 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing the Quality and Stability of a Streaming End-to-End On-Device Speech Recognizer
Jun 02, 2020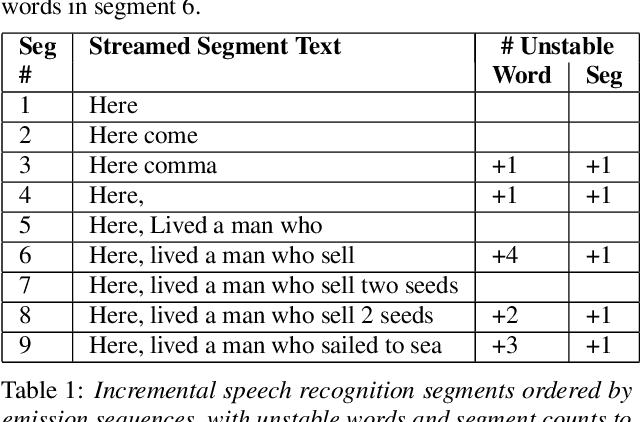
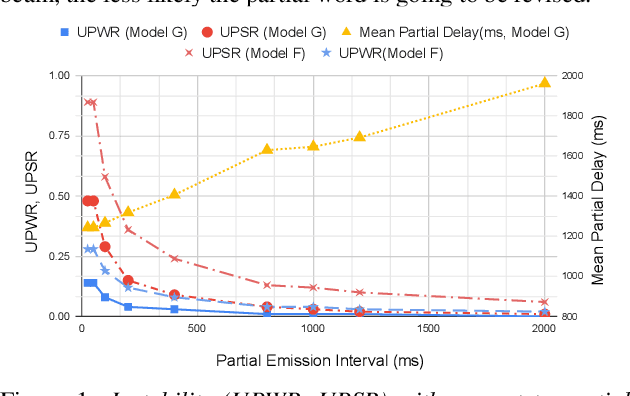
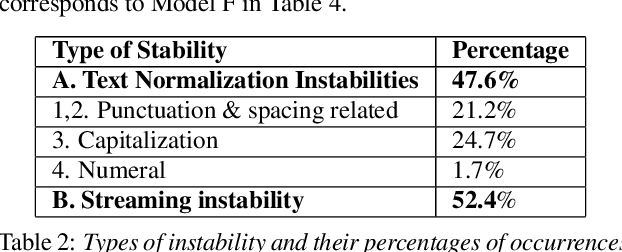
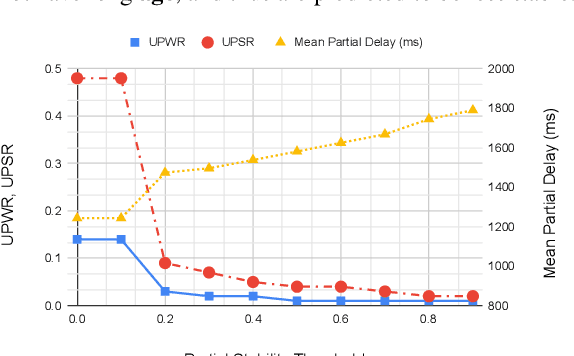
The demand for fast and accurate incremental speech recognition increases as the applications of automatic speech recognition (ASR) proliferate. Incremental speech recognizers output chunks of partially recognized words while the user is still talking. Partial results can be revised before the ASR finalizes its hypothesis, causing instability issues. We analyze the quality and stability of on-device streaming end-to-end (E2E) ASR models. We first introduce a novel set of metrics that quantify the instability at word and segment levels. We study the impact of several model training techniques that improve E2E model qualities but degrade model stability. We categorize the causes of instability and explore various solutions to mitigate them in a streaming E2E ASR system. Index Terms: ASR, stability, end-to-end, text normalization,on-device, RNN-T
A Streaming On-Device End-to-End Model Surpassing Server-Side Conventional Model Quality and Latency
Mar 28, 2020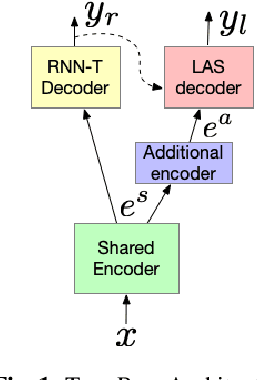
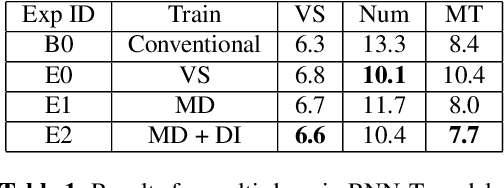
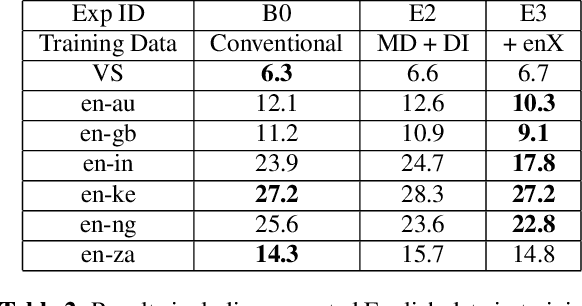
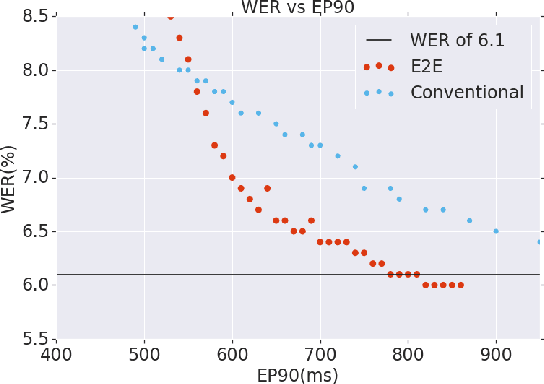
Thus far, end-to-end (E2E) models have not been shown to outperform state-of-the-art conventional models with respect to both quality, i.e., word error rate (WER), and latency, i.e., the time the hypothesis is finalized after the user stops speaking. In this paper, we develop a first-pass Recurrent Neural Network Transducer (RNN-T) model and a second-pass Listen, Attend, Spell (LAS) rescorer that surpasses a conventional model in both quality and latency. On the quality side, we incorporate a large number of utterances across varied domains to increase acoustic diversity and the vocabulary seen by the model. We also train with accented English speech to make the model more robust to different pronunciations. In addition, given the increased amount of training data, we explore a varied learning rate schedule. On the latency front, we explore using the end-of-sentence decision emitted by the RNN-T model to close the microphone, and also introduce various optimizations to improve the speed of LAS rescoring. Overall, we find that RNN-T+LAS offers a better WER and latency tradeoff compared to a conventional model. For example, for the same latency, RNN-T+LAS obtains a 8% relative improvement in WER, while being more than 400-times smaller in model size.
Two-Pass End-to-End Speech Recognition
Aug 29, 2019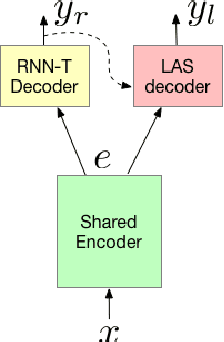

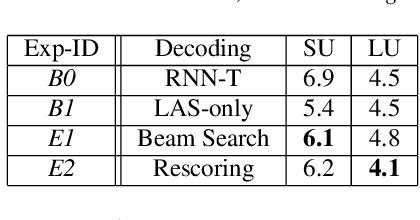
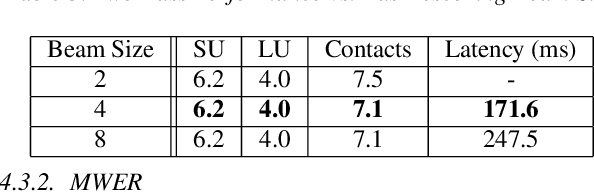
The requirements for many applications of state-of-the-art speech recognition systems include not only low word error rate (WER) but also low latency. Specifically, for many use-cases, the system must be able to decode utterances in a streaming fashion and faster than real-time. Recently, a streaming recurrent neural network transducer (RNN-T) end-to-end (E2E) model has shown to be a good candidate for on-device speech recognition, with improved WER and latency metrics compared to conventional on-device models [1]. However, this model still lags behind a large state-of-the-art conventional model in quality [2]. On the other hand, a non-streaming E2E Listen, Attend and Spell (LAS) model has shown comparable quality to large conventional models [3]. This work aims to bring the quality of an E2E streaming model closer to that of a conventional system by incorporating a LAS network as a second-pass component, while still abiding by latency constraints. Our proposed two-pass model achieves a 17%-22% relative reduction in WER compared to RNN-T alone and increases latency by a small fraction over RNN-T.
Lingvo: a Modular and Scalable Framework for Sequence-to-Sequence Modeling
Feb 21, 2019


Lingvo is a Tensorflow framework offering a complete solution for collaborative deep learning research, with a particular focus towards sequence-to-sequence models. Lingvo models are composed of modular building blocks that are flexible and easily extensible, and experiment configurations are centralized and highly customizable. Distributed training and quantized inference are supported directly within the framework, and it contains existing implementations of a large number of utilities, helper functions, and the newest research ideas. Lingvo has been used in collaboration by dozens of researchers in more than 20 papers over the last two years. This document outlines the underlying design of Lingvo and serves as an introduction to the various pieces of the framework, while also offering examples of advanced features that showcase the capabilities of the framework.
Streaming End-to-end Speech Recognition For Mobile Devices
Nov 15, 2018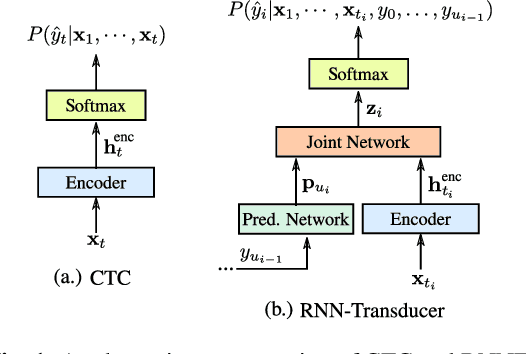
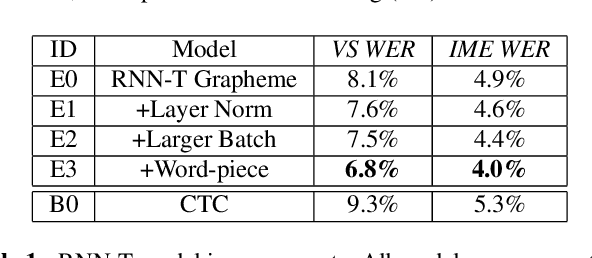
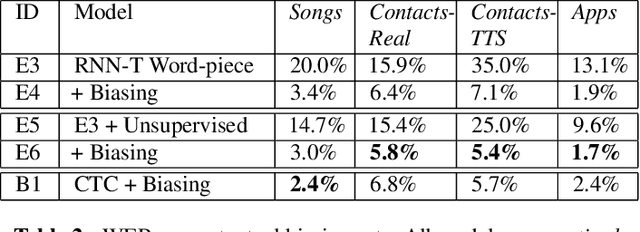
End-to-end (E2E) models, which directly predict output character sequences given input speech, are good candidates for on-device speech recognition. E2E models, however, present numerous challenges: In order to be truly useful, such models must decode speech utterances in a streaming fashion, in real time; they must be robust to the long tail of use cases; they must be able to leverage user-specific context (e.g., contact lists); and above all, they must be extremely accurate. In this work, we describe our efforts at building an E2E speech recognizer using a recurrent neural network transducer. In experimental evaluations, we find that the proposed approach can outperform a conventional CTC-based model in terms of both latency and accuracy in a number of evaluation categories.
Streaming Small-Footprint Keyword Spotting using Sequence-to-Sequence Models
Oct 26, 2017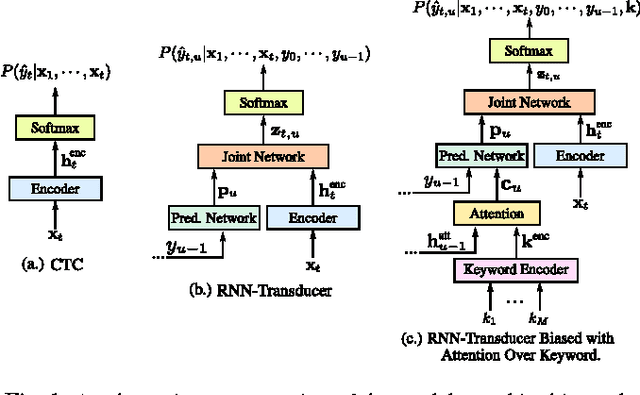
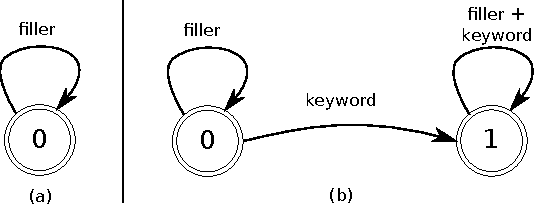
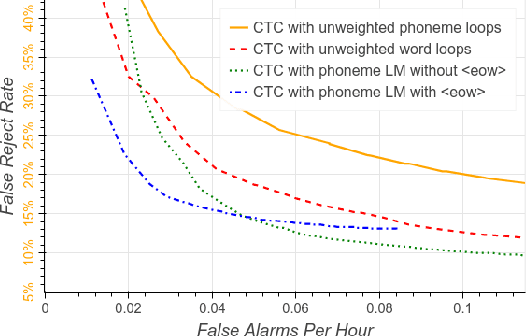
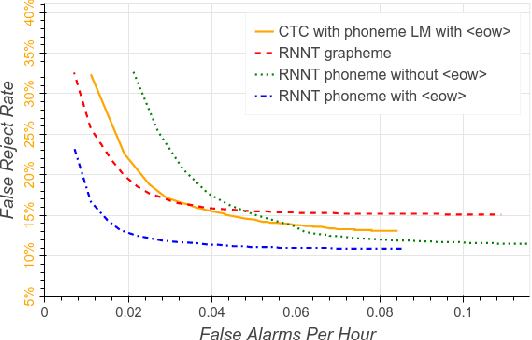
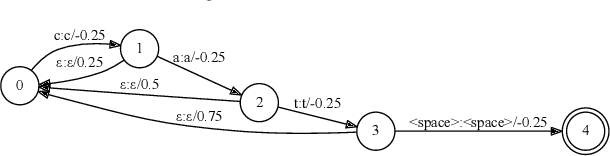
We develop streaming keyword spotting systems using a recurrent neural network transducer (RNN-T) model: an all-neural, end-to-end trained, sequence-to-sequence model which jointly learns acoustic and language model components. Our models are trained to predict either phonemes or graphemes as subword units, thus allowing us to detect arbitrary keyword phrases, without any out-of-vocabulary words. In order to adapt the models to the requirements of keyword spotting, we propose a novel technique which biases the RNN-T system towards a specific keyword of interest. Our systems are compared against a strong sequence-trained, connectionist temporal classification (CTC) based "keyword-filler" baseline, which is augmented with a separate phoneme language model. Overall, our RNN-T system with the proposed biasing technique significantly improves performance over the baseline system.