 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFamily-Aware Residual Architecture for Predicting Quantum Circuit Simulation Performance
Jun 10, 2026Approximate tensor-network simulators enable classical simulation of quantum circuits beyond the reach of exact methods, but selecting optimal approximation parameters -- such as bond dimension thresholds -- remains a costly trial-and-error process. We present a family-aware neural architecture that predicts both the minimum approximation threshold required to achieve target fidelity and the expected wall-clock runtime for quantum circuit simulation, given only the circuit's OpenQASM description and execution context. Our key insight is that quantum circuits from different algorithmic families (e.g., QFT, Grover, VQE) exhibit fundamentally distinct simulation cost profiles due to their differing entanglement structures. We employ family-conditioned residual corrections -- additive, family-specific adjustments atop a shared backbone, drawing on established conditional computation techniques -- enabling the model to capture both universal circuit properties and algorithmic nuances. The architecture incorporates a pretrained family classifier (97.5% accuracy) and domain-informed algorithm fingerprint features derived from gate-composition heuristics. Evaluated on circuits spanning 7--130 qubits across 10 algorithm families, our system achieves 79.5% exact threshold accuracy (91.2% within one rung) and $R^2 = 0.82$ runtime correlation, with inference completing in approximately 50 ms -- replacing trial-and-error simulation runs that may take minutes to hours. Ablation studies confirm that family-aware modeling provides the single largest performance improvement (+3.2 percentage points), validating the hypothesis that algorithm family is a first-class feature for simulation cost prediction.
One-step Latent-free Image Generation with Pixel Mean Flows
Jan 29, 2026Modern diffusion/flow-based models for image generation typically exhibit two core characteristics: (i) using multi-step sampling, and (ii) operating in a latent space. Recent advances have made encouraging progress on each aspect individually, paving the way toward one-step diffusion/flow without latents. In this work, we take a further step towards this goal and propose "pixel MeanFlow" (pMF). Our core guideline is to formulate the network output space and the loss space separately. The network target is designed to be on a presumed low-dimensional image manifold (i.e., x-prediction), while the loss is defined via MeanFlow in the velocity space. We introduce a simple transformation between the image manifold and the average velocity field. In experiments, pMF achieves strong results for one-step latent-free generation on ImageNet at 256x256 resolution (2.22 FID) and 512x512 resolution (2.48 FID), filling a key missing piece in this regime. We hope that our study will further advance the boundaries of diffusion/flow-based generative models.
Seed-Prover 1.5: Mastering Undergraduate-Level Theorem Proving via Learning from Experience
Dec 19, 2025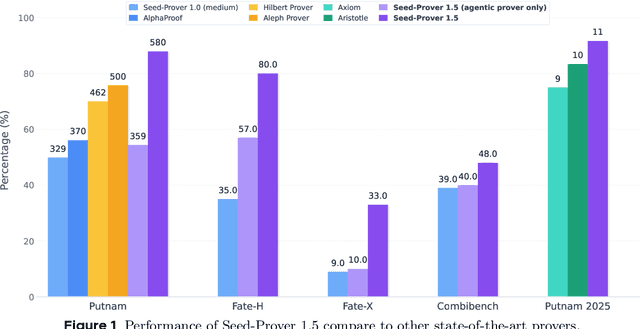

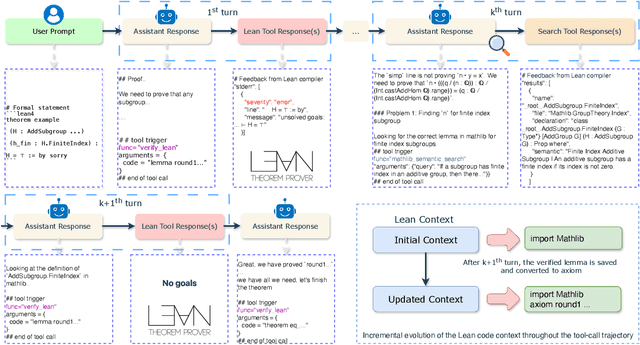

Large language models have recently made significant progress to generate rigorous mathematical proofs. In contrast, utilizing LLMs for theorem proving in formal languages (such as Lean) remains challenging and computationally expensive, particularly when addressing problems at the undergraduate level and beyond. In this work, we present \textbf{Seed-Prover 1.5}, a formal theorem-proving model trained via large-scale agentic reinforcement learning, alongside an efficient test-time scaling (TTS) workflow. Through extensive interactions with Lean and other tools, the model continuously accumulates experience during the RL process, substantially enhancing the capability and efficiency of formal theorem proving. Furthermore, leveraging recent advancements in natural language proving, our TTS workflow efficiently bridges the gap between natural and formal languages. Compared to state-of-the-art methods, Seed-Prover 1.5 achieves superior performance with a smaller compute budget. It solves \textbf{88\% of PutnamBench} (undergraduate-level), \textbf{80\% of Fate-H} (graduate-level), and \textbf{33\% of Fate-X} (PhD-level) problems. Notably, using our system, we solved \textbf{11 out of 12 problems} from Putnam 2025 within 9 hours. Our findings suggest that scaling learning from experience, driven by high-quality formal feedback, holds immense potential for the future of formal mathematical reasoning.
Bidirectional Normalizing Flow: From Data to Noise and Back
Dec 11, 2025Normalizing Flows (NFs) have been established as a principled framework for generative modeling. Standard NFs consist of a forward process and a reverse process: the forward process maps data to noise, while the reverse process generates samples by inverting it. Typical NF forward transformations are constrained by explicit invertibility, ensuring that the reverse process can serve as their exact analytic inverse. Recent developments in TARFlow and its variants have revitalized NF methods by combining Transformers and autoregressive flows, but have also exposed causal decoding as a major bottleneck. In this work, we introduce Bidirectional Normalizing Flow ($\textbf{BiFlow}$), a framework that removes the need for an exact analytic inverse. BiFlow learns a reverse model that approximates the underlying noise-to-data inverse mapping, enabling more flexible loss functions and architectures. Experiments on ImageNet demonstrate that BiFlow, compared to its causal decoding counterpart, improves generation quality while accelerating sampling by up to two orders of magnitude. BiFlow yields state-of-the-art results among NF-based methods and competitive performance among single-evaluation ("1-NFE") methods. Following recent encouraging progress on NFs, we hope our work will draw further attention to this classical paradigm.
Seed-Prover: Deep and Broad Reasoning for Automated Theorem Proving
Aug 01, 2025LLMs have demonstrated strong mathematical reasoning abilities by leveraging reinforcement learning with long chain-of-thought, yet they continue to struggle with theorem proving due to the lack of clear supervision signals when solely using natural language. Dedicated domain-specific languages like Lean provide clear supervision via formal verification of proofs, enabling effective training through reinforcement learning. In this work, we propose \textbf{Seed-Prover}, a lemma-style whole-proof reasoning model. Seed-Prover can iteratively refine its proof based on Lean feedback, proved lemmas, and self-summarization. To solve IMO-level contest problems, we design three test-time inference strategies that enable both deep and broad reasoning. Seed-Prover proves $78.1\%$ of formalized past IMO problems, saturates MiniF2F, and achieves over 50\% on PutnamBench, outperforming the previous state-of-the-art by a large margin. To address the lack of geometry support in Lean, we introduce a geometry reasoning engine \textbf{Seed-Geometry}, which outperforms previous formal geometry engines. We use these two systems to participate in IMO 2025 and fully prove 5 out of 6 problems. This work represents a significant advancement in automated mathematical reasoning, demonstrating the effectiveness of formal verification with long chain-of-thought reasoning.
Is Noise Conditioning Necessary for Denoising Generative Models?
Feb 18, 2025



It is widely believed that noise conditioning is indispensable for denoising diffusion models to work successfully. This work challenges this belief. Motivated by research on blind image denoising, we investigate a variety of denoising-based generative models in the absence of noise conditioning. To our surprise, most models exhibit graceful degradation, and in some cases, they even perform better without noise conditioning. We provide a theoretical analysis of the error caused by removing noise conditioning and demonstrate that our analysis aligns with empirical observations. We further introduce a noise-unconditional model that achieves a competitive FID of 2.23 on CIFAR-10, significantly narrowing the gap to leading noise-conditional models. We hope our findings will inspire the community to revisit the foundations and formulations of denoising generative models.