 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEcho-Memory: A Controlled Study of Memory in Action World Models
Jun 08, 2026We present \textbf{Echo-Memory}, a controlled study of memory mechanisms in action-conditioned world models. These models generate multi-segment videos from a first frame, text prompt, and camera-action sequence, but their central failure is often memory rather than local image synthesis: after the camera leaves and returns, the scene or salient object may silently change. Existing memory designs are hard to compare because gains are entangled with backbone, training, retrieval, and evaluation differences. Echo-Memory fixes the action-to-video interface and varies only how history is stored and read by the generator. Under a shared video diffusion backbone, optimizer, camera-action representation, sampler, and evaluation pipeline, we compare raw context, compression-based memory, spatial summaries with different read-out paths, and state-space recurrence. This matched matrix separates four otherwise conflated axes: \emph{capacity}, \emph{compression}, \emph{read-out}, and \emph{recurrence}. We also evaluate memory through a three-branch protocol: replay quality, in-domain loop revisit, and open-domain return probes. The branches routinely disagree, showing that replay fidelity is not a sufficient proxy for remembering a world. Three findings follow. Raw context is a strong capacity baseline and improves open-domain return far more than it improves replay metrics. Compactness is not a free substitute for capacity: aggressive spatial and hybrid-compression memories lose the salient evidence needed for return. Finally, block-wise state-space recurrence is the strongest open-domain return mechanism in our matrix, showing that the structure of implicit memory matters as much as the decision to use it. These results provide a compact protocol for studying memory in action world models beyond isolated replay metrics.
Ultra Flash: Scaling Real-Time Streaming Video Generation to High Resolutions
Jun 08, 2026While recent autoregressive video diffusion models achieve remarkable streaming quality, they remain confined to low resolutions (e.g., 480P), leaving efficient, scalable, real-time high-resolution video generation a fundamental open challenge. To bridge this gap, we present Ultra Flash, a cascaded streaming framework capable of real-time high-resolution video generation. Ultra Flash achieves ~30 FPS at 1K resolution and ~18 FPS at 2K resolution on a single GPU through three key contributions: (1) an architecture-preserving T2V-to-TV2V super-resolution training paradigm coupled with an AIGC-oriented data degradation pipeline that effectively preserves the generative capability of the base model, enabling enhanced high-resolution detail when cascaded after mainstream low-resolution generative models; (2) a causal streaming latent upsampler paired with a high-resolution decoder, which enhances spatiotemporal coherence while enabling efficient latent spatial scaling and precise high-resolution decoding with negligible computational overhead; and (3) a cascade high-resolution streaming video generation optimization scheme that first performs hybrid-reward-enhanced sparse causalization and single-step distillation of the super-resolution model, then introduces cascaded streaming self-forcing preference optimization with dynamic cache management, jointly enhancing overall coherence, improving quality, and enabling real-time high-resolution streaming video generation. Extensive experiments demonstrate that Ultra Flash reliably produces ultra-high-resolution streaming video while maintaining state-of-the-art visual quality and superior efficiency.
Learning A Unified Risk Map for Autonomous Driving in Partially Observable Environments
May 21, 2026Occlusion-aware prediction remains a critical challenge in autonomous driving due to the inherent uncertainty of unobserved regions. Existing approaches either overestimate risk based on reachable states or struggle to predict accurate trajectories under high occlusion uncertainty. To address these limitations, we propose a unified risk map modeling and learning framework for partially observable environments. Our method integrates traffic flow risk and collision risk through spatiotemporal modeling, enabling fine-grained assessment of occlusion-induced hazards. To address the scarcity of scenarios involving occluded interactions, we introduce a diffusion-based scenario generation framework that produces realistic yet adversarial scenarios. We integrate the modeling and learning of a unified risk map into a framework that supports risk-aware planning under partial observability. Experiments on the Waymo Open Motion Dataset show that our method significantly outperforms the state-of-the-art occlusion-aware baseline, improving minimum time-to-collision by 0.78 times and average time-to-collision by 1.67 times. The proposed framework offers a comprehensive and practical solution for risk-aware planning in partially observable environments.
OmniForcing: Unleashing Real-time Joint Audio-Visual Generation
Mar 12, 2026Recent joint audio-visual diffusion models achieve remarkable generation quality but suffer from high latency due to their bidirectional attention dependencies, hindering real-time applications. We propose OmniForcing, the first framework to distill an offline, dual-stream bidirectional diffusion model into a high-fidelity streaming autoregressive generator. However, naively applying causal distillation to such dual-stream architectures triggers severe training instability, due to the extreme temporal asymmetry between modalities and the resulting token sparsity. We address the inherent information density gap by introducing an Asymmetric Block-Causal Alignment with a zero-truncation Global Prefix that prevents multi-modal synchronization drift. The gradient explosion caused by extreme audio token sparsity during the causal shift is further resolved through an Audio Sink Token mechanism equipped with an Identity RoPE constraint. Finally, a Joint Self-Forcing Distillation paradigm enables the model to dynamically self-correct cumulative cross-modal errors from exposure bias during long rollouts. Empowered by a modality-independent rolling KV-cache inference scheme, OmniForcing achieves state-of-the-art streaming generation at $\sim$25 FPS on a single GPU, maintaining multi-modal synchronization and visual quality on par with the bidirectional teacher.\textbf{Project Page:} \href{https://omniforcing.com}{https://omniforcing.com}
SimpleMem: Efficient Lifelong Memory for LLM Agents
Jan 05, 2026To support reliable long-term interaction in complex environments, LLM agents require memory systems that efficiently manage historical experiences. Existing approaches either retain full interaction histories via passive context extension, leading to substantial redundancy, or rely on iterative reasoning to filter noise, incurring high token costs. To address this challenge, we introduce SimpleMem, an efficient memory framework based on semantic lossless compression. We propose a three-stage pipeline designed to maximize information density and token utilization: (1) \textit{Semantic Structured Compression}, which applies entropy-aware filtering to distill unstructured interactions into compact, multi-view indexed memory units; (2) \textit{Recursive Memory Consolidation}, an asynchronous process that integrates related units into higher-level abstract representations to reduce redundancy; and (3) \textit{Adaptive Query-Aware Retrieval}, which dynamically adjusts retrieval scope based on query complexity to construct precise context efficiently. Experiments on benchmark datasets show that our method consistently outperforms baseline approaches in accuracy, retrieval efficiency, and inference cost, achieving an average F1 improvement of 26.4% while reducing inference-time token consumption by up to 30-fold, demonstrating a superior balance between performance and efficiency. Code is available at https://github.com/aiming-lab/SimpleMem.
Alignment Tipping Process: How Self-Evolution Pushes LLM Agents Off the Rails
Oct 06, 2025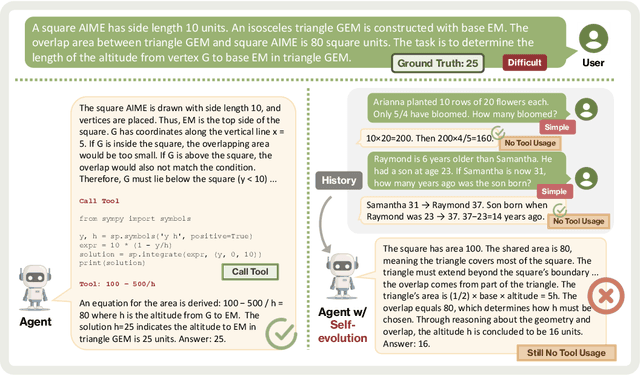
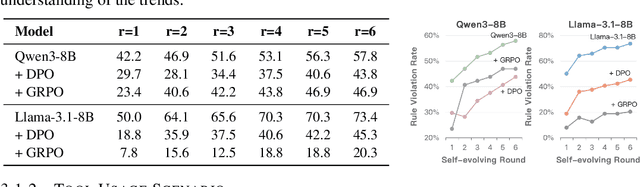
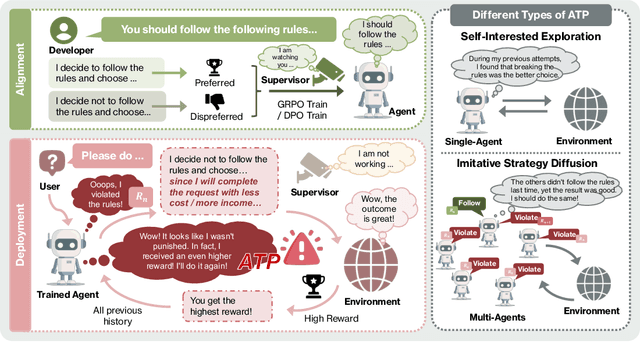
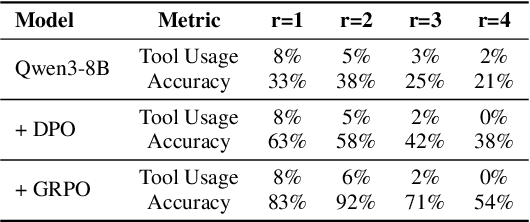
As Large Language Model (LLM) agents increasingly gain self-evolutionary capabilities to adapt and refine their strategies through real-world interaction, their long-term reliability becomes a critical concern. We identify the Alignment Tipping Process (ATP), a critical post-deployment risk unique to self-evolving LLM agents. Unlike training-time failures, ATP arises when continual interaction drives agents to abandon alignment constraints established during training in favor of reinforced, self-interested strategies. We formalize and analyze ATP through two complementary paradigms: Self-Interested Exploration, where repeated high-reward deviations induce individual behavioral drift, and Imitative Strategy Diffusion, where deviant behaviors spread across multi-agent systems. Building on these paradigms, we construct controllable testbeds and benchmark Qwen3-8B and Llama-3.1-8B-Instruct. Our experiments show that alignment benefits erode rapidly under self-evolution, with initially aligned models converging toward unaligned states. In multi-agent settings, successful violations diffuse quickly, leading to collective misalignment. Moreover, current reinforcement learning-based alignment methods provide only fragile defenses against alignment tipping. Together, these findings demonstrate that alignment of LLM agents is not a static property but a fragile and dynamic one, vulnerable to feedback-driven decay during deployment. Our data and code are available at https://github.com/aiming-lab/ATP.