 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Rescoring with Transformer for Streaming On-Device Speech Recognition
Paper and Code
Sep 02, 2020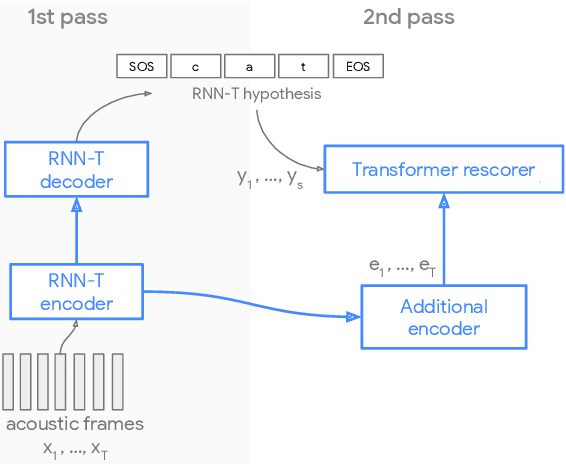
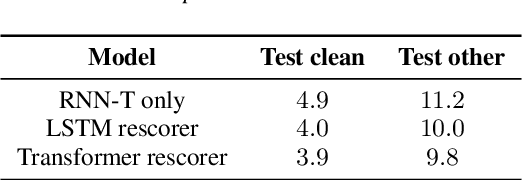
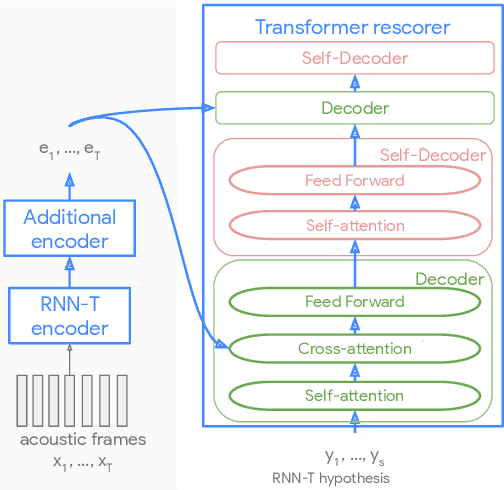
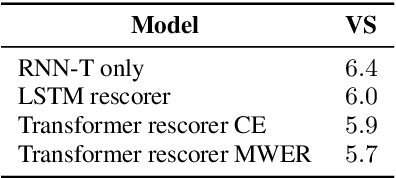
Recent advances of end-to-end models have outperformed conventional models through employing a two-pass model. The two-pass model provides better speed-quality trade-offs for on-device speech recognition, where a 1st-pass model generates hypotheses in a streaming fashion, and a 2nd-pass model re-scores the hypotheses with full audio sequence context. The 2nd-pass model plays a key role in the quality improvement of the end-to-end model to surpass the conventional model. One main challenge of the two-pass model is the computation latency introduced by the 2nd-pass model. Specifically, the original design of the two-pass model uses LSTMs for the 2nd-pass model, which are subject to long latency as they are constrained by the recurrent nature and have to run inference sequentially. In this work we explore replacing the LSTM layers in the 2nd-pass rescorer with Transformer layers, which can process the entire hypothesis sequences in parallel and can therefore utilize the on-device computation resources more efficiently. Compared with an LSTM-based baseline, our proposed Transformer rescorer achieves more than 50% latency reduction with quality improvement.