonstrate that ThinkDial achieves target compression-performance trade-offs with clear response length reductions while maintaining performance thresholds. The framework also exhibits strong generalization capabilities on out-of-distribution tasks.
MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent
Jul 03, 2025



Despite improvements by length extrapolation, efficient attention and memory modules, handling infinitely long documents with linear complexity without performance degradation during extrapolation remains the ultimate challenge in long-text processing. We directly optimize for long-text tasks in an end-to-end fashion and introduce a novel agent workflow, MemAgent, which reads text in segments and updates the memory using an overwrite strategy. We extend the DAPO algorithm to facilitate training via independent-context multi-conversation generation. MemAgent has demonstrated superb long-context capabilities, being able to extrapolate from an 8K context trained on 32K text to a 3.5M QA task with performance loss < 5% and achieves 95%+ in 512K RULER test.
Can LLMs Learn to Map the World from Local Descriptions?
May 27, 2025Recent advances in Large Language Models (LLMs) have demonstrated strong capabilities in tasks such as code and mathematics. However, their potential to internalize structured spatial knowledge remains underexplored. This study investigates whether LLMs, grounded in locally relative human observations, can construct coherent global spatial cognition by integrating fragmented relational descriptions. We focus on two core aspects of spatial cognition: spatial perception, where models infer consistent global layouts from local positional relationships, and spatial navigation, where models learn road connectivity from trajectory data and plan optimal paths between unconnected locations. Experiments conducted in a simulated urban environment demonstrate that LLMs not only generalize to unseen spatial relationships between points of interest (POIs) but also exhibit latent representations aligned with real-world spatial distributions. Furthermore, LLMs can learn road connectivity from trajectory descriptions, enabling accurate path planning and dynamic spatial awareness during navigation.
Enigmata: Scaling Logical Reasoning in Large Language Models with Synthetic Verifiable Puzzles
May 26, 2025



Large Language Models (LLMs), such as OpenAI's o1 and DeepSeek's R1, excel at advanced reasoning tasks like math and coding via Reinforcement Learning with Verifiable Rewards (RLVR), but still struggle with puzzles solvable by humans without domain knowledge. We introduce Enigmata, the first comprehensive suite tailored for improving LLMs with puzzle reasoning skills. It includes 36 tasks across seven categories, each with 1) a generator that produces unlimited examples with controllable difficulty and 2) a rule-based verifier for automatic evaluation. This generator-verifier design supports scalable, multi-task RL training, fine-grained analysis, and seamless RLVR integration. We further propose Enigmata-Eval, a rigorous benchmark, and develop optimized multi-task RLVR strategies. Our trained model, Qwen2.5-32B-Enigmata, consistently surpasses o3-mini-high and o1 on the puzzle reasoning benchmarks like Enigmata-Eval, ARC-AGI (32.8%), and ARC-AGI 2 (0.6%). It also generalizes well to out-of-domain puzzle benchmarks and mathematical reasoning, with little multi-tasking trade-off. When trained on larger models like Seed1.5-Thinking (20B activated parameters and 200B total parameters), puzzle data from Enigmata further boosts SoTA performance on advanced math and STEM reasoning tasks such as AIME (2024-2025), BeyondAIME and GPQA (Diamond), showing nice generalization benefits of Enigmata. This work offers a unified, controllable framework for advancing logical reasoning in LLMs. Resources of this work can be found at https://seed-enigmata.github.io.
KORGym: A Dynamic Game Platform for LLM Reasoning Evaluation
May 21, 2025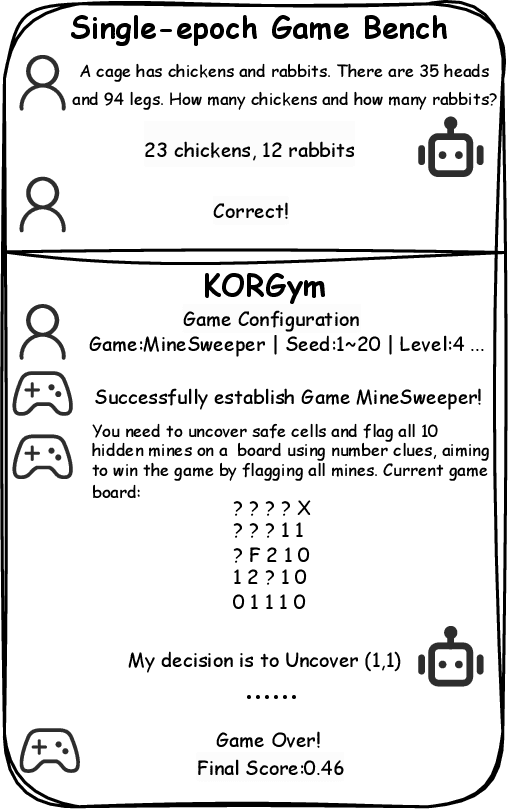
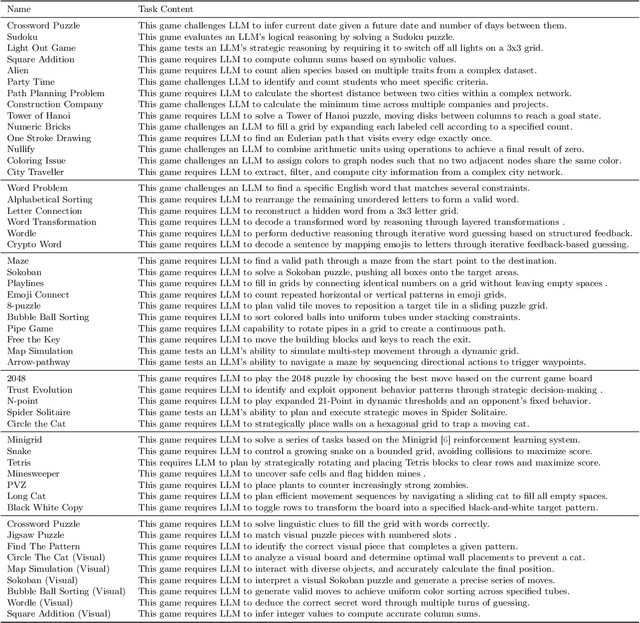
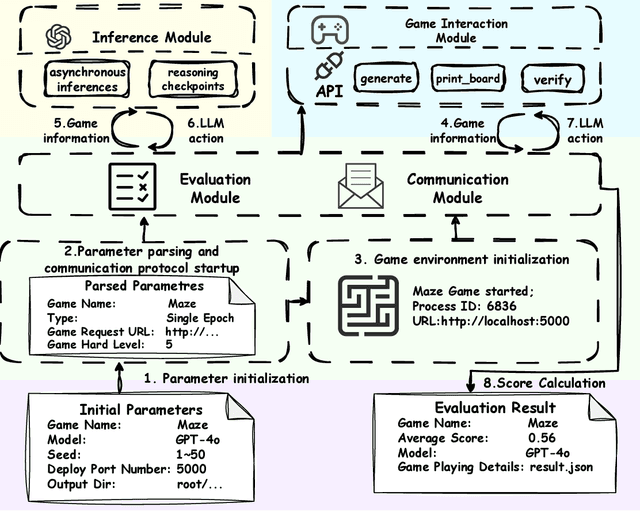

Recent advancements in large language models (LLMs) underscore the need for more comprehensive evaluation methods to accurately assess their reasoning capabilities. Existing benchmarks are often domain-specific and thus cannot fully capture an LLM's general reasoning potential. To address this limitation, we introduce the Knowledge Orthogonal Reasoning Gymnasium (KORGym), a dynamic evaluation platform inspired by KOR-Bench and Gymnasium. KORGym offers over fifty games in either textual or visual formats and supports interactive, multi-turn assessments with reinforcement learning scenarios. Using KORGym, we conduct extensive experiments on 19 LLMs and 8 VLMs, revealing consistent reasoning patterns within model families and demonstrating the superior performance of closed-source models. Further analysis examines the effects of modality, reasoning strategies, reinforcement learning techniques, and response length on model performance. We expect KORGym to become a valuable resource for advancing LLM reasoning research and developing evaluation methodologies suited to complex, interactive environments.
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Mar 18, 2025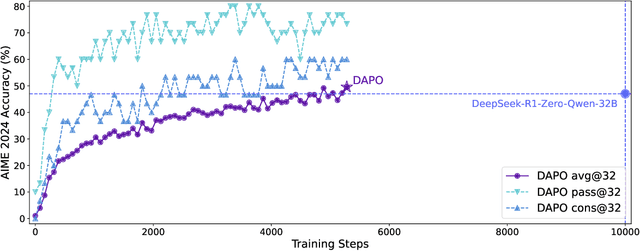

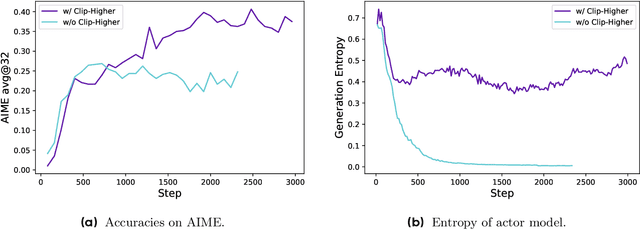

Inference scaling empowers LLMs with unprecedented reasoning ability, with reinforcement learning as the core technique to elicit complex reasoning. However, key technical details of state-of-the-art reasoning LLMs are concealed (such as in OpenAI o1 blog and DeepSeek R1 technical report), thus the community still struggles to reproduce their RL training results. We propose the $\textbf{D}$ecoupled Clip and $\textbf{D}$ynamic s$\textbf{A}$mpling $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{DAPO}$) algorithm, and fully open-source a state-of-the-art large-scale RL system that achieves 50 points on AIME 2024 using Qwen2.5-32B base model. Unlike previous works that withhold training details, we introduce four key techniques of our algorithm that make large-scale LLM RL a success. In addition, we open-source our training code, which is built on the verl framework, along with a carefully curated and processed dataset. These components of our open-source system enhance reproducibility and support future research in large-scale LLM RL.