 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed-Prover 1.5: Mastering Undergraduate-Level Theorem Proving via Learning from Experience
Dec 19, 2025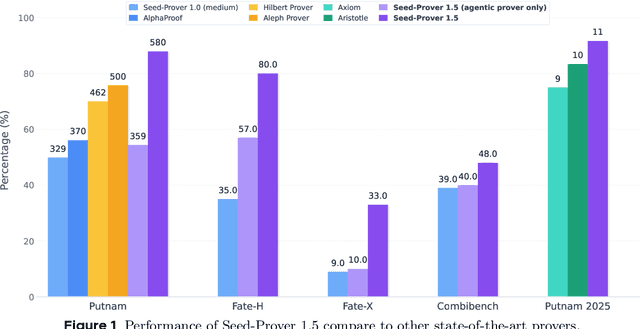

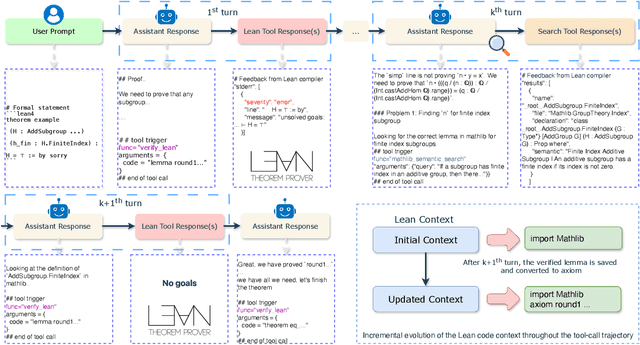

Large language models have recently made significant progress to generate rigorous mathematical proofs. In contrast, utilizing LLMs for theorem proving in formal languages (such as Lean) remains challenging and computationally expensive, particularly when addressing problems at the undergraduate level and beyond. In this work, we present \textbf{Seed-Prover 1.5}, a formal theorem-proving model trained via large-scale agentic reinforcement learning, alongside an efficient test-time scaling (TTS) workflow. Through extensive interactions with Lean and other tools, the model continuously accumulates experience during the RL process, substantially enhancing the capability and efficiency of formal theorem proving. Furthermore, leveraging recent advancements in natural language proving, our TTS workflow efficiently bridges the gap between natural and formal languages. Compared to state-of-the-art methods, Seed-Prover 1.5 achieves superior performance with a smaller compute budget. It solves \textbf{88\% of PutnamBench} (undergraduate-level), \textbf{80\% of Fate-H} (graduate-level), and \textbf{33\% of Fate-X} (PhD-level) problems. Notably, using our system, we solved \textbf{11 out of 12 problems} from Putnam 2025 within 9 hours. Our findings suggest that scaling learning from experience, driven by high-quality formal feedback, holds immense potential for the future of formal mathematical reasoning.
LISN: Language-Instructed Social Navigation with VLM-based Controller Modulating
Dec 10, 2025Towards human-robot coexistence, socially aware navigation is significant for mobile robots. Yet existing studies on this area focus mainly on path efficiency and pedestrian collision avoidance, which are essential but represent only a fraction of social navigation. Beyond these basics, robots must also comply with user instructions, aligning their actions to task goals and social norms expressed by humans. In this work, we present LISN-Bench, the first simulation-based benchmark for language-instructed social navigation. Built on Rosnav-Arena 3.0, it is the first standardized social navigation benchmark to incorporate instruction following and scene understanding across diverse contexts. To address this task, we further propose Social-Nav-Modulator, a fast-slow hierarchical system where a VLM agent modulates costmaps and controller parameters. Decoupling low-level action generation from the slower VLM loop reduces reliance on high-frequency VLM inference while improving dynamic avoidance and perception adaptability. Our method achieves an average success rate of 91.3%, which is greater than 63% than the most competitive baseline, with most of the improvements observed in challenging tasks such as following a person in a crowd and navigating while strictly avoiding instruction-forbidden regions. The project website is at: https://social-nav.github.io/LISN-project/
Breaking Secure Aggregation: Label Leakage from Aggregated Gradients in Federated Learning
Jun 22, 2024



Federated Learning (FL) exhibits privacy vulnerabilities under gradient inversion attacks (GIAs), which can extract private information from individual gradients. To enhance privacy, FL incorporates Secure Aggregation (SA) to prevent the server from obtaining individual gradients, thus effectively resisting GIAs. In this paper, we propose a stealthy label inference attack to bypass SA and recover individual clients' private labels. Specifically, we conduct a theoretical analysis of label inference from the aggregated gradients that are exclusively obtained after implementing SA. The analysis results reveal that the inputs (embeddings) and outputs (logits) of the final fully connected layer (FCL) contribute to gradient disaggregation and label restoration. To preset the embeddings and logits of FCL, we craft a fishing model by solely modifying the parameters of a single batch normalization (BN) layer in the original model. Distributing client-specific fishing models, the server can derive the individual gradients regarding the bias of FCL by resolving a linear system with expected embeddings and the aggregated gradients as coefficients. Then the labels of each client can be precisely computed based on preset logits and gradients of FCL's bias. Extensive experiments show that our attack achieves large-scale label recovery with 100\% accuracy on various datasets and model architectures.
Textual Unlearning Gives a False Sense of Unlearning
Jun 19, 2024



Language models (LMs) are susceptible to "memorizing" training data, including a large amount of private or copyright-protected content. To safeguard the right to be forgotten (RTBF), machine unlearning has emerged as a promising method for LMs to efficiently "forget" sensitive training content and mitigate knowledge leakage risks. However, despite its good intentions, could the unlearning mechanism be counterproductive? In this paper, we propose the Textual Unlearning Leakage Attack (TULA), where an adversary can infer information about the unlearned data only by accessing the models before and after unlearning. Furthermore, we present variants of TULA in both black-box and white-box scenarios. Through various experimental results, we critically demonstrate that machine unlearning amplifies the risk of knowledge leakage from LMs. Specifically, TULA can increase an adversary's ability to infer membership information about the unlearned data by more than 20% in black-box scenario. Moreover, TULA can even reconstruct the unlearned data directly with more than 60% accuracy with white-box access. Our work is the first to reveal that machine unlearning in LMs can inversely create greater knowledge risks and inspire the development of more secure unlearning mechanisms.
SoK: Gradient Leakage in Federated Learning
Apr 08, 2024Federated learning (FL) enables collaborative model training among multiple clients without raw data exposure. However, recent studies have shown that clients' private training data can be reconstructed from the gradients they share in FL, known as gradient inversion attacks (GIAs). While GIAs have demonstrated effectiveness under \emph{ideal settings and auxiliary assumptions}, their actual efficacy against \emph{practical FL systems} remains under-explored. To address this gap, we conduct a comprehensive study on GIAs in this work. We start with a survey of GIAs that establishes a milestone to trace their evolution and develops a systematization to uncover their inherent threats. Specifically, we categorize the auxiliary assumptions used by existing GIAs based on their practical accessibility to potential adversaries. To facilitate deeper analysis, we highlight the challenges that GIAs face in practical FL systems from three perspectives: \textit{local training}, \textit{model}, and \textit{post-processing}. We then perform extensive theoretical and empirical evaluations of state-of-the-art GIAs across diverse settings, utilizing eight datasets and thirteen models. Our findings indicate that GIAs have inherent limitations when reconstructing data under practical local training settings. Furthermore, their efficacy is sensitive to the trained model, and even simple post-processing measures applied to gradients can be effective defenses. Overall, our work provides crucial insights into the limited effectiveness of GIAs in practical FL systems. By rectifying prior misconceptions, we hope to inspire more accurate and realistic investigations on this topic.