 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrid2Matrix: Revealing Digital Agnosia in Vision-Language Models
Apr 14, 2026Vision-Language Models (VLMs) excel on many multimodal reasoning benchmarks, but these evaluations often do not require an exhaustive readout of the image and can therefore obscure failures in faithfully capturing all visual details. We introduce Grid2Matrix (G2M), a controlled benchmark in which a model is shown a color grid and a color-to-number mapping, and must output the corresponding matrix. By varying grid size and the number of colors, G2M provides a simple way to increase visual complexity while minimizing semantic confounds. We find that VLMs exhibit a sharp early collapse in zero-shot end-to-end evaluation, failing on surprisingly small grids rather than degrading gradually as the task becomes denser. We probe the visual encoders of VLMs from two representative families and find that they preserve substantially more of the grid information than the corresponding end-to-end outputs. This suggests that the failure is not explained by visual encoding alone, but also reflects a gap between what remains recoverable from visual features and what is ultimately expressed in language. We term this gap \textit{Digital Agnosia}. Further analyses show that these errors are highly structured and depend strongly on how grid cells overlap with visual patch boundaries. We also find that common strategies such as model scaling and multimodal alignment do not fully eliminate this failure mode. We expect G2M to serve as a useful testbed for understanding where and how VLMs lose fine visual details, and for evaluating tasks where missing even small visual details can matter, such as tables, charts, forms, and GUIs.
TARo: Token-level Adaptive Routing for LLM Test-time Alignment
Mar 19, 2026Large language models (LLMs) exhibit strong reasoning capabilities but typically require expensive post-training to reach high performance. Recent test-time alignment methods offer a lightweight alternative, but have been explored mainly for preference alignment rather than reasoning. To bridge this gap, we propose, Token-level Adaptive Routing (TARo), which steers frozen LLMs toward structured reasoning entirely at inference time. Specifically, we first train reward models on step-wise mathematical traces to capture fine-grained logical consistency signals, then introduce a learnable token-level router that automatically controls the guidance of the reward model to the base model. Extensive experiments show that TARo significantly improves reasoning performance by up to +22.4% over base model and +8.4% over existing token-level test-time alignment methods, while also boosting out-of-distribution clinical reasoning (MedXpertQA) and instruction following (AlpacaEval). Furthermore, TARo also generalizes from small to large backbones without retraining, extending test-time alignment from preference optimization to robust, cross-domain reasoning.
Insight Miner: A Time Series Analysis Dataset for Cross-Domain Alignment with Natural Language
Dec 12, 2025

Time-series data is critical across many scientific and industrial domains, including environmental analysis, agriculture, transportation, and finance. However, mining insights from this data typically requires deep domain expertise, a process that is both time-consuming and labor-intensive. In this paper, we propose \textbf{Insight Miner}, a large-scale multimodal model (LMM) designed to generate high-quality, comprehensive time-series descriptions enriched with domain-specific knowledge. To facilitate this, we introduce \textbf{TS-Insights}\footnote{Available at \href{https://huggingface.co/datasets/zhykoties/time-series-language-alignment}{https://huggingface.co/datasets/zhykoties/time-series-language-alignment}.}, the first general-domain dataset for time series and language alignment. TS-Insights contains 100k time-series windows sampled from 20 forecasting datasets. We construct this dataset using a novel \textbf{agentic workflow}, where we use statistical tools to extract features from raw time series before synthesizing them into coherent trend descriptions with GPT-4. Following instruction tuning on TS-Insights, Insight Miner outperforms state-of-the-art multimodal models, such as LLaVA \citep{liu2023llava} and GPT-4, in generating time-series descriptions and insights. Our findings suggest a promising direction for leveraging LMMs in time series analysis, and serve as a foundational step toward enabling LLMs to interpret time series as a native input modality.
Don't Waste It: Guiding Generative Recommenders with Structured Human Priors via Multi-head Decoding
Nov 16, 2025Optimizing recommender systems for objectives beyond accuracy, such as diversity, novelty, and personalization, is crucial for long-term user satisfaction. To this end, industrial practitioners have accumulated vast amounts of structured domain knowledge, which we term human priors (e.g., item taxonomies, temporal patterns). This knowledge is typically applied through post-hoc adjustments during ranking or post-ranking. However, this approach remains decoupled from the core model learning, which is particularly undesirable as the industry shifts to end-to-end generative recommendation foundation models. On the other hand, many methods targeting these beyond-accuracy objectives often require architecture-specific modifications and discard these valuable human priors by learning user intent in a fully unsupervised manner. Instead of discarding the human priors accumulated over years of practice, we introduce a backbone-agnostic framework that seamlessly integrates these human priors directly into the end-to-end training of generative recommenders. With lightweight, prior-conditioned adapter heads inspired by efficient LLM decoding strategies, our approach guides the model to disentangle user intent along human-understandable axes (e.g., interaction types, long- vs. short-term interests). We also introduce a hierarchical composition strategy for modeling complex interactions across different prior types. Extensive experiments on three large-scale datasets demonstrate that our method significantly enhances both accuracy and beyond-accuracy objectives. We also show that human priors allow the backbone model to more effectively leverage longer context lengths and larger model sizes.
Towards VM Rescheduling Optimization Through Deep Reinforcement Learning
May 23, 2025Modern industry-scale data centers need to manage a large number of virtual machines (VMs). Due to the continual creation and release of VMs, many small resource fragments are scattered across physical machines (PMs). To handle these fragments, data centers periodically reschedule some VMs to alternative PMs, a practice commonly referred to as VM rescheduling. Despite the increasing importance of VM rescheduling as data centers grow in size, the problem remains understudied. We first show that, unlike most combinatorial optimization tasks, the inference time of VM rescheduling algorithms significantly influences their performance, due to dynamic VM state changes during this period. This causes existing methods to scale poorly. Therefore, we develop a reinforcement learning system for VM rescheduling, VM2RL, which incorporates a set of customized techniques, such as a two-stage framework that accommodates diverse constraints and workload conditions, a feature extraction module that captures relational information specific to rescheduling, as well as a risk-seeking evaluation enabling users to optimize the trade-off between latency and accuracy. We conduct extensive experiments with data from an industry-scale data center. Our results show that VM2RL can achieve a performance comparable to the optimal solution but with a running time of seconds. Code and datasets are open-sourced: https://github.com/zhykoties/VMR2L_eurosys, https://drive.google.com/drive/folders/1PfRo1cVwuhH30XhsE2Np3xqJn2GpX5qy.
The Tenth NTIRE 2025 Image Denoising Challenge Report
Apr 16, 2025



This paper presents an overview of the NTIRE 2025 Image Denoising Challenge ({\sigma} = 50), highlighting the proposed methodologies and corresponding results. The primary objective is to develop a network architecture capable of achieving high-quality denoising performance, quantitatively evaluated using PSNR, without constraints on computational complexity or model size. The task assumes independent additive white Gaussian noise (AWGN) with a fixed noise level of 50. A total of 290 participants registered for the challenge, with 20 teams successfully submitting valid results, providing insights into the current state-of-the-art in image denoising.
SDIGLM: Leveraging Large Language Models and Multi-Modal Chain of Thought for Structural Damage Identification
Apr 12, 2025Existing computer vision(CV)-based structural damage identification models demonstrate notable accuracy in categorizing and localizing damage. However, these models present several critical limitations that hinder their practical application in civil engineering(CE). Primarily, their ability to recognize damage types remains constrained, preventing comprehensive analysis of the highly varied and complex conditions encountered in real-world CE structures. Second, these models lack linguistic capabilities, rendering them unable to articulate structural damage characteristics through natural language descriptions. With the continuous advancement of artificial intelligence(AI), large multi-modal models(LMMs) have emerged as a transformative solution, enabling the unified encoding and alignment of textual and visual data. These models can autonomously generate detailed descriptive narratives of structural damage while demonstrating robust generalization across diverse scenarios and tasks. This study introduces SDIGLM, an innovative LMM for structural damage identification, developed based on the open-source VisualGLM-6B architecture. To address the challenge of adapting LMMs to the intricate and varied operating conditions in CE, this work integrates a U-Net-based semantic segmentation module to generate defect segmentation maps as visual Chain of Thought(CoT). Additionally, a multi-round dialogue fine-tuning dataset is constructed to enhance logical reasoning, complemented by a language CoT formed through prompt engineering. By leveraging this multi-modal CoT, SDIGLM surpasses general-purpose LMMs in structural damage identification, achieving an accuracy of 95.24% across various infrastructure types. Moreover, the model effectively describes damage characteristics such as hole size, crack direction, and corrosion severity.
NTIRE 2024 Challenge on Low Light Image Enhancement: Methods and Results
Apr 22, 2024



This paper reviews the NTIRE 2024 low light image enhancement challenge, highlighting the proposed solutions and results. The aim of this challenge is to discover an effective network design or solution capable of generating brighter, clearer, and visually appealing results when dealing with a variety of conditions, including ultra-high resolution (4K and beyond), non-uniform illumination, backlighting, extreme darkness, and night scenes. A notable total of 428 participants registered for the challenge, with 22 teams ultimately making valid submissions. This paper meticulously evaluates the state-of-the-art advancements in enhancing low-light images, reflecting the significant progress and creativity in this field.
Scalable Primal-Dual Actor-Critic Method for Safe Multi-Agent RL with General Utilities
May 27, 2023We investigate safe multi-agent reinforcement learning, where agents seek to collectively maximize an aggregate sum of local objectives while satisfying their own safety constraints. The objective and constraints are described by {\it general utilities}, i.e., nonlinear functions of the long-term state-action occupancy measure, which encompass broader decision-making goals such as risk, exploration, or imitations. The exponential growth of the state-action space size with the number of agents presents challenges for global observability, further exacerbated by the global coupling arising from agents' safety constraints. To tackle this issue, we propose a primal-dual method utilizing shadow reward and $\kappa$-hop neighbor truncation under a form of correlation decay property, where $\kappa$ is the communication radius. In the exact setting, our algorithm converges to a first-order stationary point (FOSP) at the rate of $\mathcal{O}\left(T^{-2/3}\right)$. In the sample-based setting, we demonstrate that, with high probability, our algorithm requires $\widetilde{\mathcal{O}}\left(\epsilon^{-3.5}\right)$ samples to achieve an $\epsilon$-FOSP with an approximation error of $\mathcal{O}(\phi_0^{2\kappa})$, where $\phi_0\in (0,1)$. Finally, we demonstrate the effectiveness of our model through extensive numerical experiments.
Continuous Conditional Generative Adversarial Networks (cGAN) with Generator Regularization
Mar 27, 2021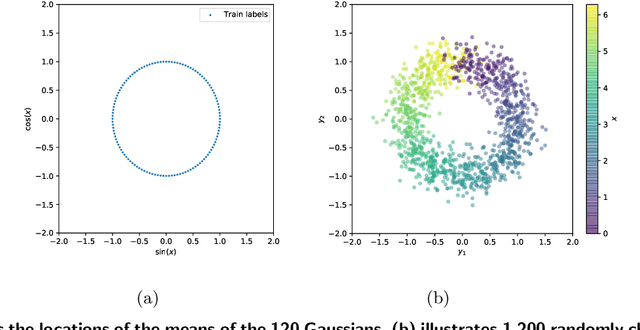
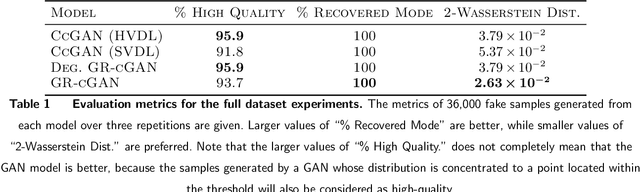
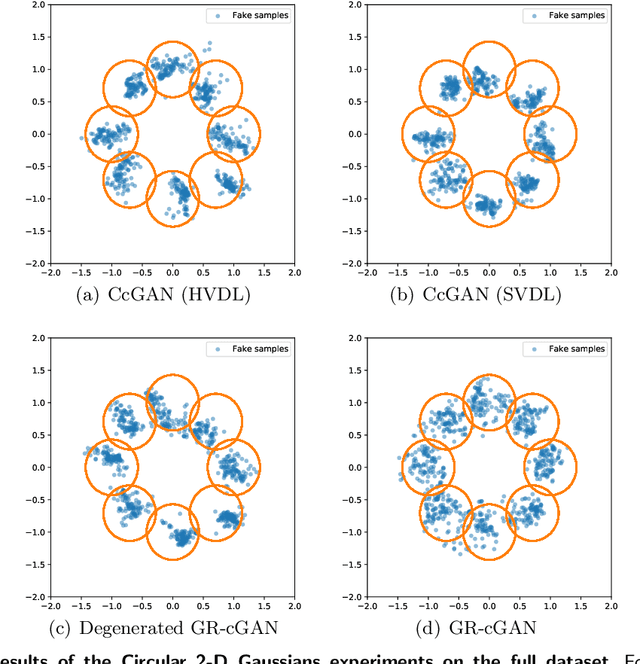
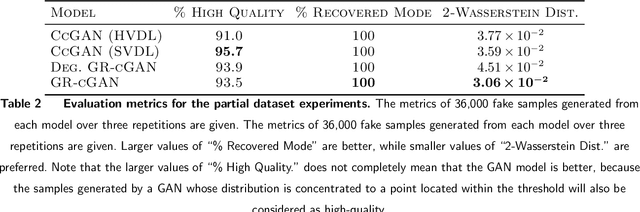
Conditional Generative Adversarial Networks are known to be difficult to train, especially when the conditions are continuous and high-dimensional. To partially alleviate this difficulty, we propose a simple generator regularization term on the GAN generator loss in the form of Lipschitz penalty. Thus, when the generator is fed with neighboring conditions in the continuous space, the regularization term will leverage the neighbor information and push the generator to generate samples that have similar conditional distributions for each neighboring condition. We analyze the effect of the proposed regularization term and demonstrate its robust performance on a range of synthetic and real-world tasks.