 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoordinated Multi-Drone Last-mile Delivery: Learning Strategies for Energy-aware and Timely Operations
Sep 19, 2025Drones have recently emerged as a faster, safer, and cost-efficient way for last-mile deliveries of parcels, particularly for urgent medical deliveries highlighted during the pandemic. This paper addresses a new challenge of multi-parcel delivery with a swarm of energy-aware drones, accounting for time-sensitive customer requirements. Each drone plans an optimal multi-parcel route within its battery-restricted flight range to minimize delivery delays and reduce energy consumption. The problem is tackled by decomposing it into three sub-problems: (1) optimizing depot locations and service areas using K-means clustering; (2) determining the optimal flight range for drones through reinforcement learning; and (3) planning and selecting multi-parcel delivery routes via a new optimized plan selection approach. To integrate these solutions and enhance long-term efficiency, we propose a novel algorithm leveraging actor-critic-based multi-agent deep reinforcement learning. Extensive experimentation using realistic delivery datasets demonstrate an exceptional performance of the proposed algorithm. We provide new insights into economic efficiency (minimize energy consumption), rapid operations (reduce delivery delays and overall execution time), and strategic guidance on depot deployment for practical logistics applications.
Can DeepFake Speech be Reliably Detected?
Oct 09, 2024



Recent advances in text-to-speech (TTS) systems, particularly those with voice cloning capabilities, have made voice impersonation readily accessible, raising ethical and legal concerns due to potential misuse for malicious activities like misinformation campaigns and fraud. While synthetic speech detectors (SSDs) exist to combat this, they are vulnerable to ``test domain shift", exhibiting decreased performance when audio is altered through transcoding, playback, or background noise. This vulnerability is further exacerbated by deliberate manipulation of synthetic speech aimed at deceiving detectors. This work presents the first systematic study of such active malicious attacks against state-of-the-art open-source SSDs. White-box attacks, black-box attacks, and their transferability are studied from both attack effectiveness and stealthiness, using both hardcoded metrics and human ratings. The results highlight the urgent need for more robust detection methods in the face of evolving adversarial threats.
Training Large ASR Encoders with Differential Privacy
Sep 21, 2024



Self-supervised learning (SSL) methods for large speech models have proven to be highly effective at ASR. With the interest in public deployment of large pre-trained models, there is a rising concern for unintended memorization and leakage of sensitive data points from the training data. In this paper, we apply differentially private (DP) pre-training to a SOTA Conformer-based encoder, and study its performance on a downstream ASR task assuming the fine-tuning data is public. This paper is the first to apply DP to SSL for ASR, investigating the DP noise tolerance of the BEST-RQ pre-training method. Notably, we introduce a novel variant of model pruning called gradient-based layer freezing that provides strong improvements in privacy-utility-compute trade-offs. Our approach yields a LibriSpeech test-clean/other WER (%) of 3.78/ 8.41 with ($10$, 1e^-9)-DP for extrapolation towards low dataset scales, and 2.81/ 5.89 with (10, 7.9e^-11)-DP for extrapolation towards high scales.
Efficiently Train ASR Models that Memorize Less and Perform Better with Per-core Clipping
Jun 04, 2024Gradient clipping plays a vital role in training large-scale automatic speech recognition (ASR) models. It is typically applied to minibatch gradients to prevent gradient explosion, and to the individual sample gradients to mitigate unintended memorization. This work systematically investigates the impact of a specific granularity of gradient clipping, namely per-core clip-ping (PCC), across training a wide range of ASR models. We empirically demonstrate that PCC can effectively mitigate unintended memorization in ASR models. Surprisingly, we find that PCC positively influences ASR performance metrics, leading to improved convergence rates and reduced word error rates. To avoid tuning the additional hyperparameter introduced by PCC, we further propose a novel variant, adaptive per-core clipping (APCC), for streamlined optimization. Our findings highlight the multifaceted benefits of PCC as a strategy for robust, privacy-forward ASR model training.
Extreme Encoder Output Frame Rate Reduction: Improving Computational Latencies of Large End-to-End Models
Feb 27, 2024The accuracy of end-to-end (E2E) automatic speech recognition (ASR) models continues to improve as they are scaled to larger sizes, with some now reaching billions of parameters. Widespread deployment and adoption of these models, however, requires computationally efficient strategies for decoding. In the present work, we study one such strategy: applying multiple frame reduction layers in the encoder to compress encoder outputs into a small number of output frames. While similar techniques have been investigated in previous work, we achieve dramatically more reduction than has previously been demonstrated through the use of multiple funnel reduction layers. Through ablations, we study the impact of various architectural choices in the encoder to identify the most effective strategies. We demonstrate that we can generate one encoder output frame for every 2.56 sec of input speech, without significantly affecting word error rate on a large-scale voice search task, while improving encoder and decoder latencies by 48% and 92% respectively, relative to a strong but computationally expensive baseline.
A Universally-Deployable ASR Frontend for Joint Acoustic Echo Cancellation, Speech Enhancement, and Voice Separation
Sep 14, 2022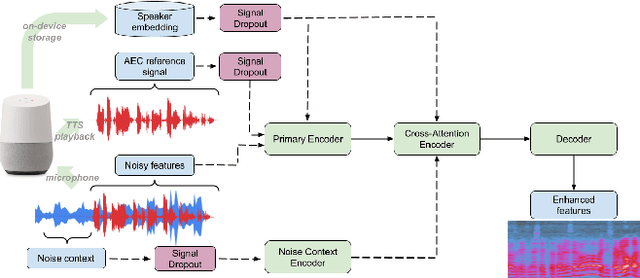

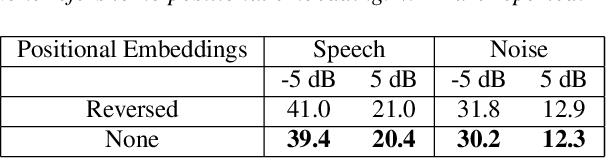
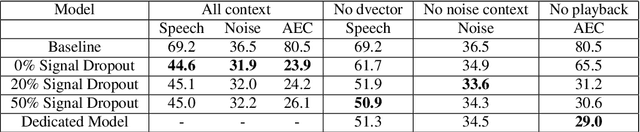
Recent work has shown that it is possible to train a single model to perform joint acoustic echo cancellation (AEC), speech enhancement, and voice separation, thereby serving as a unified frontend for robust automatic speech recognition (ASR). The joint model uses contextual information, such as a reference of the playback audio, noise context, and speaker embedding. In this work, we propose a number of novel improvements to such a model. First, we improve the architecture of the Cross-Attention Conformer that is used to ingest noise context into the model. Second, we generalize the model to be able to handle varying lengths of noise context. Third, we propose Signal Dropout, a novel strategy that models missing contextual information. In the absence of one or more signals, the proposed model performs nearly as well as task-specific models trained without these signals; and when such signals are present, our system compares well against systems that require all context signals. Over the baseline, the final model retains a relative word error rate reduction of 25.0% on background speech when speaker embedding is absent, and 61.2% on AEC when device playback is absent.
Streaming Noise Context Aware Enhancement For Automatic Speech Recognition in Multi-Talker Environments
May 17, 2022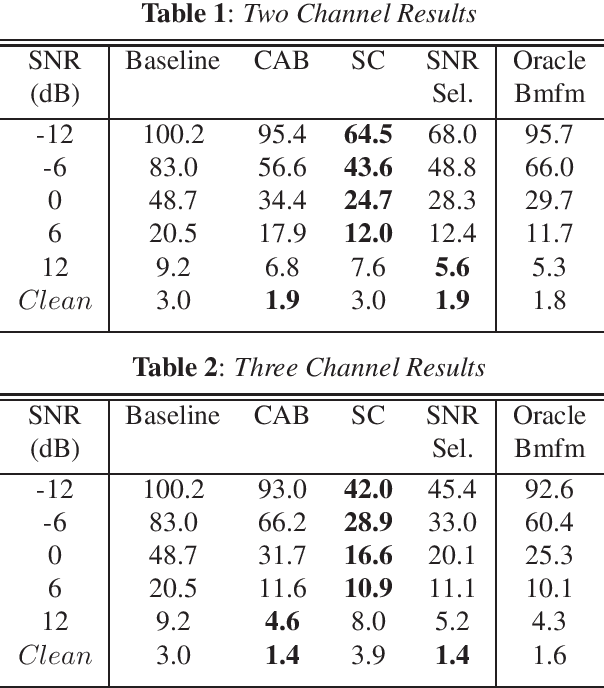
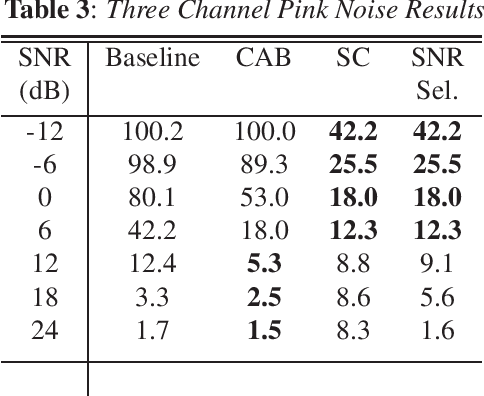
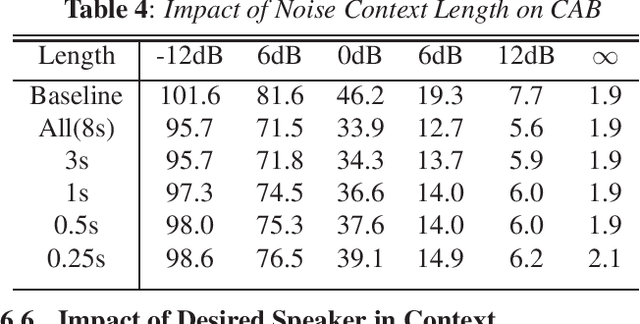
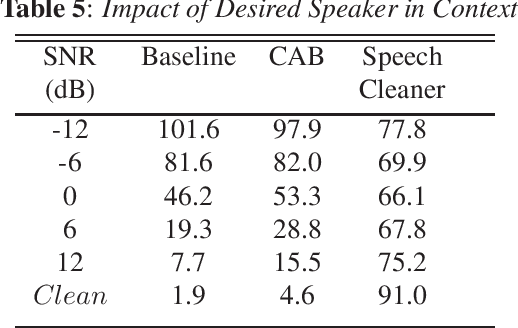
One of the most challenging scenarios for smart speakers is multi-talker, when target speech from the desired speaker is mixed with interfering speech from one or more speakers. A smart assistant needs to determine which voice to recognize and which to ignore and it needs to do so in a streaming, low-latency manner. This work presents two multi-microphone speech enhancement algorithms targeted at this scenario. Targeting on-device use-cases, we assume that the algorithm has access to the signal before the hotword, which is referred to as the noise context. First is the Context Aware Beamformer which uses the noise context and detected hotword to determine how to target the desired speaker. The second is an adaptive noise cancellation algorithm called Speech Cleaner which trains a filter using the noise context. It is demonstrated that the two algorithms are complementary in the signal-to-noise ratio conditions under which they work well. We also propose an algorithm to select which one to use based on estimated SNR. When using 3 microphone channels, the final system achieves a relative word error rate reduction of 55% at -12dB, and 43\% at 12dB.
A Conformer-based Waveform-domain Neural Acoustic Echo Canceller Optimized for ASR Accuracy
May 06, 2022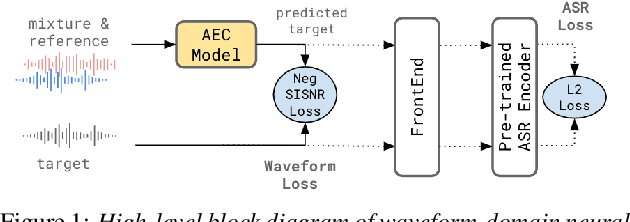
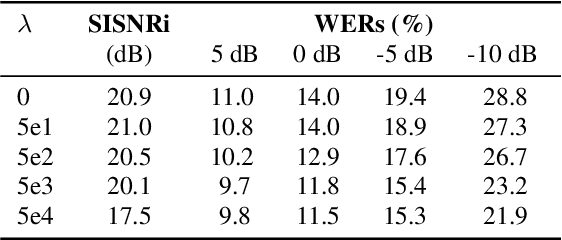
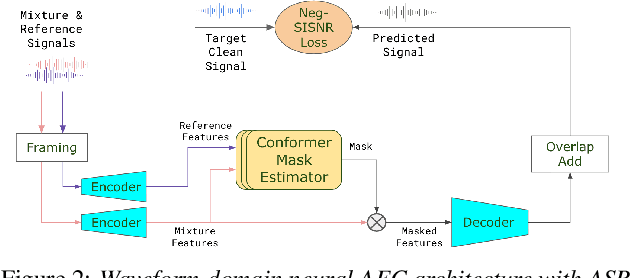
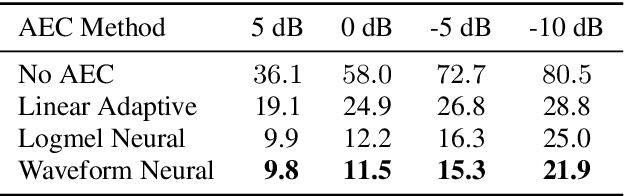
Acoustic Echo Cancellation (AEC) is essential for accurate recognition of queries spoken to a smart speaker that is playing out audio. Previous work has shown that a neural AEC model operating on log-mel spectral features (denoted "logmel" hereafter) can greatly improve Automatic Speech Recognition (ASR) accuracy when optimized with an auxiliary loss utilizing a pre-trained ASR model encoder. In this paper, we develop a conformer-based waveform-domain neural AEC model inspired by the "TasNet" architecture. The model is trained by jointly optimizing Negative Scale-Invariant SNR (SISNR) and ASR losses on a large speech dataset. On a realistic rerecorded test set, we find that cascading a linear adaptive AEC and a waveform-domain neural AEC is very effective, giving 56-59% word error rate (WER) reduction over the linear AEC alone. On this test set, the 1.6M parameter waveform-domain neural AEC also improves over a larger 6.5M parameter logmel-domain neural AEC model by 20-29% in easy to moderate conditions. By operating on smaller frames, the waveform neural model is able to perform better at smaller sizes and is better suited for applications where memory is limited.
Mask scalar prediction for improving robust automatic speech recognition
Apr 26, 2022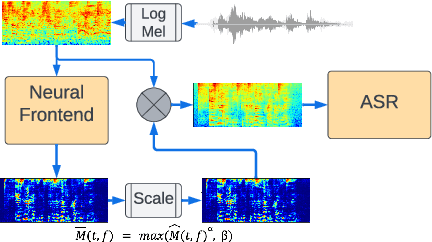
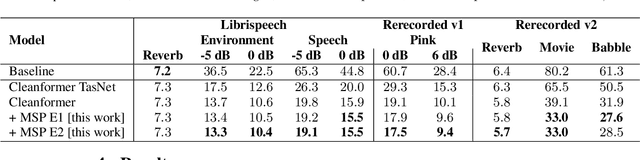
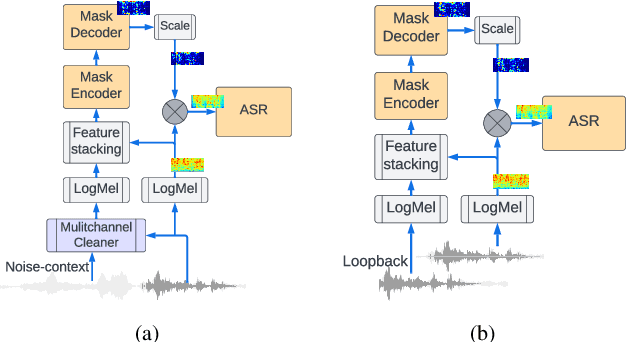
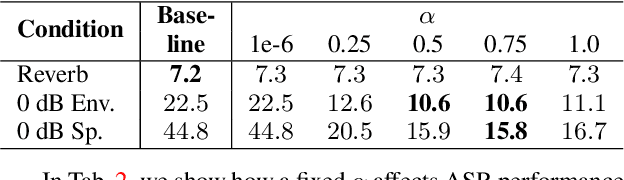
Using neural network based acoustic frontends for improving robustness of streaming automatic speech recognition (ASR) systems is challenging because of the causality constraints and the resulting distortion that the frontend processing introduces in speech. Time-frequency masking based approaches have been shown to work well, but they need additional hyper-parameters to scale the mask to limit speech distortion. Such mask scalars are typically hand-tuned and chosen conservatively. In this work, we present a technique to predict mask scalars using an ASR-based loss in an end-to-end fashion, with minimal increase in the overall model size and complexity. We evaluate the approach on two robust ASR tasks: multichannel enhancement in the presence of speech and non-speech noise, and acoustic echo cancellation (AEC). Results show that the presented algorithm consistently improves word error rate (WER) without the need for any additional tuning over strong baselines that use hand-tuned hyper-parameters: up to 16% for multichannel enhancement in noisy conditions, and up to 7% for AEC.
Extracting Targeted Training Data from ASR Models, and How to Mitigate It
Apr 18, 2022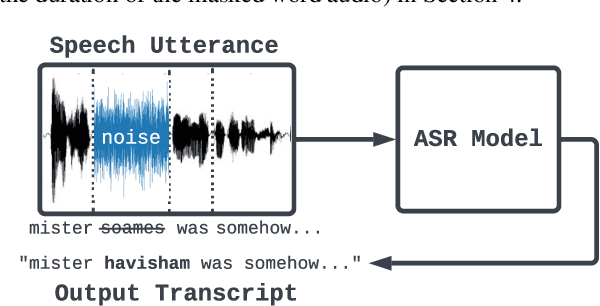
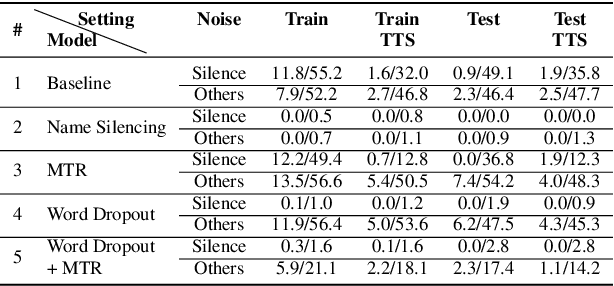
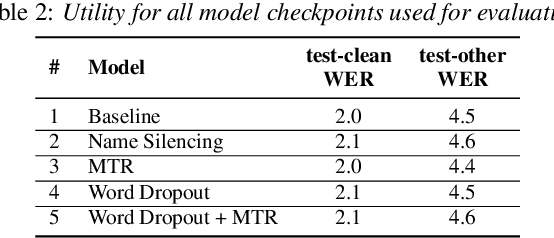
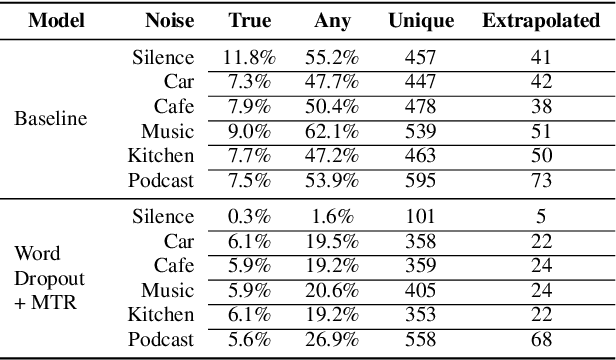
Recent work has designed methods to demonstrate that model updates in ASR training can leak potentially sensitive attributes of the utterances used in computing the updates. In this work, we design the first method to demonstrate information leakage about training data from trained ASR models. We design Noise Masking, a fill-in-the-blank style method for extracting targeted parts of training data from trained ASR models. We demonstrate the success of Noise Masking by using it in four settings for extracting names from the LibriSpeech dataset used for training a SOTA Conformer model. In particular, we show that we are able to extract the correct names from masked training utterances with 11.8% accuracy, while the model outputs some name from the train set 55.2% of the time. Further, we show that even in a setting that uses synthetic audio and partial transcripts from the test set, our method achieves 2.5% correct name accuracy (47.7% any name success rate). Lastly, we design Word Dropout, a data augmentation method that we show when used in training along with MTR, provides comparable utility as the baseline, along with significantly mitigating extraction via Noise Masking across the four evaluated settings.