 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoardgameQA: A Dataset for Natural Language Reasoning with Contradictory Information
Jun 13, 2023Automated reasoning with unstructured natural text is a key requirement for many potential applications of NLP and for developing robust AI systems. Recently, Language Models (LMs) have demonstrated complex reasoning capacities even without any finetuning. However, existing evaluation for automated reasoning assumes access to a consistent and coherent set of information over which models reason. When reasoning in the real-world, the available information is frequently inconsistent or contradictory, and therefore models need to be equipped with a strategy to resolve such conflicts when they arise. One widely-applicable way of resolving conflicts is to impose preferences over information sources (e.g., based on source credibility or information recency) and adopt the source with higher preference. In this paper, we formulate the problem of reasoning with contradictory information guided by preferences over sources as the classical problem of defeasible reasoning, and develop a dataset called BoardgameQA for measuring the reasoning capacity of LMs in this setting. BoardgameQA also incorporates reasoning with implicit background knowledge, to better reflect reasoning problems in downstream applications. We benchmark various LMs on BoardgameQA and the results reveal a significant gap in the reasoning capacity of state-of-the-art LMs on this problem, showing that reasoning with conflicting information does not surface out-of-the-box in LMs. While performance can be improved with finetuning, it nevertheless remains poor.
LAMBADA: Backward Chaining for Automated Reasoning in Natural Language
Dec 20, 2022Remarkable progress has been made on automated reasoning with knowledge specified as unstructured, natural text, by using the power of large language models (LMs) coupled with methods such as Chain-of-Thought prompting and Selection-Inference. These techniques search for proofs in the forward direction from axioms to the conclusion, which suffers from a combinatorial explosion of the search space, and thus high failure rates for problems requiring longer chains of reasoning. The classical automated reasoning literature has shown that reasoning in the backward direction (i.e. from the intended conclusion to the set of axioms that support it) is significantly more efficient at proof-finding problems. We import this intuition into the LM setting and develop a Backward Chaining algorithm, which we call LAMBADA, that decomposes reasoning into four sub-modules, each of which can be simply implemented by few-shot prompted LM inference. We show that LAMBADA achieves massive accuracy boosts over state-of-the-art forward reasoning methods on two challenging logical reasoning datasets, particularly when deep and accurate proof chains are required.
Learning Word-Level Confidence For Subword End-to-End ASR
Mar 11, 2021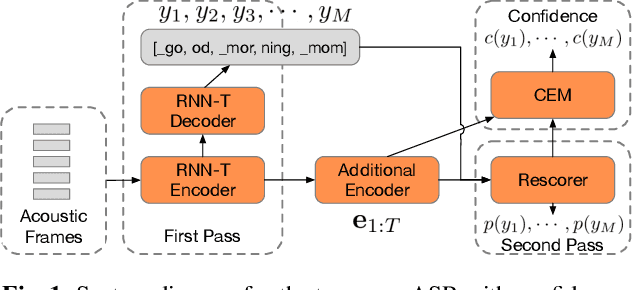

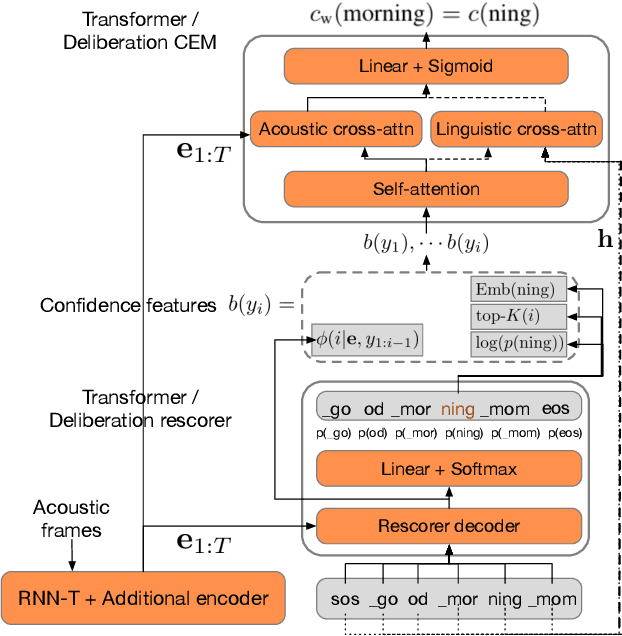
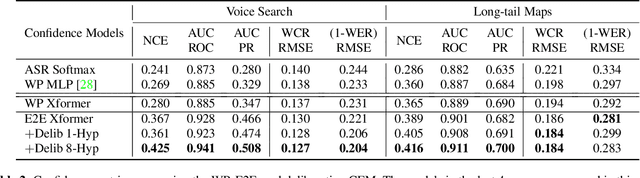
We study the problem of word-level confidence estimation in subword-based end-to-end (E2E) models for automatic speech recognition (ASR). Although prior works have proposed training auxiliary confidence models for ASR systems, they do not extend naturally to systems that operate on word-pieces (WP) as their vocabulary. In particular, ground truth WP correctness labels are needed for training confidence models, but the non-unique tokenization from word to WP causes inaccurate labels to be generated. This paper proposes and studies two confidence models of increasing complexity to solve this problem. The final model uses self-attention to directly learn word-level confidence without needing subword tokenization, and exploits full context features from multiple hypotheses to improve confidence accuracy. Experiments on Voice Search and long-tail test sets show standard metrics (e.g., NCE, AUC, RMSE) improving substantially. The proposed confidence module also enables a model selection approach to combine an on-device E2E model with a hybrid model on the server to address the rare word recognition problem for the E2E model.
Lingvo: a Modular and Scalable Framework for Sequence-to-Sequence Modeling
Feb 21, 2019


Lingvo is a Tensorflow framework offering a complete solution for collaborative deep learning research, with a particular focus towards sequence-to-sequence models. Lingvo models are composed of modular building blocks that are flexible and easily extensible, and experiment configurations are centralized and highly customizable. Distributed training and quantized inference are supported directly within the framework, and it contains existing implementations of a large number of utilities, helper functions, and the newest research ideas. Lingvo has been used in collaboration by dozens of researchers in more than 20 papers over the last two years. This document outlines the underlying design of Lingvo and serves as an introduction to the various pieces of the framework, while also offering examples of advanced features that showcase the capabilities of the framework.
Streaming End-to-end Speech Recognition For Mobile Devices
Nov 15, 2018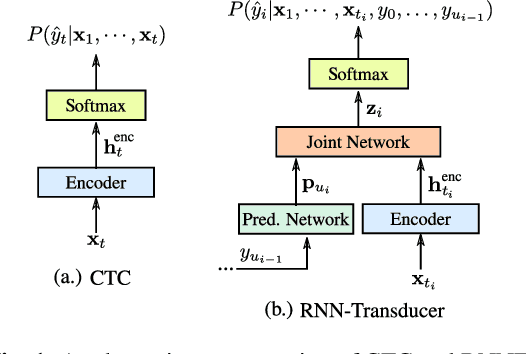
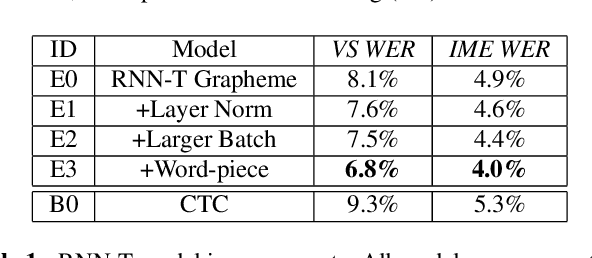
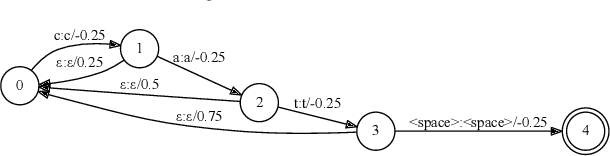
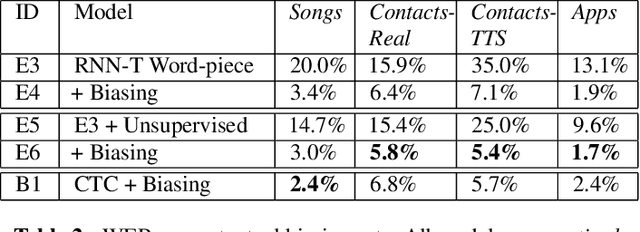
End-to-end (E2E) models, which directly predict output character sequences given input speech, are good candidates for on-device speech recognition. E2E models, however, present numerous challenges: In order to be truly useful, such models must decode speech utterances in a streaming fashion, in real time; they must be robust to the long tail of use cases; they must be able to leverage user-specific context (e.g., contact lists); and above all, they must be extremely accurate. In this work, we describe our efforts at building an E2E speech recognizer using a recurrent neural network transducer. In experimental evaluations, we find that the proposed approach can outperform a conventional CTC-based model in terms of both latency and accuracy in a number of evaluation categories.