 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage model fusion for streaming end to end speech recognition
Apr 09, 2021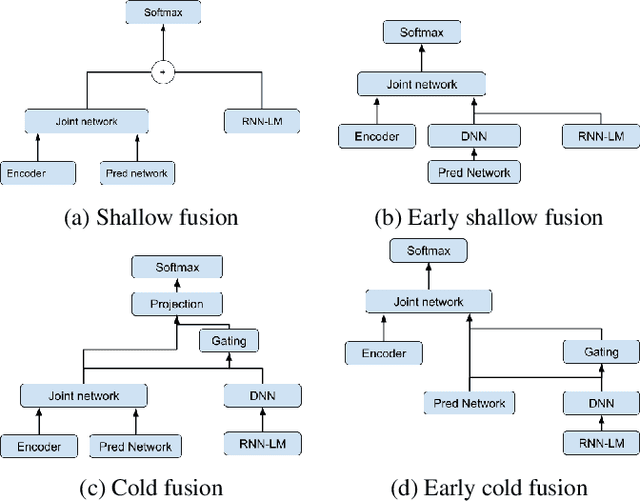
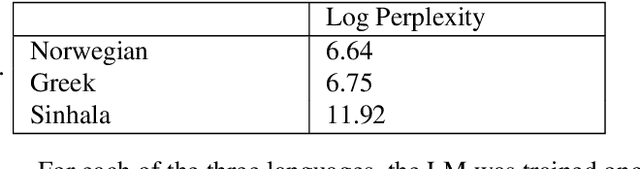
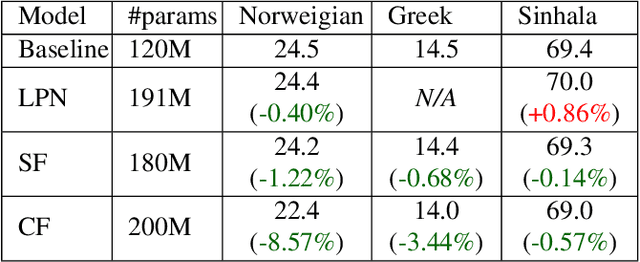
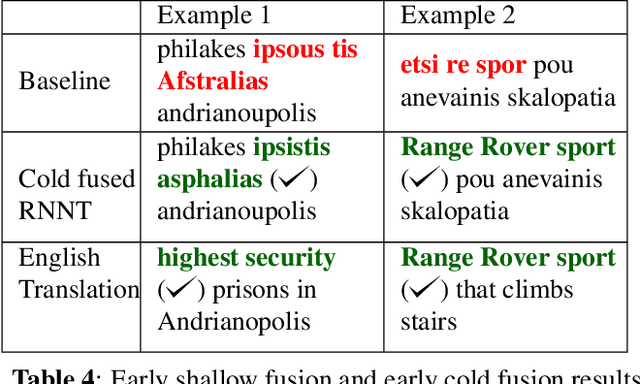
Streaming processing of speech audio is required for many contemporary practical speech recognition tasks. Even with the large corpora of manually transcribed speech data available today, it is impossible for such corpora to cover adequately the long tail of linguistic content that's important for tasks such as open-ended dictation and voice search. We seek to address both the streaming and the tail recognition challenges by using a language model (LM) trained on unpaired text data to enhance the end-to-end (E2E) model. We extend shallow fusion and cold fusion approaches to streaming Recurrent Neural Network Transducer (RNNT), and also propose two new competitive fusion approaches that further enhance the RNNT architecture. Our results on multiple languages with varying training set sizes show that these fusion methods improve streaming RNNT performance through introducing extra linguistic features. Cold fusion works consistently better on streaming RNNT with up to a 8.5% WER improvement.
Language-agnostic Multilingual Modeling
Apr 20, 2020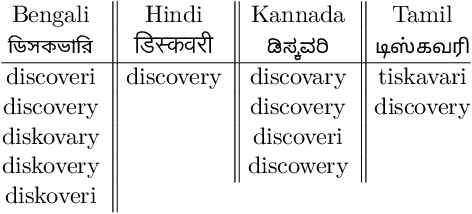
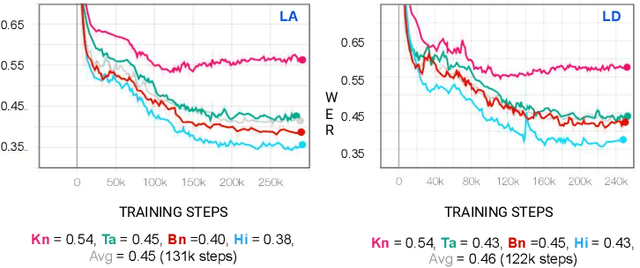
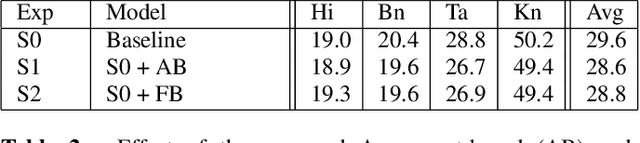
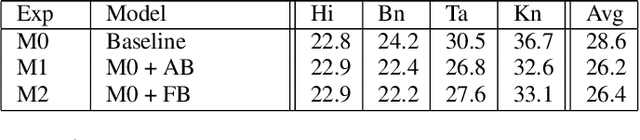
Multilingual Automated Speech Recognition (ASR) systems allow for the joint training of data-rich and data-scarce languages in a single model. This enables data and parameter sharing across languages, which is especially beneficial for the data-scarce languages. However, most state-of-the-art multilingual models require the encoding of language information and therefore are not as flexible or scalable when expanding to newer languages. Language-independent multilingual models help to address this issue, and are also better suited for multicultural societies where several languages are frequently used together (but often rendered with different writing systems). In this paper, we propose a new approach to building a language-agnostic multilingual ASR system which transforms all languages to one writing system through a many-to-one transliteration transducer. Thus, similar sounding acoustics are mapped to a single, canonical target sequence of graphemes, effectively separating the modeling and rendering problems. We show with four Indic languages, namely, Hindi, Bengali, Tamil and Kannada, that the language-agnostic multilingual model achieves up to 10% relative reduction in Word Error Rate (WER) over a language-dependent multilingual model.
A Streaming On-Device End-to-End Model Surpassing Server-Side Conventional Model Quality and Latency
Mar 28, 2020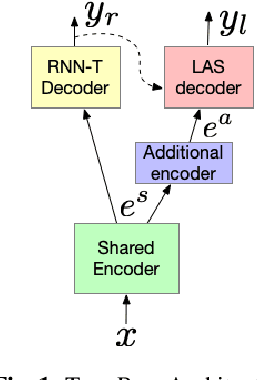
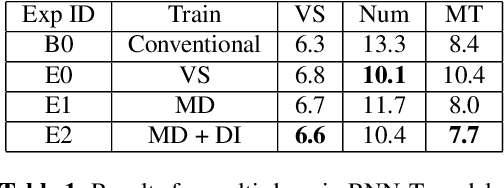
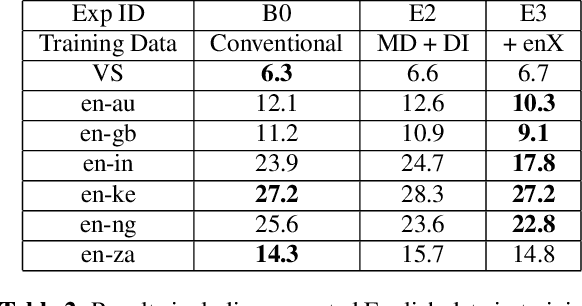
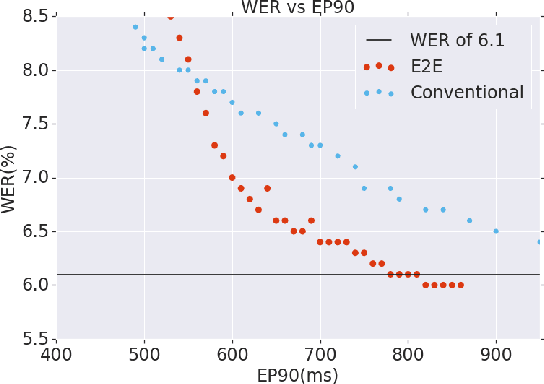
Thus far, end-to-end (E2E) models have not been shown to outperform state-of-the-art conventional models with respect to both quality, i.e., word error rate (WER), and latency, i.e., the time the hypothesis is finalized after the user stops speaking. In this paper, we develop a first-pass Recurrent Neural Network Transducer (RNN-T) model and a second-pass Listen, Attend, Spell (LAS) rescorer that surpasses a conventional model in both quality and latency. On the quality side, we incorporate a large number of utterances across varied domains to increase acoustic diversity and the vocabulary seen by the model. We also train with accented English speech to make the model more robust to different pronunciations. In addition, given the increased amount of training data, we explore a varied learning rate schedule. On the latency front, we explore using the end-of-sentence decision emitted by the RNN-T model to close the microphone, and also introduce various optimizations to improve the speed of LAS rescoring. Overall, we find that RNN-T+LAS offers a better WER and latency tradeoff compared to a conventional model. For example, for the same latency, RNN-T+LAS obtains a 8% relative improvement in WER, while being more than 400-times smaller in model size.
A comparison of end-to-end models for long-form speech recognition
Nov 06, 2019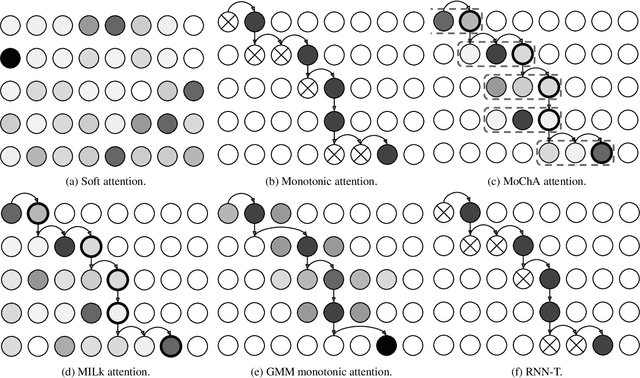

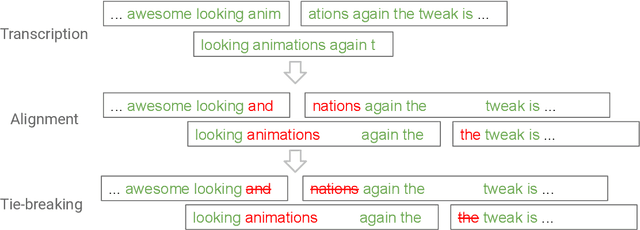
End-to-end automatic speech recognition (ASR) models, including both attention-based models and the recurrent neural network transducer (RNN-T), have shown superior performance compared to conventional systems. However, previous studies have focused primarily on short utterances that typically last for just a few seconds or, at most, a few tens of seconds. Whether such architectures are practical on long utterances that last from minutes to hours remains an open question. In this paper, we both investigate and improve the performance of end-to-end models on long-form transcription. We first present an empirical comparison of different end-to-end models on a real world long-form task and demonstrate that the RNN-T model is much more robust than attention-based systems in this regime. We next explore two improvements to attention-based systems that significantly improve its performance: restricting the attention to be monotonic, and applying a novel decoding algorithm that breaks long utterances into shorter overlapping segments. Combining these two improvements, we show that attention-based end-to-end models can be very competitive to RNN-T on long-form speech recognition.
Large-Scale Multilingual Speech Recognition with a Streaming End-to-End Model
Sep 11, 2019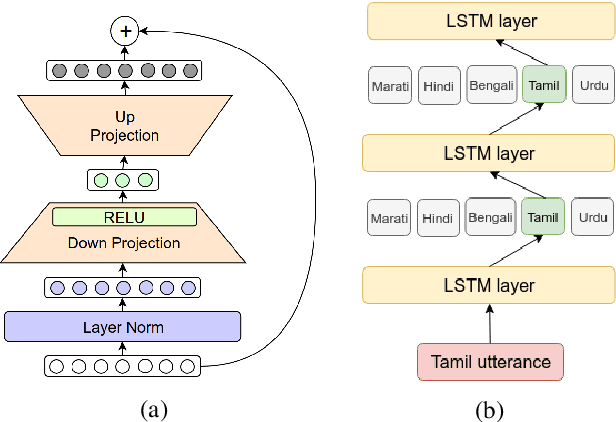
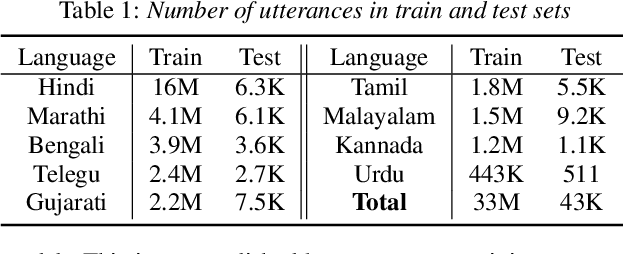
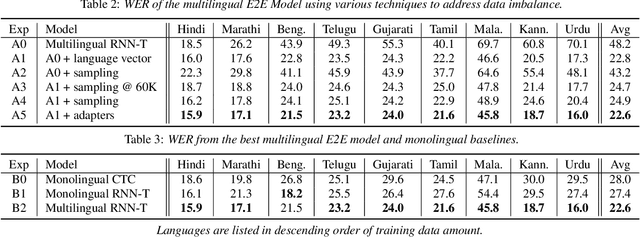
Multilingual end-to-end (E2E) models have shown great promise in expansion of automatic speech recognition (ASR) coverage of the world's languages. They have shown improvement over monolingual systems, and have simplified training and serving by eliminating language-specific acoustic, pronunciation, and language models. This work presents an E2E multilingual system which is equipped to operate in low-latency interactive applications, as well as handle a key challenge of real world data: the imbalance in training data across languages. Using nine Indic languages, we compare a variety of techniques, and find that a combination of conditioning on a language vector and training language-specific adapter layers produces the best model. The resulting E2E multilingual model achieves a lower word error rate (WER) than both monolingual E2E models (eight of nine languages) and monolingual conventional systems (all nine languages).
Extracting Symptoms and their Status from Clinical Conversations
Jun 05, 2019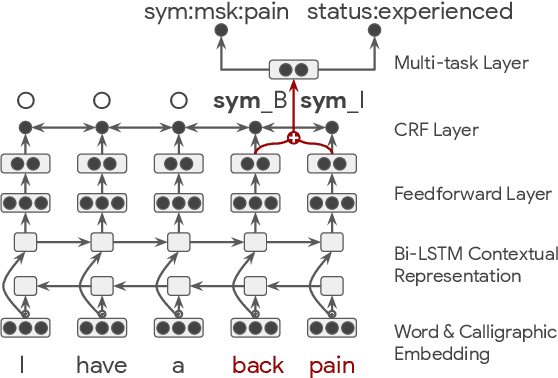
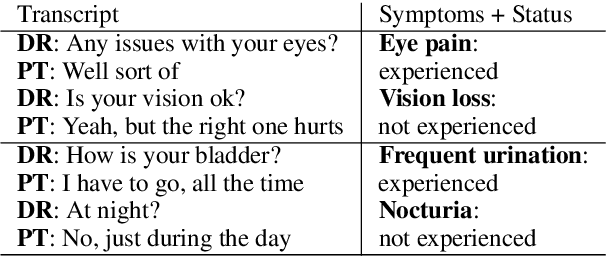
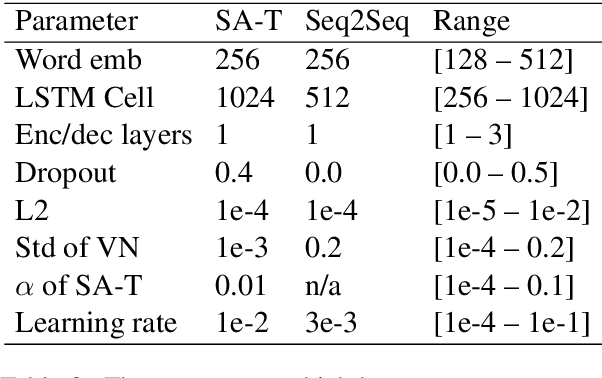
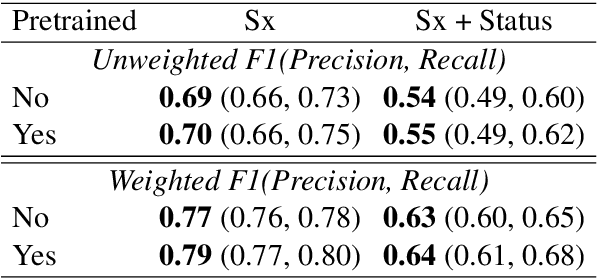
This paper describes novel models tailored for a new application, that of extracting the symptoms mentioned in clinical conversations along with their status. Lack of any publicly available corpus in this privacy-sensitive domain led us to develop our own corpus, consisting of about 3K conversations annotated by professional medical scribes. We propose two novel deep learning approaches to infer the symptom names and their status: (1) a new hierarchical span-attribute tagging (\SAT) model, trained using curriculum learning, and (2) a variant of sequence-to-sequence model which decodes the symptoms and their status from a few speaker turns within a sliding window over the conversation. This task stems from a realistic application of assisting medical providers in capturing symptoms mentioned by patients from their clinical conversations. To reflect this application, we define multiple metrics. From inter-rater agreement, we find that the task is inherently difficult. We conduct comprehensive evaluations on several contrasting conditions and observe that the performance of the models range from an F-score of 0.5 to 0.8 depending on the condition. Our analysis not only reveals the inherent challenges of the task, but also provides useful directions to improve the models.
Lingvo: a Modular and Scalable Framework for Sequence-to-Sequence Modeling
Feb 21, 2019


Lingvo is a Tensorflow framework offering a complete solution for collaborative deep learning research, with a particular focus towards sequence-to-sequence models. Lingvo models are composed of modular building blocks that are flexible and easily extensible, and experiment configurations are centralized and highly customizable. Distributed training and quantized inference are supported directly within the framework, and it contains existing implementations of a large number of utilities, helper functions, and the newest research ideas. Lingvo has been used in collaboration by dozens of researchers in more than 20 papers over the last two years. This document outlines the underlying design of Lingvo and serves as an introduction to the various pieces of the framework, while also offering examples of advanced features that showcase the capabilities of the framework.
Model Unit Exploration for Sequence-to-Sequence Speech Recognition
Feb 05, 2019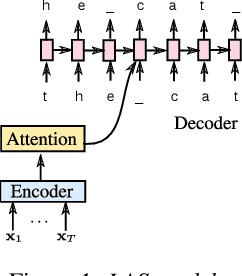
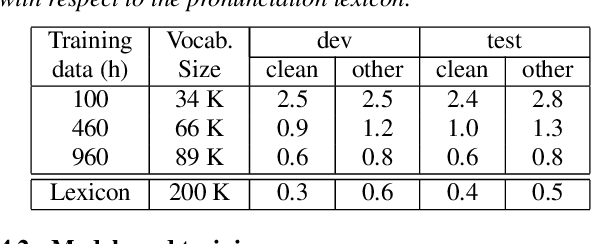
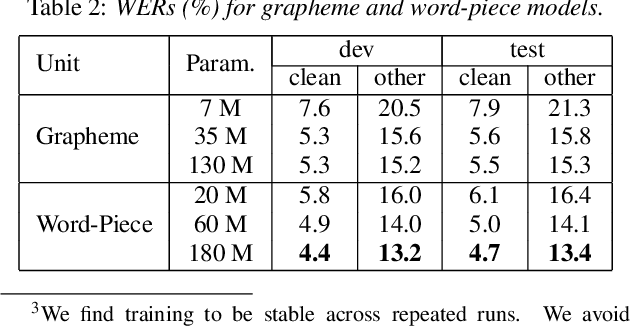
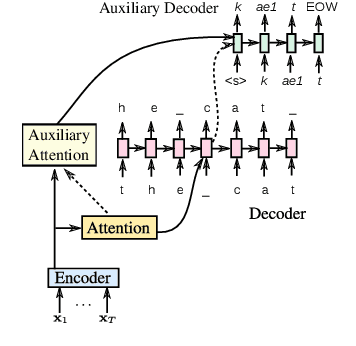
We evaluate attention-based encoder-decoder models along two dimensions: choice of target unit (phoneme, grapheme, and word-piece), and the amount of available training data. We conduct experiments on the LibriSpeech 100hr, 460hr, and 960hr tasks; across all tasks, we find that grapheme or word-piece models consistently outperform phoneme-based models, even though they are evaluated without a lexicon or an external language model. On the 960hr task the word-piece model achieves a word error rate (WER) of 4.7% on the test-clean set and 13.4% on the test-other set, which improves to 3.6% (clean) and 10.3% (other) when decoded with an LSTM LM: the lowest reported numbers using sequence-to-sequence models. We also conduct a detailed analysis of the various models, and investigate their complementarity: we find that we can improve WERs by up to 9% relative by rescoring N-best lists generated from the word-piece model with either the phoneme or the grapheme model. Rescoring an N-best list generated by the phonemic system, however, provides limited improvements. Further analysis shows that the word-piece-based models produce more diverse N-best hypotheses, resulting in lower oracle WERs, than the phonemic system.
Streaming End-to-end Speech Recognition For Mobile Devices
Nov 15, 2018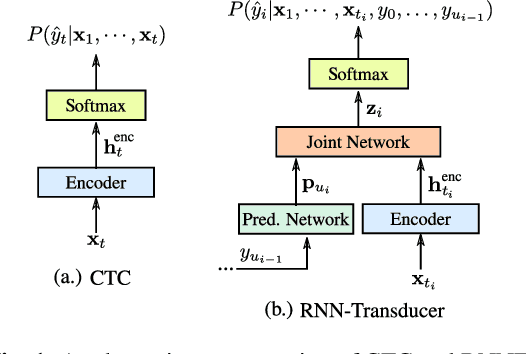
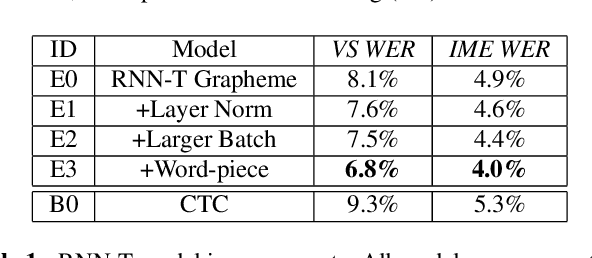
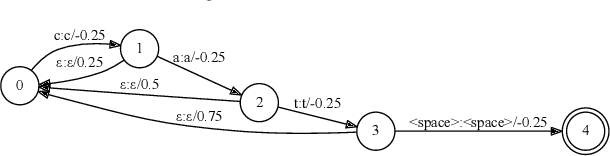
End-to-end (E2E) models, which directly predict output character sequences given input speech, are good candidates for on-device speech recognition. E2E models, however, present numerous challenges: In order to be truly useful, such models must decode speech utterances in a streaming fashion, in real time; they must be robust to the long tail of use cases; they must be able to leverage user-specific context (e.g., contact lists); and above all, they must be extremely accurate. In this work, we describe our efforts at building an E2E speech recognizer using a recurrent neural network transducer. In experimental evaluations, we find that the proposed approach can outperform a conventional CTC-based model in terms of both latency and accuracy in a number of evaluation categories.
Deep context: end-to-end contextual speech recognition
Aug 07, 2018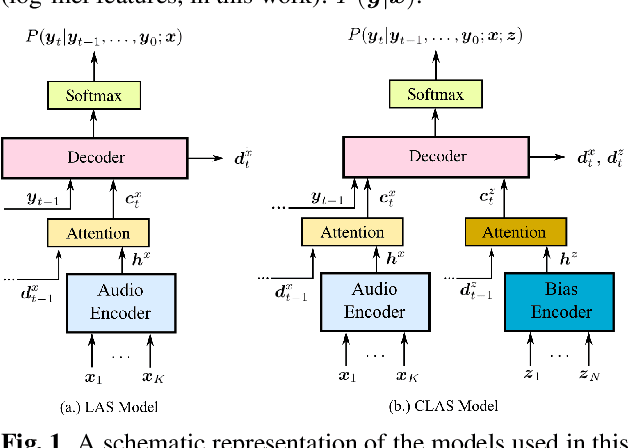
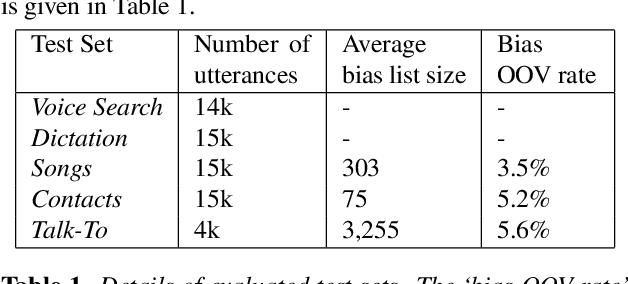
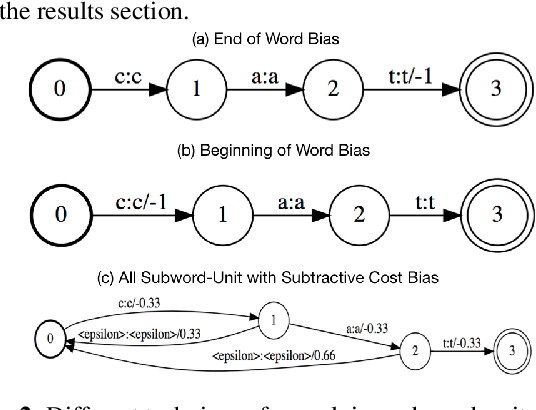
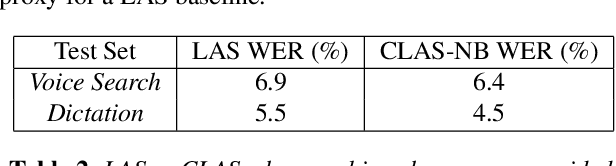
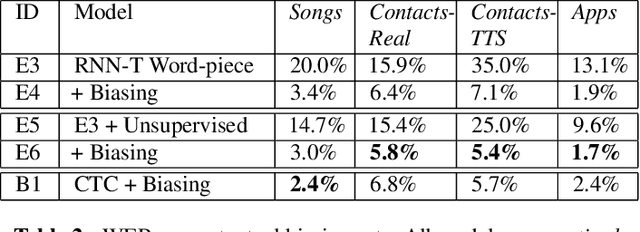
In automatic speech recognition (ASR) what a user says depends on the particular context she is in. Typically, this context is represented as a set of word n-grams. In this work, we present a novel, all-neural, end-to-end (E2E) ASR sys- tem that utilizes such context. Our approach, which we re- fer to as Contextual Listen, Attend and Spell (CLAS) jointly- optimizes the ASR components along with embeddings of the context n-grams. During inference, the CLAS system can be presented with context phrases which might contain out-of- vocabulary (OOV) terms not seen during training. We com- pare our proposed system to a more traditional contextualiza- tion approach, which performs shallow-fusion between inde- pendently trained LAS and contextual n-gram models during beam search. Across a number of tasks, we find that the pro- posed CLAS system outperforms the baseline method by as much as 68% relative WER, indicating the advantage of joint optimization over individually trained components. Index Terms: speech recognition, sequence-to-sequence models, listen attend and spell, LAS, attention, embedded speech recognition.