 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale Language Model Rescoring on Long-form Data
Jun 13, 2023



In this work, we study the impact of Large-scale Language Models (LLM) on Automated Speech Recognition (ASR) of YouTube videos, which we use as a source for long-form ASR. We demonstrate up to 8\% relative reduction in Word Error Eate (WER) on US English (en-us) and code-switched Indian English (en-in) long-form ASR test sets and a reduction of up to 30\% relative on Salient Term Error Rate (STER) over a strong first-pass baseline that uses a maximum-entropy based language model. Improved lattice processing that results in a lattice with a proper (non-tree) digraph topology and carrying context from the 1-best hypothesis of the previous segment(s) results in significant wins in rescoring with LLMs. We also find that the gains in performance from the combination of LLMs trained on vast quantities of available data (such as C4) and conventional neural LMs is additive and significantly outperforms a strong first-pass baseline with a maximum entropy LM.
* 5 pages, accepted in ICASSP 2023
Alignment Entropy Regularization
Dec 22, 2022



Existing training criteria in automatic speech recognition(ASR) permit the model to freely explore more than one time alignments between the feature and label sequences. In this paper, we use entropy to measure a model's uncertainty, i.e. how it chooses to distribute the probability mass over the set of allowed alignments. Furthermore, we evaluate the effect of entropy regularization in encouraging the model to distribute the probability mass only on a smaller subset of allowed alignments. Experiments show that entropy regularization enables a much simpler decoding method without sacrificing word error rate, and provides better time alignment quality.
E2E Segmentation in a Two-Pass Cascaded Encoder ASR Model
Nov 28, 2022



We explore unifying a neural segmenter with two-pass cascaded encoder ASR into a single model. A key challenge is allowing the segmenter (which runs in real-time, synchronously with the decoder) to finalize the 2nd pass (which runs 900 ms behind real-time) without introducing user-perceived latency or deletion errors during inference. We propose a design where the neural segmenter is integrated with the causal 1st pass decoder to emit a end-of-segment (EOS) signal in real-time. The EOS signal is then used to finalize the non-causal 2nd pass. We experiment with different ways to finalize the 2nd pass, and find that a novel dummy frame injection strategy allows for simultaneous high quality 2nd pass results and low finalization latency. On a real-world long-form captioning task (YouTube), we achieve 2.4% relative WER and 140 ms EOS latency gains over a baseline VAD-based segmenter with the same cascaded encoder.
Global Normalization for Streaming Speech Recognition in a Modular Framework
May 26, 2022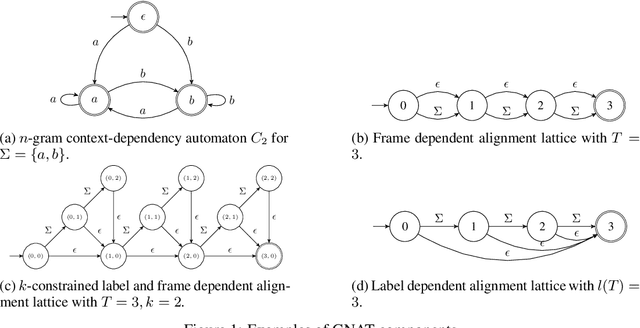
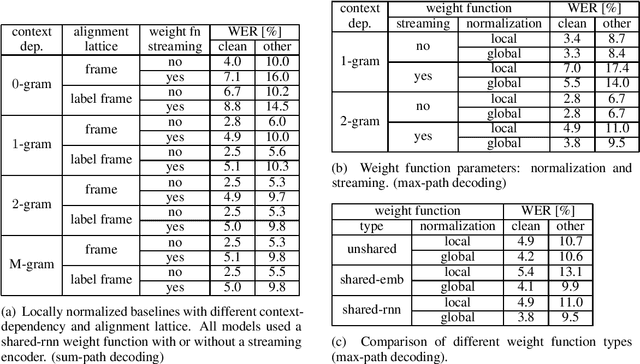
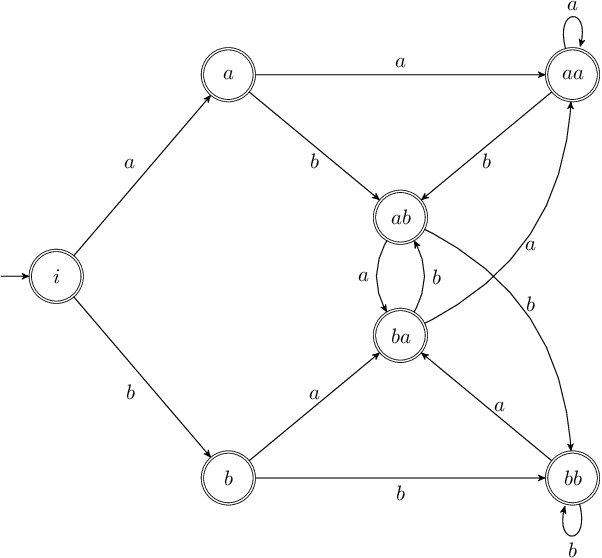
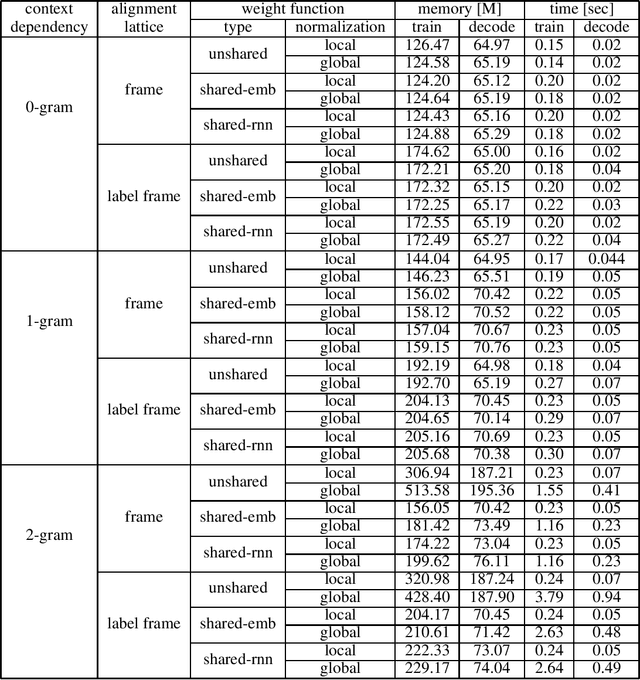
We introduce the Globally Normalized Autoregressive Transducer (GNAT) for addressing the label bias problem in streaming speech recognition. Our solution admits a tractable exact computation of the denominator for the sequence-level normalization. Through theoretical and empirical results, we demonstrate that by switching to a globally normalized model, the word error rate gap between streaming and non-streaming speech-recognition models can be greatly reduced (by more than 50\% on the Librispeech dataset). This model is developed in a modular framework which encompasses all the common neural speech recognition models. The modularity of this framework enables controlled comparison of modelling choices and creation of new models.
E2E Segmenter: Joint Segmenting and Decoding for Long-Form ASR
Apr 22, 2022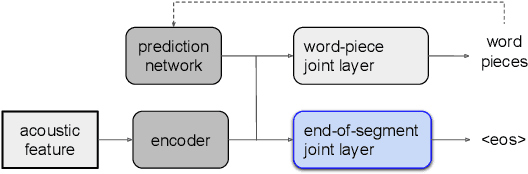
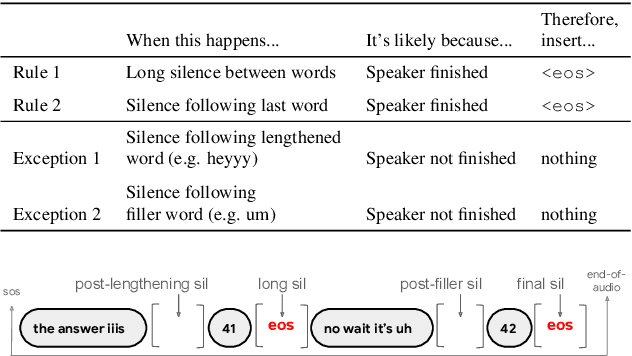
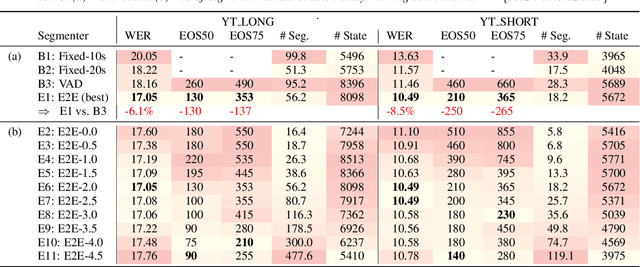
Improving the performance of end-to-end ASR models on long utterances ranging from minutes to hours in length is an ongoing challenge in speech recognition. A common solution is to segment the audio in advance using a separate voice activity detector (VAD) that decides segment boundary locations based purely on acoustic speech/non-speech information. VAD segmenters, however, may be sub-optimal for real-world speech where, e.g., a complete sentence that should be taken as a whole may contain hesitations in the middle ("set an alarm for... 5 o'clock"). We propose to replace the VAD with an end-to-end ASR model capable of predicting segment boundaries in a streaming fashion, allowing the segmentation decision to be conditioned not only on better acoustic features but also on semantic features from the decoded text with negligible extra computation. In experiments on real world long-form audio (YouTube) with lengths of up to 30 minutes, we demonstrate 8.5% relative WER improvement and 250 ms reduction in median end-of-segment latency compared to the VAD segmenter baseline on a state-of-the-art Conformer RNN-T model.
Improving Rare Word Recognition with LM-aware MWER Training
Apr 15, 2022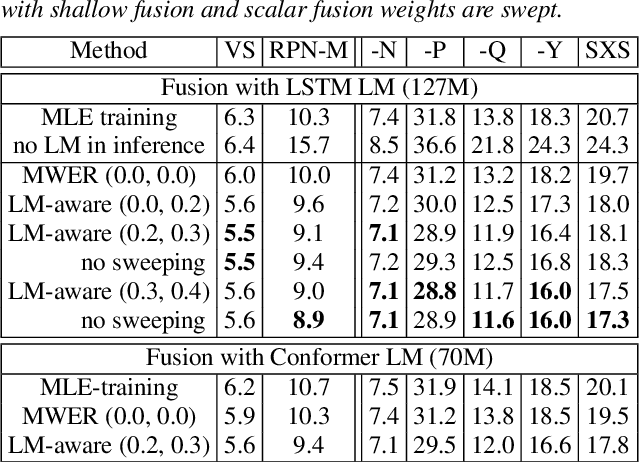
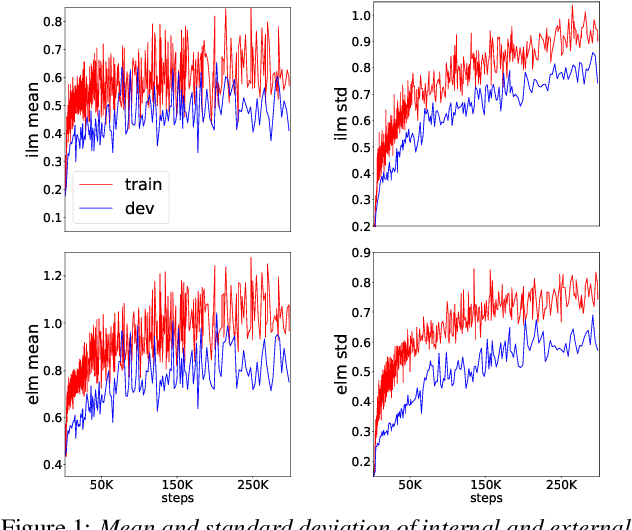

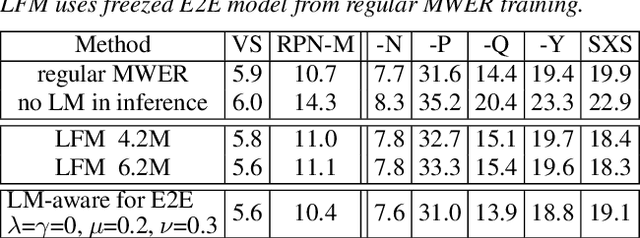
Language models (LMs) significantly improve the recognition accuracy of end-to-end (E2E) models on words rarely seen during training, when used in either the shallow fusion or the rescoring setups. In this work, we introduce LMs in the learning of hybrid autoregressive transducer (HAT) models in the discriminative training framework, to mitigate the training versus inference gap regarding the use of LMs. For the shallow fusion setup, we use LMs during both hypotheses generation and loss computation, and the LM-aware MWER-trained model achieves 10\% relative improvement over the model trained with standard MWER on voice search test sets containing rare words. For the rescoring setup, we learn a small neural module to generate per-token fusion weights in a data-dependent manner. This model achieves the same rescoring WER as regular MWER-trained model, but without the need for sweeping fusion weights.
Handling Compounding in Mobile Keyboard Input
Jan 17, 2022This paper proposes a framework to improve the typing experience of mobile users in morphologically rich languages. Smartphone keyboards typically support features such as input decoding, corrections and predictions that all rely on language models. For latency reasons, these operations happen on device, so the models are of limited size and cannot easily cover all the words needed by users for their daily tasks, especially in morphologically rich languages. In particular, the compounding nature of Germanic languages makes their vocabulary virtually infinite. Similarly, heavily inflecting and agglutinative languages (e.g. Slavic, Turkic or Finno-Ugric languages) tend to have much larger vocabularies than morphologically simpler languages, such as English or Mandarin. We propose to model such languages with automatically selected subword units annotated with what we call binding types, allowing the decoder to know when to bind subword units into words. We show that this method brings around 20% word error rate reduction in a variety of compounding languages. This is more than twice the improvement we previously obtained with a more basic approach, also described in the paper.
Lookup-Table Recurrent Language Models for Long Tail Speech Recognition
Apr 09, 2021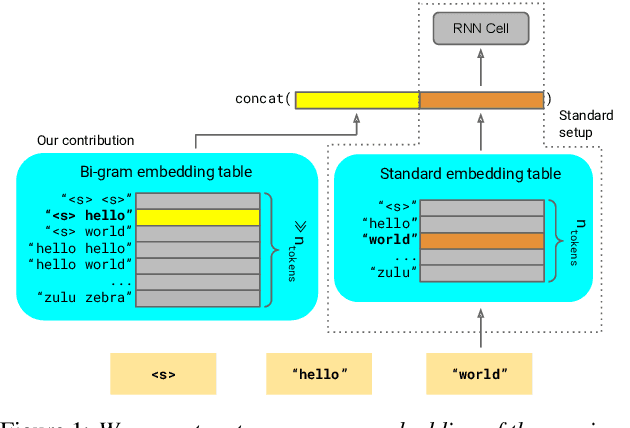
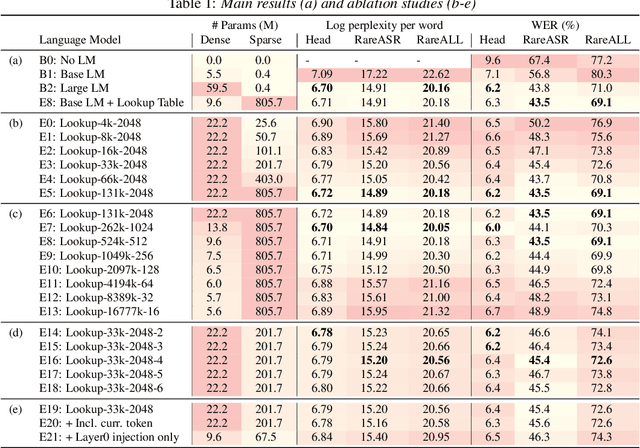
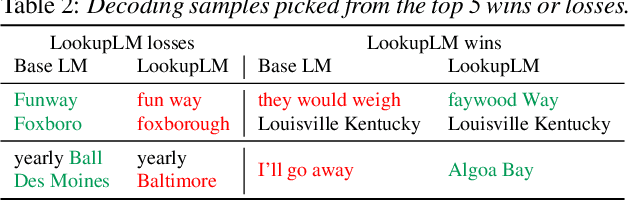

We introduce Lookup-Table Language Models (LookupLM), a method for scaling up the size of RNN language models with only a constant increase in the floating point operations, by increasing the expressivity of the embedding table. In particular, we instantiate an (additional) embedding table which embeds the previous n-gram token sequence, rather than a single token. This allows the embedding table to be scaled up arbitrarily -- with a commensurate increase in performance -- without changing the token vocabulary. Since embeddings are sparsely retrieved from the table via a lookup; increasing the size of the table adds neither extra operations to each forward pass nor extra parameters that need to be stored on limited GPU/TPU memory. We explore scaling n-gram embedding tables up to nearly a billion parameters. When trained on a 3-billion sentence corpus, we find that LookupLM improves long tail log perplexity by 2.44 and long tail WER by 23.4% on a downstream speech recognition task over a standard RNN language model baseline, an improvement comparable to a scaling up the baseline by 6.2x the number of floating point operations.
Less Is More: Improved RNN-T Decoding Using Limited Label Context and Path Merging
Dec 12, 2020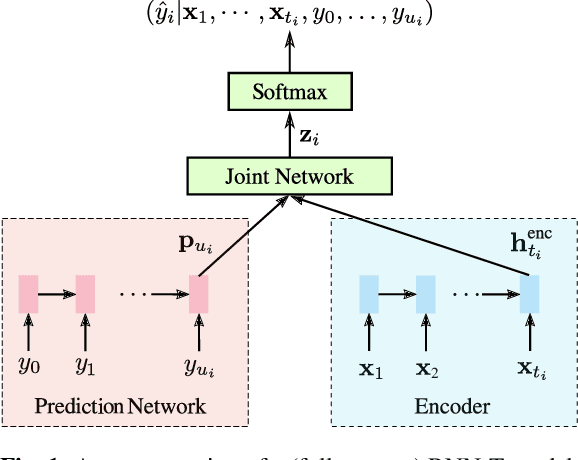
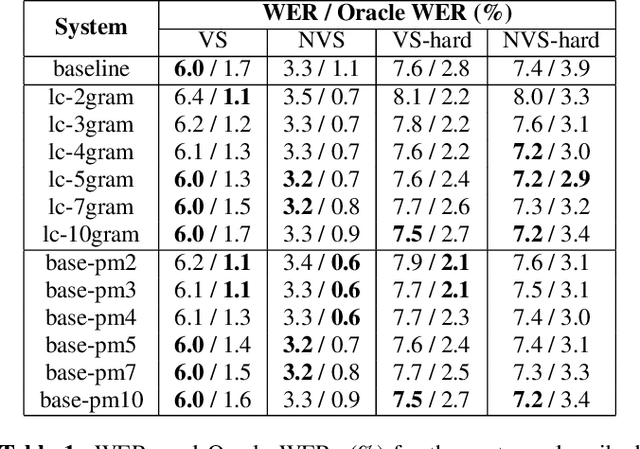
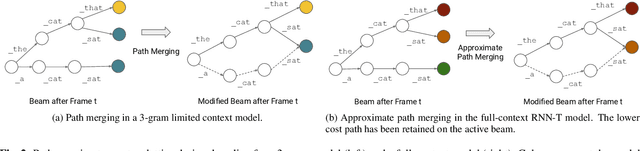
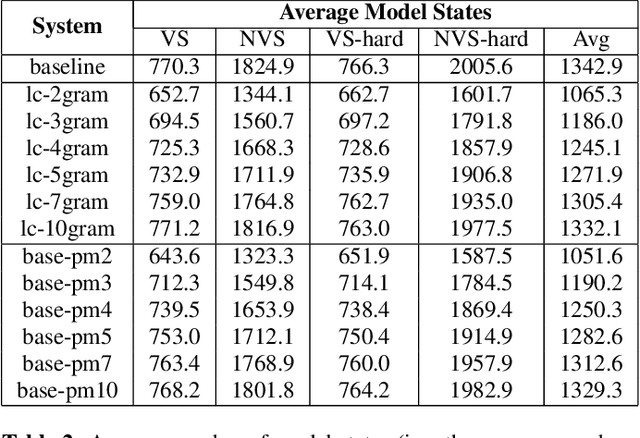
End-to-end models that condition the output label sequence on all previously predicted labels have emerged as popular alternatives to conventional systems for automatic speech recognition (ASR). Since unique label histories correspond to distinct models states, such models are decoded using an approximate beam-search process which produces a tree of hypotheses. In this work, we study the influence of the amount of label context on the model's accuracy, and its impact on the efficiency of the decoding process. We find that we can limit the context of the recurrent neural network transducer (RNN-T) during training to just four previous word-piece labels, without degrading word error rate (WER) relative to the full-context baseline. Limiting context also provides opportunities to improve the efficiency of the beam-search process during decoding by removing redundant paths from the active beam, and instead retaining them in the final lattice. This path-merging scheme can also be applied when decoding the baseline full-context model through an approximation. Overall, we find that the proposed path-merging scheme is extremely effective allowing us to improve oracle WERs by up to 36% over the baseline, while simultaneously reducing the number of model evaluations by up to 5.3% without any degradation in WER.
A Streaming On-Device End-to-End Model Surpassing Server-Side Conventional Model Quality and Latency
Mar 28, 2020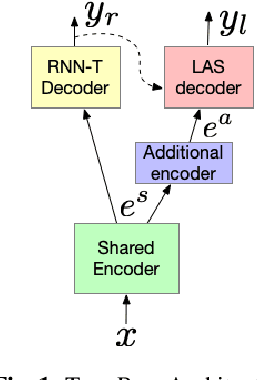
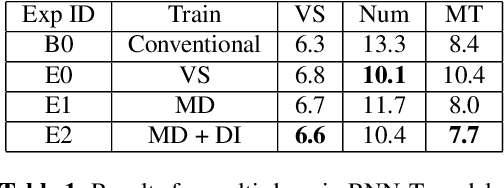
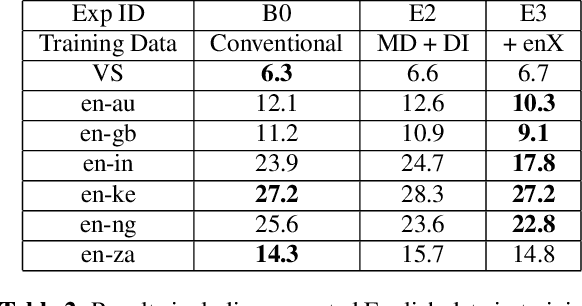
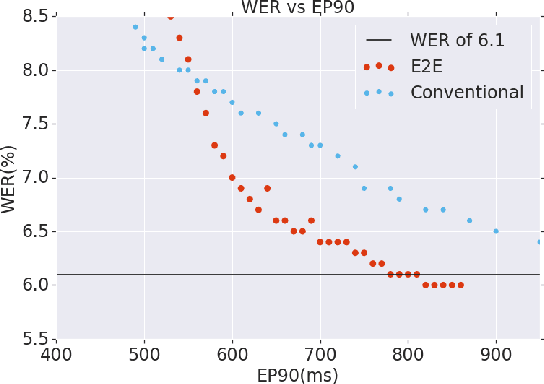
Thus far, end-to-end (E2E) models have not been shown to outperform state-of-the-art conventional models with respect to both quality, i.e., word error rate (WER), and latency, i.e., the time the hypothesis is finalized after the user stops speaking. In this paper, we develop a first-pass Recurrent Neural Network Transducer (RNN-T) model and a second-pass Listen, Attend, Spell (LAS) rescorer that surpasses a conventional model in both quality and latency. On the quality side, we incorporate a large number of utterances across varied domains to increase acoustic diversity and the vocabulary seen by the model. We also train with accented English speech to make the model more robust to different pronunciations. In addition, given the increased amount of training data, we explore a varied learning rate schedule. On the latency front, we explore using the end-of-sentence decision emitted by the RNN-T model to close the microphone, and also introduce various optimizations to improve the speed of LAS rescoring. Overall, we find that RNN-T+LAS offers a better WER and latency tradeoff compared to a conventional model. For example, for the same latency, RNN-T+LAS obtains a 8% relative improvement in WER, while being more than 400-times smaller in model size.