 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastEmit: Low-latency Streaming ASR with Sequence-level Emission Regularization
Paper and Code
Oct 21, 2020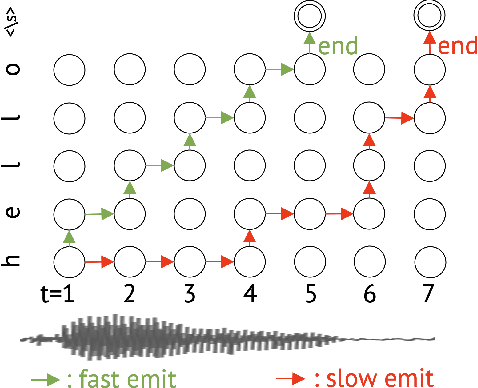
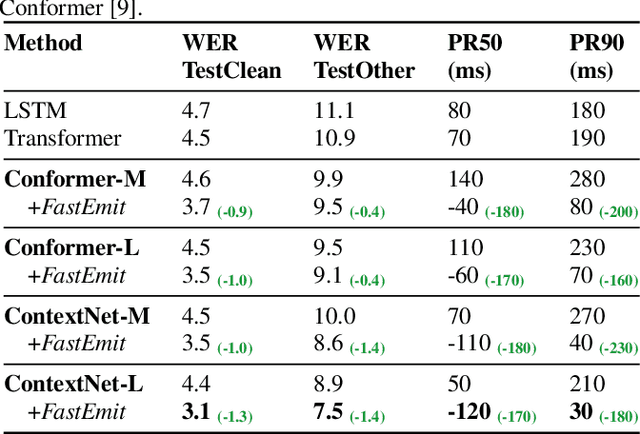

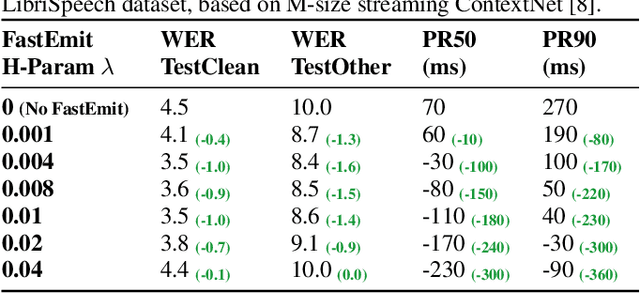
Streaming automatic speech recognition (ASR) aims to emit each hypothesized word as quickly and accurately as possible. However, emitting fast without degrading quality, as measured by word error rate (WER), is highly challenging. Existing approaches including Early and Late Penalties and Constrained Alignments penalize emission delay by manipulating per-token or per-frame probability prediction in sequence transducer models. While being successful in reducing delay, these approaches suffer from significant accuracy regression and also require additional word alignment information from an existing model. In this work, we propose a sequence-level emission regularization method, named FastEmit, that applies latency regularization directly on per-sequence probability in training transducer models, and does not require any alignment. We demonstrate that FastEmit is more suitable to the sequence-level optimization of transducer models for streaming ASR by applying it on various end-to-end streaming ASR networks including RNN-Transducer, Transformer-Transducer, ConvNet-Transducer and Conformer-Transducer. We achieve 150-300 ms latency reduction with significantly better accuracy over previous techniques on a Voice Search test set. FastEmit also improves streaming ASR accuracy from 4.4%/8.9% to 3.1%/7.5% WER, meanwhile reduces 90th percentile latency from 210 ms to only 30 ms on LibriSpeech.