 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSPMD: General and Scalable Parallelization for ML Computation Graphs
May 10, 2021

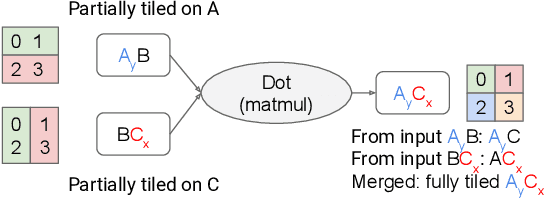
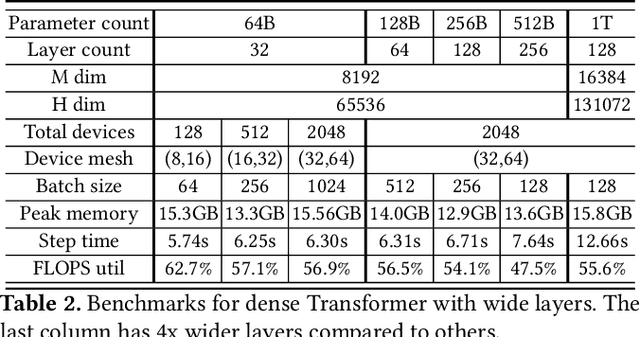
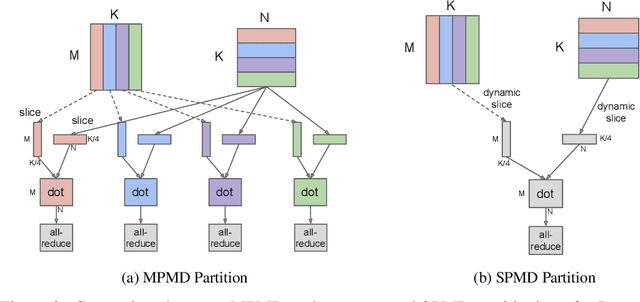
We present GSPMD, an automatic, compiler-based parallelization system for common machine learning computation graphs. It allows users to write programs in the same way as for a single device, then give hints through a few annotations on how to distribute tensors, based on which GSPMD will parallelize the computation. Its representation of partitioning is simple yet general, allowing it to express different or mixed paradigms of parallelism on a wide variety of models. GSPMD infers the partitioning for every operator in the graph based on limited user annotations, making it convenient to scale up existing single-device programs. It solves several technical challenges for production usage, such as static shape constraints, uneven partitioning, exchange of halo data, and nested operator partitioning. These techniques allow GSPMD to achieve 50% to 62% compute utilization on 128 to 2048 Cloud TPUv3 cores for models with up to one trillion parameters. GSPMD produces a single program for all devices, which adjusts its behavior based on a run-time partition ID, and uses collective operators for cross-device communication. This property allows the system itself to be scalable: the compilation time stays constant with increasing number of devices.
Exploring the limits of Concurrency in ML Training on Google TPUs
Nov 07, 2020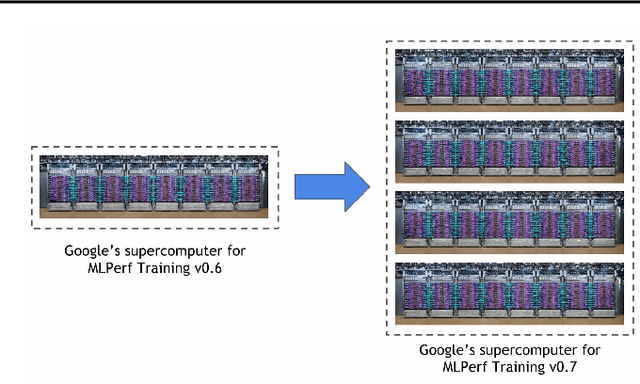
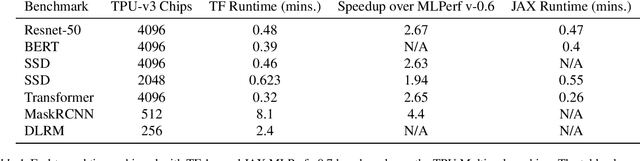
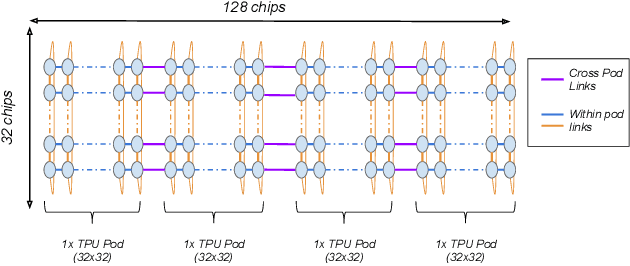
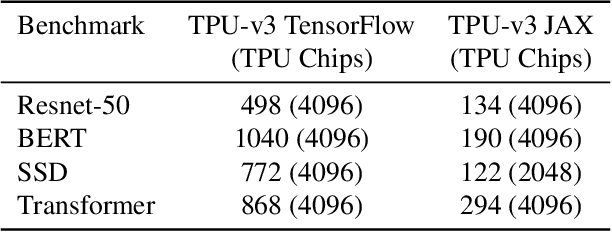
Recent results in language understanding using neural networks have required training hardware of unprecedentedscale, with thousands of chips cooperating on a single training run. This paper presents techniques to scaleML models on the Google TPU Multipod, a mesh with 4096 TPU-v3 chips. We discuss model parallelism toovercome scaling limitations from the fixed batch size in data parallelism, communication/collective optimizations,distributed evaluation of training metrics, and host input processing scaling optimizations. These techniques aredemonstrated in both the TensorFlow and JAX programming frameworks. We also present performance resultsfrom the recent Google submission to the MLPerf-v0.7 benchmark contest, achieving record training times from16 to 28 seconds in four MLPerf models on the Google TPU-v3 Multipod machine.
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Jun 30, 2020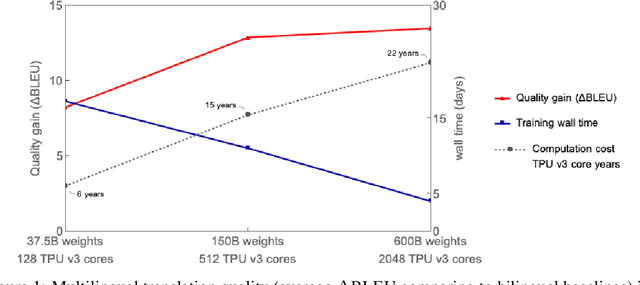
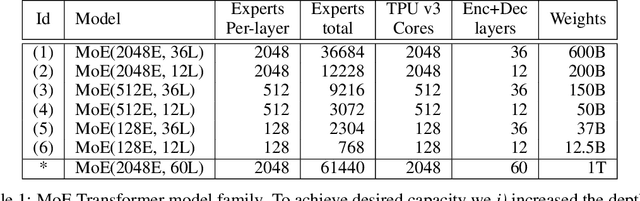
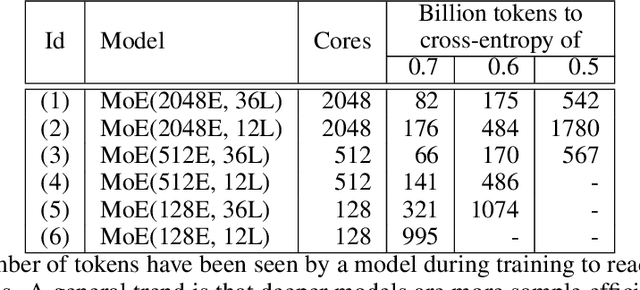
Neural network scaling has been critical for improving the model quality in many real-world machine learning applications with vast amounts of training data and compute. Although this trend of scaling is affirmed to be a sure-fire approach for better model quality, there are challenges on the path such as the computation cost, ease of programming, and efficient implementation on parallel devices. GShard is a module composed of a set of lightweight annotation APIs and an extension to the XLA compiler. It provides an elegant way to express a wide range of parallel computation patterns with minimal changes to the existing model code. GShard enabled us to scale up multilingual neural machine translation Transformer model with Sparsely-Gated Mixture-of-Experts beyond 600 billion parameters using automatic sharding. We demonstrate that such a giant model can efficiently be trained on 2048 TPU v3 accelerators in 4 days to achieve far superior quality for translation from 100 languages to English compared to the prior art.
Automatic Cross-Replica Sharding of Weight Update in Data-Parallel Training
Apr 28, 2020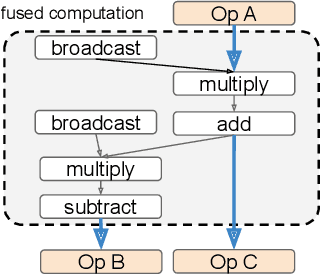
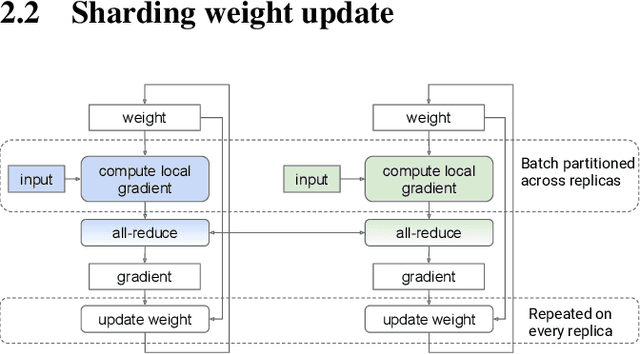
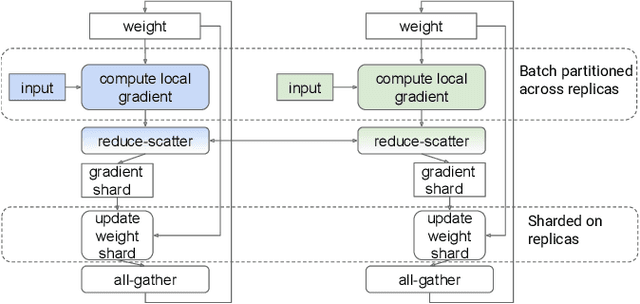
In data-parallel synchronous training of deep neural networks, different devices (replicas) run the same program with different partitions of the training batch, but weight update computation is repeated on all replicas, because the weights do not have a batch dimension to partition. This can be a bottleneck for performance and scalability in typical language models with large weights, and models with small per-replica batch size which is typical in large-scale training. This paper presents an approach to automatically shard the weight update computation across replicas with efficient communication primitives and data formatting, using static analysis and transformations on the training computation graph. We show this technique achieves substantial speedups on typical image and language models on Cloud TPUs, requiring no change to model code. This technique helps close the gap between traditionally expensive (ADAM) and cheap (SGD) optimizers, as they will only take a small part of training step time and have similar peak memory usage. It helped us to achieve state-of-the-art training performance in Google's MLPerf 0.6 submission.
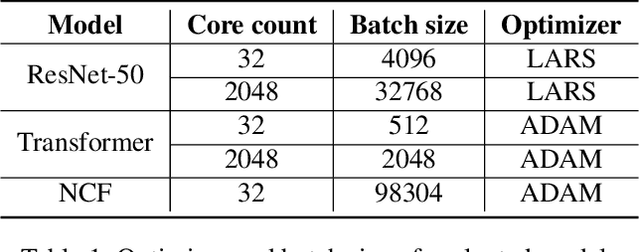
Scale MLPerf-0.6 models on Google TPU-v3 Pods
Oct 02, 2019
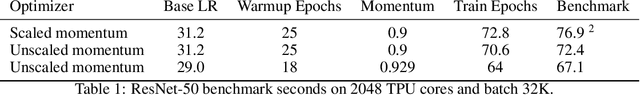

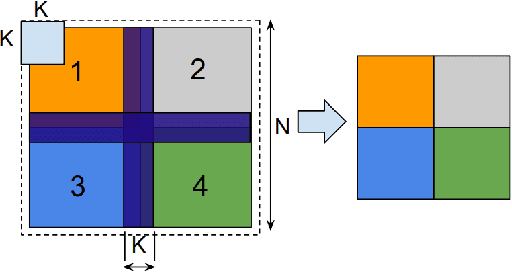
The recent submission of Google TPU-v3 Pods to the industry wide MLPerf v0.6 training benchmark demonstrates the scalability of a suite of industry relevant ML models. MLPerf defines a suite of models, datasets and rules to follow when benchmarking to ensure results are comparable across hardware, frameworks and companies. Using this suite of models, we discuss the optimizations and techniques including choice of optimizer, spatial partitioning and weight update sharding necessary to scale to 1024 TPU chips. Furthermore, we identify properties of models that make scaling them challenging, such as limited data parallelism and unscaled weights. These optimizations contribute to record performance in transformer, Resnet-50 and SSD in the Google MLPerf-0.6 submission.
Lingvo: a Modular and Scalable Framework for Sequence-to-Sequence Modeling
Feb 21, 2019


Lingvo is a Tensorflow framework offering a complete solution for collaborative deep learning research, with a particular focus towards sequence-to-sequence models. Lingvo models are composed of modular building blocks that are flexible and easily extensible, and experiment configurations are centralized and highly customizable. Distributed training and quantized inference are supported directly within the framework, and it contains existing implementations of a large number of utilities, helper functions, and the newest research ideas. Lingvo has been used in collaboration by dozens of researchers in more than 20 papers over the last two years. This document outlines the underlying design of Lingvo and serves as an introduction to the various pieces of the framework, while also offering examples of advanced features that showcase the capabilities of the framework.
GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism
Dec 12, 2018



GPipe is a scalable pipeline parallelism library that enables learning of giant deep neural networks. It partitions network layers across accelerators and pipelines execution to achieve high hardware utilization. It leverages recomputation to minimize activation memory usage. For example, using partitions over 8 accelerators, it is able to train networks that are 25x larger, demonstrating its scalability. It also guarantees that the computed gradients remain consistent regardless of the number of partitions. It achieves an almost linear speed up without any changes in the model parameters: when using 4x more accelerators, training the same model is up to 3.5x faster. We train a 557 million parameters AmoebaNet model on ImageNet and achieve a new state-of-the-art 84.3% top-1 / 97.0% top-5 accuracy on ImageNet 2012 dataset. Finally, we use this learned model to finetune multiple popular image classification datasets and obtain competitive results, including pushing the CIFAR-10 accuracy to 99% and CIFAR-100 accuracy to 91.3%.
Mesh-TensorFlow: Deep Learning for Supercomputers
Nov 05, 2018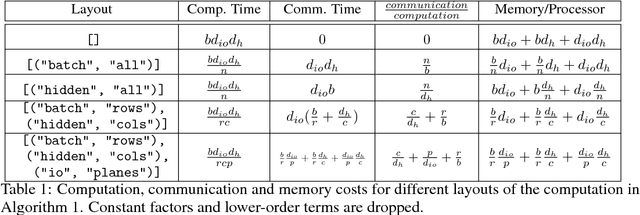
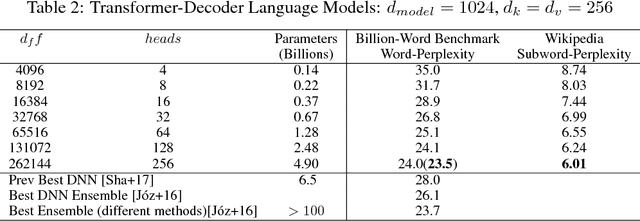
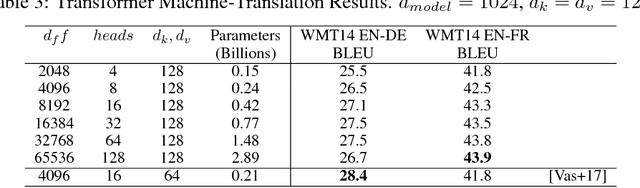
Batch-splitting (data-parallelism) is the dominant distributed Deep Neural Network (DNN) training strategy, due to its universal applicability and its amenability to Single-Program-Multiple-Data (SPMD) programming. However, batch-splitting suffers from problems including the inability to train very large models (due to memory constraints), high latency, and inefficiency at small batch sizes. All of these can be solved by more general distribution strategies (model-parallelism). Unfortunately, efficient model-parallel algorithms tend to be complicated to discover, describe, and to implement, particularly on large clusters. We introduce Mesh-TensorFlow, a language for specifying a general class of distributed tensor computations. Where data-parallelism can be viewed as splitting tensors and operations along the "batch" dimension, in Mesh-TensorFlow, the user can specify any tensor-dimensions to be split across any dimensions of a multi-dimensional mesh of processors. A Mesh-TensorFlow graph compiles into a SPMD program consisting of parallel operations coupled with collective communication primitives such as Allreduce. We use Mesh-TensorFlow to implement an efficient data-parallel, model-parallel version of the Transformer sequence-to-sequence model. Using TPU meshes of up to 512 cores, we train Transformer models with up to 5 billion parameters, surpassing state of the art results on WMT'14 English-to-French translation task and the one-billion-word language modeling benchmark. Mesh-Tensorflow is available at https://github.com/tensorflow/mesh .